MIT6.824
思维导图
Lecture01 - Introduce
MapReduce论文
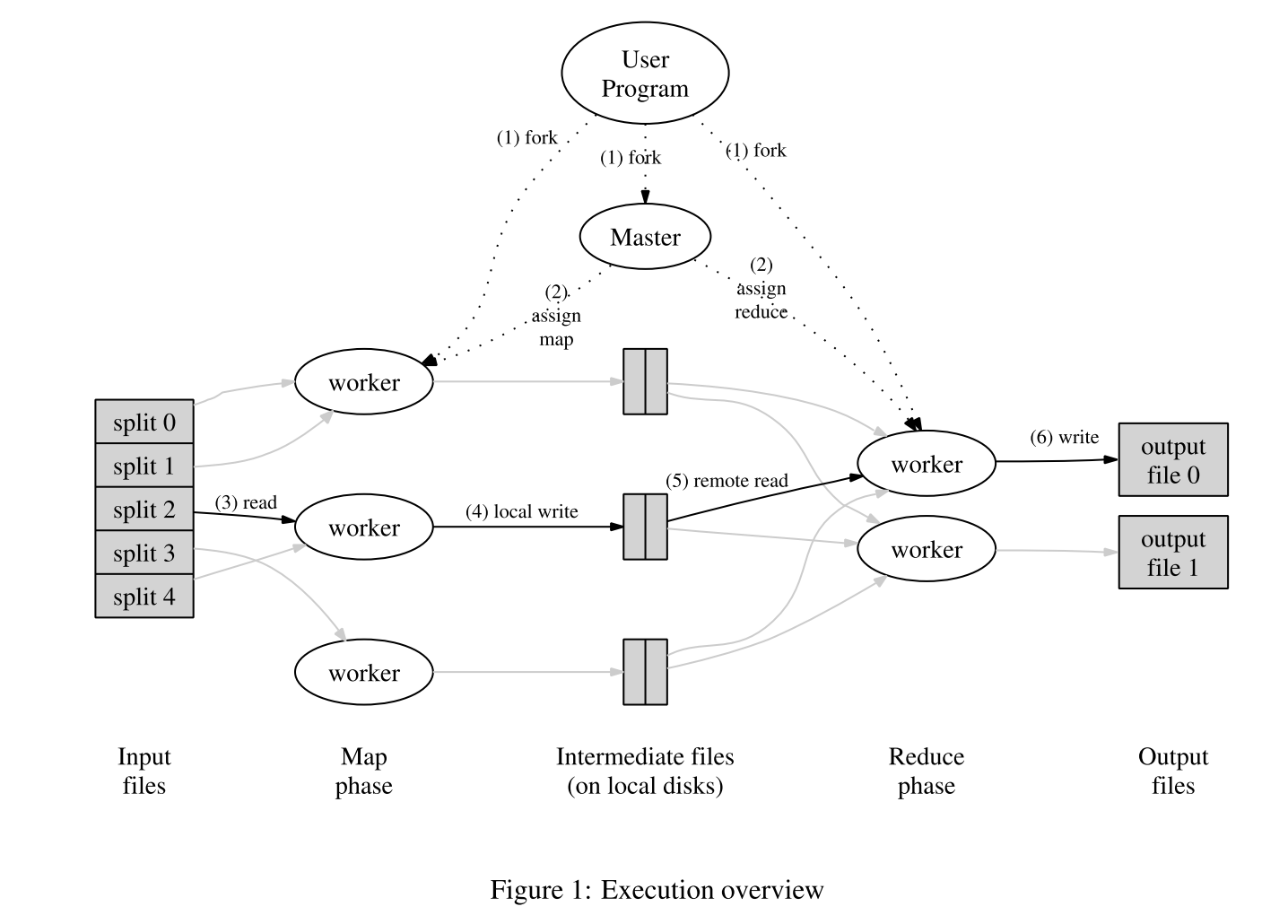
过程:
- 将用户输入的文件分成
M块,每块大小为16MB-64MB(可由用户指定)。 - 由Master节点分配工作给其他Worker节点,包括
M个map任务和R个reduce任务。 - 被分配了map任务的节点解析数据,生成<key,value>然后放入
内存缓冲区。 - 被缓冲的键值对周期性地写入磁盘,然后被划分为
R个块(Hash(key) mod R),他们在磁盘上的位置被发送给Master,然后Master转发给Worker节点进行reduce任务。 - 当节点收到master关于这些位置的通知时,他会使用RPC读取磁盘中的数据,当读取完所有中间数据时,进行
排序操作来保证相同的键组合在一起。 - Reduce函数对已排序的中间数据进行迭代,其输出附加到Reduce分区的output文件中。
- 当
M个map和R个reduce任务运行完毕后,返回至用户代码,整个过程结束。
数据结构
1 | Task: |
Lecture02 - Infrastructure: RPC and threads
Why Go?
- 强大的多线程
- 便捷的RPC
- 类型安全
- 内存安全(垃圾回收机制)
- 简单
Why threads?
- 并发在分布式系统中的必要性
- 利用CPU的多核性能
- 便利性
- I/O并发
挑战性:
- 共享数据:加锁(sync.Mutex或避免共享可变数据)
- 线程之间的协调
- 死锁:锁机制或通信
Go语言并发编程
【并发编程】WaitGroup 基本用法和如何实现以及常见错误-CSDN博客
Lecture03 - GFS
GFS论文
介绍
用于大型分布式数据密集型应用的可伸缩分布式文件系统。
- 组件的失败和错误是非常常见的。因此持续的监控,错误检测,容错和自动恢复是必须的
- 文件通常是巨大的,需要重新设计I/O操作和块大小。
- 文件访问模式,顺序访问。需要优化追加写入和原子性。
- 放宽一致性和原子追加操作
设计
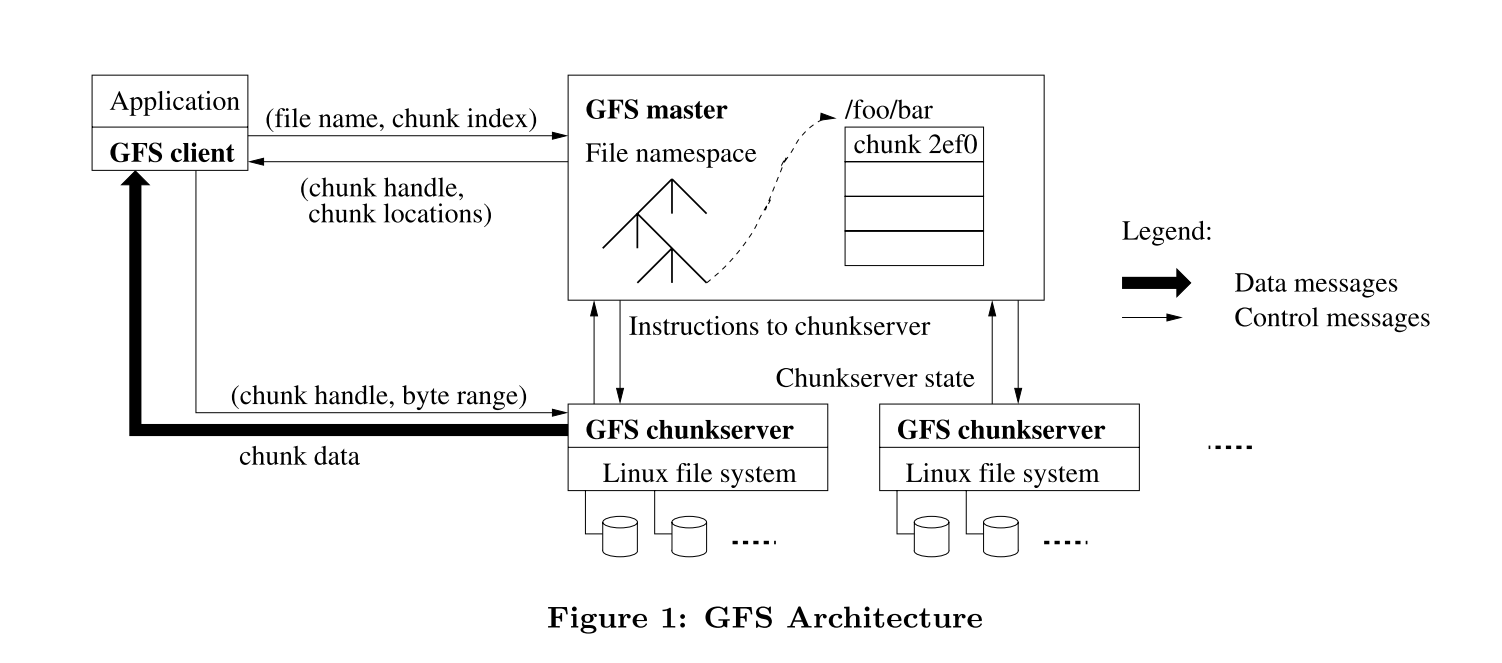
- 一个GFS集群由一个master和多个分块服务器(chunkserver)组成
- 文件以固定大小的块存储,块由全局唯一的64位ID标识,默认情况下每个区块具有三个副本。
- master存储所有文件的元信息,包括名称空间、访问控制信息、文件到块的映射以及块的当前位置。
- master定期使用心跳信息与块交流,提供指令和收集状态。
- 链接到每个应用程序中的GFS客户端代码实现文件系统API,并与主服务器和分块服务器通信,以代表应用程序读取或写入数据。
- 客户端和分块服务器不缓存文件数据。
- 客户端会询问master该和哪个分块服务器交互,然后直接与分块服务器读取和写入数据。
交互过程:
- 客户端通过指定的文件名和字节偏移量转化为
(file name,chunk index),并发送给master。 - master回复相应的区块句柄和区块位置。
- 客户端在一定时间内缓存
(file name,chunk index),一便后续使用 - 客户端向其中的一个副本(距离最近优先)发送
(chunk handle,byte range)请求。 - 在缓存有效期内,对同一块的访问不需重复请求master。
master存储的元信息(位于master的内存中):
- 文件和块命名空间
- 文件到块映射信息
- 每个块副本的位置信息
前两种还会以操作日志并保存到远程计算机上来避免master发生崩溃和不一致。每个块的信息则不会持久存储。
系统交互
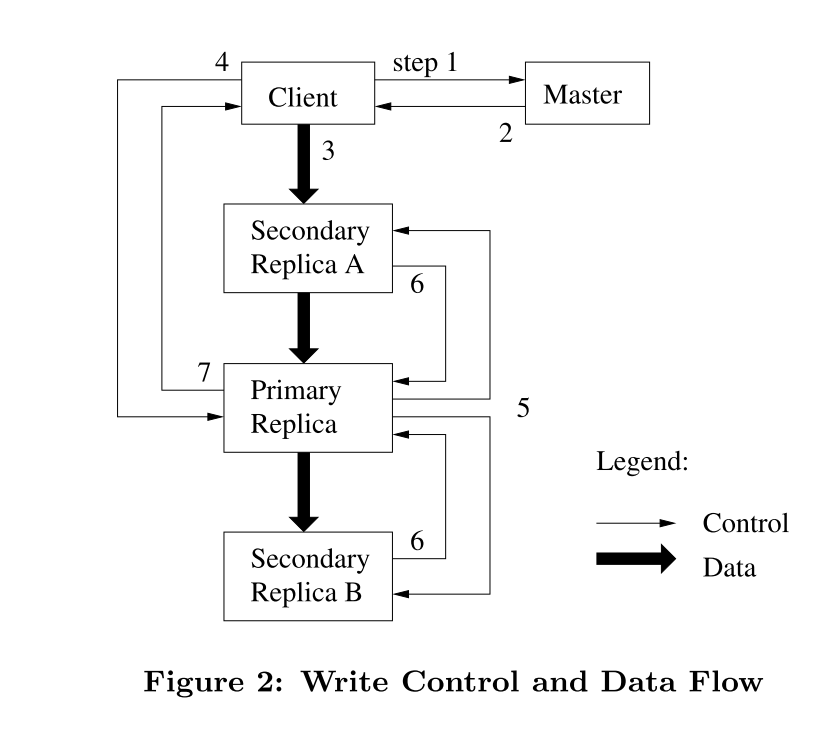
- 客户端询问master哪个 chunkserver 持有该块的当前租约以及其他副本的位置。如果没有人拥有租约,主服务器会将租约授予它选择的副本(未显示)。
- master回复主副本的身份和其他(次级)副本的位置。客户端缓存此数据以供将来的突变使用。仅当主副本不可达或不再持有租约的情况下,客户端需要再次联系master。
- 客户端推送data给所有的副本,块服务器会将数据缓存在内部LRU,直到数据被使用或过期。
- 一旦所有副本确认已收到数据,客户端就会像主副本发送写入请求。该请求标识先前推送到所有复制副本的数据。主副本将连续的序列号分配给它接收到的所有突变(可能来自多个客户端)。这提供了必要的序列化。它将突变按序列号顺序应用于自己的局部状态。
- 主副本将写入请求转发到所有次级副本。每个次级副本都按照主副本指定的相同序列号顺序应用突变。
- 次级副本会回复主副本,表示操作已经完成。
- 主副本回复客户端,过程中发生的任何错误都会报告给客户端。如果出现错误,可能在主副本或者部分次级副本的上是成功的。 (如果它在主服务器上失败,则不会为其分配序列号并转发。)客户端请求被视为失败,并且修改的区域将处于不一致状态。我们的客户端代码通过重试失败的突变来处理此类错误。它将在步骤 (3) 到 (7) 中进行几次尝试,然后返回到从写入开始处重试。
Master操作
命名空间管理和锁
- 使用锁和串行来支持多个操作
- 读锁和写锁,若涉及/d1/d2/leaf,则需要获取递归目录名的所有读锁,和/d1/d2/leaf读锁或写锁
- 对目录上的读锁保证了操作的过程中,其目录不会被删除、重命名或快照。
副本放置
- 通常有数百个块服务器分布在许多机器机架上。这些块服务器又可以从相同或不同机架的数百个客户端访问。
- 块副本放置策略有两个目的:最大化数据可靠性和可用性,以及最大化网络带宽利用率。
创建、重新复制、重新平衡
- 创建块副本的原因有三个:块创建、重新复制和重新平衡。
- 创建目标考虑因素:磁盘空间利用率、“最近”创建的数量、将块的副本分布在机架上
- 一旦可用副本的数量低于用户指定的目标,主服务器就会重新复制块。
- 主节点选择最高优先级的块,并通过指示某些块服务器直接从现有的有效副本复制块数据来“克隆”它。复制的考虑因素同创建目标
- 它检查当前的副本分布并移动副本以获得更好的磁盘空间和负载平衡。
垃圾回收
当文件删除后,GFS 不会立即回收可用的物理存储。它仅在文件和块级别的常规垃圾收集期间延迟执行此操作。
- 文件被重命名为一个隐藏的名称,包含了删除时间
- 当master扫描文件系统命名空间时,会删除存在超过三天的该类隐藏名称的文件。在此之前这类待删除文件可以被访问或撤销删除,通过其特殊的隐藏名称
- 无法从任何文件到达的孤儿块也会被master检测,并在HeartBeat期间,发送给块服务器,通知他们自行删除。
优势:
- 在组件故障频发的大规模分布式系统中,它简单可靠。
- 分批进行,成本摊销。
- 延迟回收存储提供了一个安全网,防止意外的、不可逆转的删除。
劣势:
- 不利于存储空间紧张的情况,因为删除不是立刻的,不会立马释放物理存储空间
- 可通过再次删除和不同的复制和再生机制
过期副本的检测
- 块服务器宕机时,副本的修改可能失败,因此变为过期副本
- master通过版本号判断副本过期与否
- master移除过期的副本在其垃圾回收过程中。
容错和检测
高可用性
- 快恢复:master和chunkserver都被设计为恢复它们的状态并在几秒钟内启动,无论它们是如何终止的。
- 块复制:每个区块都在不同机架上的多个区块服务器上进行复制。
- Master复制:它的操作日志和检查点在多台计算机上复制。
数据完整性
- 块服务器使用校验和验证数据的合法性
- 每个64KB的块使用32bit的校验和,保存在内存中,通过日志记录持久存储
- 对于读取,都会验证数据块的校验和。若不一致,块服务器会返回一个错误,作为响应,请求者将从其他副本中读取,而主机将从另一个副本中克隆区块。在一个有效的新复制副本就位后,主服务器指示报告不匹配的chunkserver删除其复制副本。
- 块服务器会在空闲时刻扫描块的有效性。若检测到损坏,则会复制并删除原有的块。
诊断工具
- GFS服务器生成诊断日志,记录许多重要事件(如chunkserver运行和关闭)以及所有RPC请求和回复。
衡量
Lecture 04 - VMware FT
Fault tolerance:容错,使用复制提供可用性,尽管网络和服务器会发生错误
复制可以解决的问题:
- 单个副本的 “故障停止 “故障:Cpu过热关机、副本网络故障、磁盘空间不足
- 不能解决副本之间具有相关联的问题:如同一批购买的服务器往往有同样的设计缺陷
是否值得复制:额外的副本往往需要付出X倍的成本,这是一个经济问题。取决于可用服务的价值,如银行系统那肯定值得复制,如网课平台就不需要有额外的副本
状态转移和复制状态机
状态转移:Primary直接把自己的信息,如内存通过网络传输给Backup(往往是增量传输)
复制状态机:Primary把来自客户端的操作或其他外部事件传输给Backup.
复制状态机基于下述原理:通常来说,如果有两台计算机,如果它们从相同的状态开始,并且它们以相同的顺序,在相同的时间,看到了相同的输入,那么它们会一直互为副本,并且一直保持一致。
复制状态机如何解决例如具有随机性的操作或个体差异操作,如生成随机数/获取当前系统时间/获取CPU序列号。对于这一类问题的统一答案是,Primary会执行这些指令,并将结果发送给Backup。Backup不会执行这些指令,而是在应该执行指令的地方,等着Primary告诉它,正确的答案是什么,并将监听到的答案返回给软件。
论文
[nil.csail.mit.edu/6.824/2020/papers/vm-ft.pdf](http://nil.csail.mit.edu/6.824/2020/papers/vm-ft.pdf
【译文】The Design of a Practical System for Fault-Tolerant Virtual Machines 一种主备容错方案的可行解 - 知乎 (zhihu.com)
VMware FT工作原理
VMM:虚拟机监控器,用于在硬件上模拟出多个虚拟的计算机,其中每一个都有自己的操作系统内核和应用程序。
VMware FT需要有两个物理服务器,将Primary和Backup运行在一台物理服务器的两个虚拟机里没有意义,达不到容错目的。通常这两个物理服务器上的VMM会为Primary和Backup分配镜像相同的内存和同样的操作系统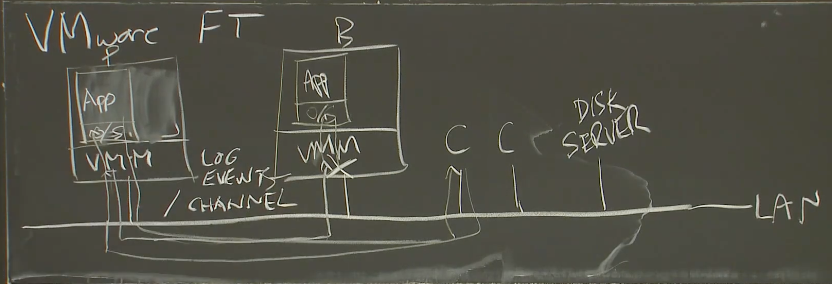
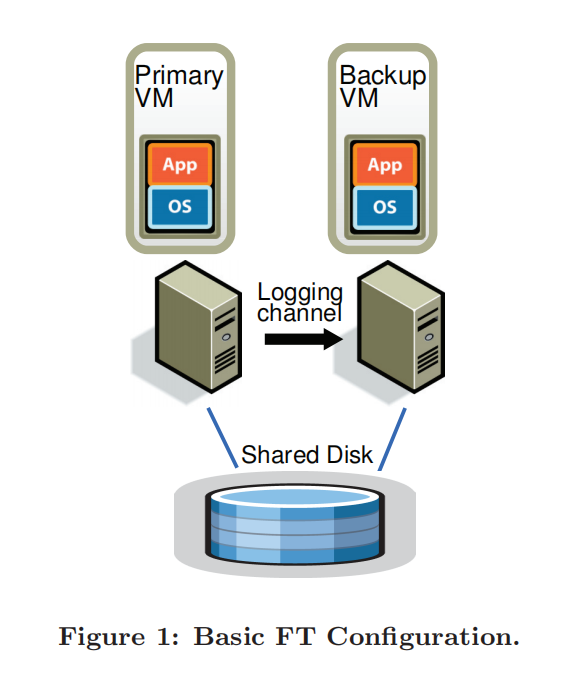
基本的工作流程:
- 客户端向Primary发送请求,请求以网络数据包的形式发出
- 网络数据包产生中断,送到VMM。在虚拟机的guest操作系统中,模拟网络数据包到达的中断,以将相应的数据送给应用程序的Primary副本。除此之外,因为这是一个多副本虚拟机的输入,VMM会将网络数据包拷贝一份,并通过网络送给Backup虚机所在的VMM。
- Primary生成回复报文,通过VMM在虚拟机内模拟的虚拟网卡发出,Backup也会生成同样的报文,但会丢弃。
- 当Primary因为故障停止运行,Backup就会成为Primary,进行接管
非确定性事件的处理
Lecture 05 - Go、Threads
Goroutines和Closures
Goroutines:Go语言中的轻量级线程,并发运行,当main goroutine退出,程序终止
1 | func main() { |
Closures:闭包
Go语言基础知识 —— Closure(闭包) - 知乎 (zhihu.com)
Time:
- time.Sleep():使当前线程睡眠一段时间
- 可以在循环中使用,达成间隔x秒执行一次的效果
Mutexes:锁 - mu.Lock():等待获取锁
- mu.Unlock():解锁,一般结合defer使用,延迟一段时间后解锁
- Go语言 WaitGroup 详解 - 知乎 (zhihu.com)
Condition variables:
1 | package main |
Channels: 管道,并发安全的队列
Lecture 06 - Raft
论文:
In Search of an Understandable Consensus Algorithm (mit.edu)
【译文】Raft协议:In Search of an Understandable Consensus Algorithm (Extended Version) 大名鼎鼎的分布式共识算法 - 知乎 (zhihu.com)
基础
Consensus vs Consistency
一致性(consistency)往往指分布式系统中多个副本对外呈现的数据的状态。如顺序一致性、线性一致性,描述了多个节点对数据状态的维护能力。
共识(consensus)则描述了分布式系统中多个节点之间,彼此对某个提案达成一致结果的过程。
因此,一致性描述的是结果,共识则是一种手段。
子问题
- Leader election(领导选举):一个 leader 倒下之后,一定会有一个新的 leader 站起来。
- Log replication(日志复制):leader 必须接收来自客户端的日志条目然后复制到集群中的其他节点,并且强制其他节点的日志和自己的保持一致。
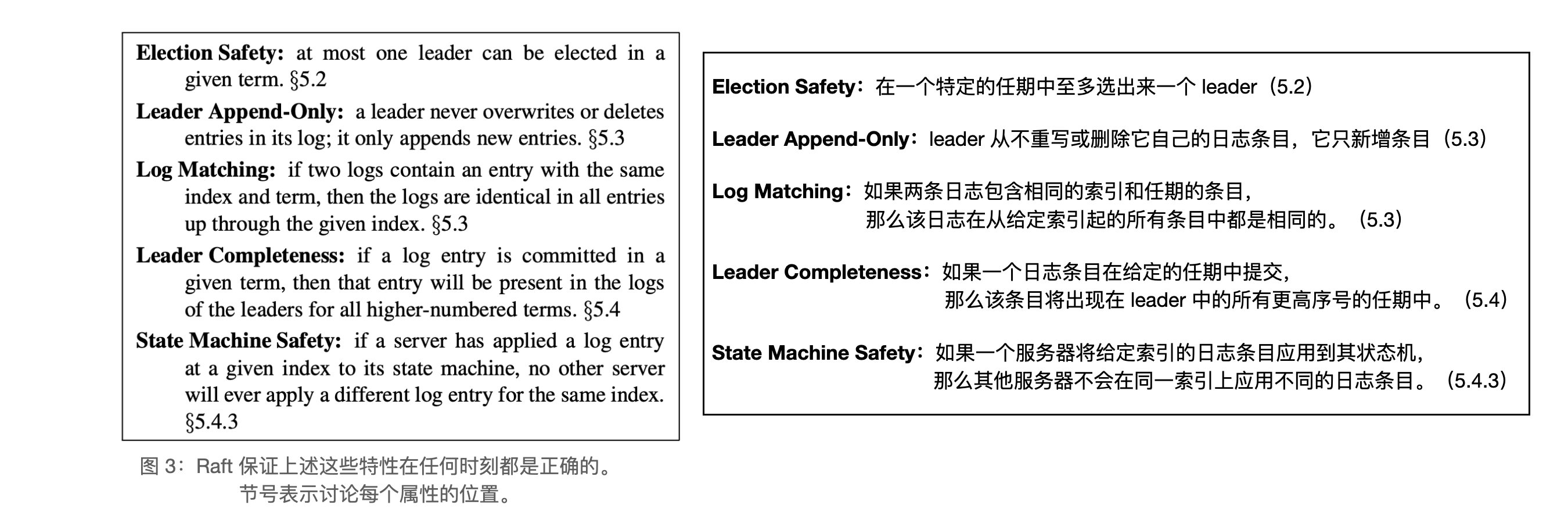
- Safety(安全性):
角色
一个Raft集群中包含若干个服务器节点,一般具有N个节点的集群,可以容忍(N-1)/2个节点的失效,集群中的节点在任何时刻都是以下三种身份之一:
- Leader:领导,负责处理客户端请求(follower会将请求重定向到leader)
- Follower:被动的,仅响应来自Leader和Candidate的请求(是节点的初始身份)
- Candidate:候选人,用来选举成为新的leader时的临时态。
一般情况下:集群只有1个leader,剩下的都是follower,其状态转换关系如下:
任期
Raft将时间划分为多个任期,并进行编号。每一段任期从一次选举开始,任意一个任期内最多有一名Leader。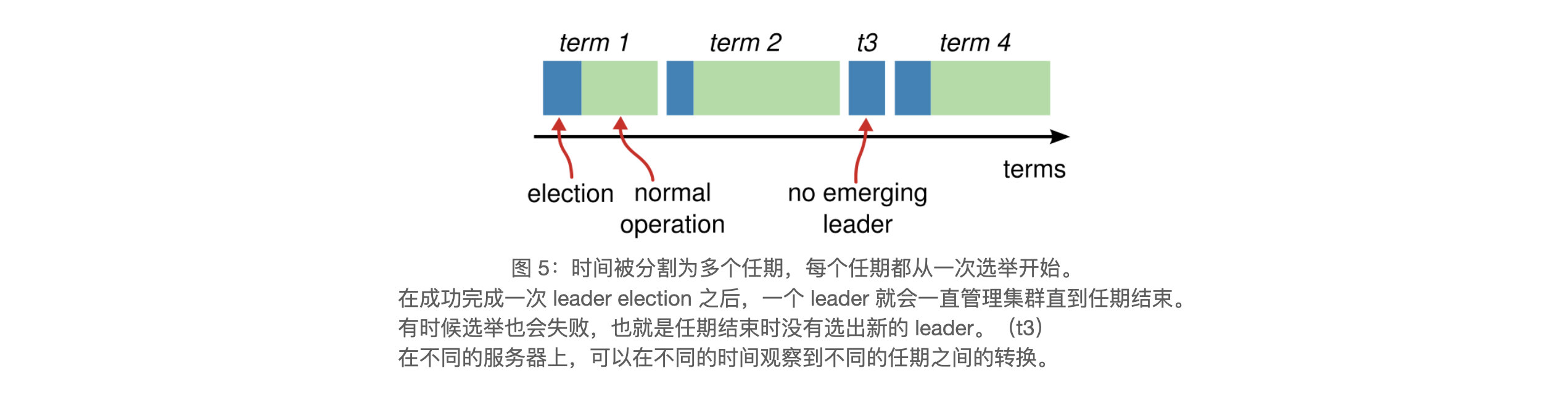
任期在 Raft 中还扮演着一个逻辑时钟(logical clock)的角色,这使得服务器可以发现一些过期的信息,比如过时的 leader。
每一个节点都存储着一个当前任期号(current term number),该任期号会随着时间单调递增。节点之间通信的时候会交换当前任期号,如果一个节点的当前任期号比其他节点小,那么它就将自己的任期号更新为较大的那个值。如果一个 candidate 或者 leader 发现自己的任期号过期了,它就会立刻回到 follower 状态。如果一个节点接收了一个带着过期的任期号的请求,那么它会拒绝这次请求。
RPC
- RequestVote RPCs(请求投票):由 candidate 在选举过程中发出
- AppendEntries RPCs(追加条目):由 leader 发出,用来做日志复制和提供心跳机制
领导选举
Raft采用心跳机制来触发leader的选举。起初所有节点都是follower,每个节点都有一个不同的随机超时时间(一般是150~300ms)当收到来自其他leader或candidate那有效的RPC就会刷新自己的超时时间,并保持follower状态,但如果在一段时间内(即设置的超时时间election timeout)没有收到有效的RPC,则该节点会假定集群内当前没有可用的leader,那么他会尝试进行leader的选举(此时不立,更待何时)。
选举流程
- 某follower节点达到了自己的超时时间,发起选举
- 增加任期号,并切换为candidate角色
- 给自己投票,并以并行的方式向其他节点发送RequestVote PRCs,请求给自己投票
- 选举结果可能如下:
- 赢得了超过半数的票,成为leader,开启新一段任期
- 其他节点赢得了选举,变为follower
- 没有任何节点在选举中胜出(如果超时时间设置相同,那么所有节点在同一时间发起选举,把票都投给自己,发生了分票(split votes)现象)
当一个candidate获得了针对同一任期内超过一半的票,就成为新的leader,这保证了同一时期最多只能有一个candidate赢得选取,当赢得选取后,该leader会向其他节点发送心跳信息,保持自己的地位。
选举约束
不是所有followes都有资格成为leader的,当candidate向其他节点发送Request Vote Rpcs时,只有满足下面情况之一,followers才会投赞成票。
- candidate的最后一条log条目的term > follower的最后一条log条目的term
- candidate的最后一条log条目的term = follower的最后一条log条目的term,但candidate的log条目记录的长度 >= follower
也就是说,raft更喜欢log最新最完整的候选人成为leader
日志复制
Leader需要负责响应来自客户端的请求,每一个客户端的请求都包含一条将被复制状态机执行的指令。
日志复制过程:
- Leader会以新条目的形式将命令追加到自己的日志中
- 向其他节点发送AppendEntries RPCs,让他们复制。
- 当条目被安全地复制后,leader会将该条目应用到自己的状态机中,状态机执行该指令,然后将执行的结果返回给客户端。
日志存储的方式:
- 每条日志以(term,command)的二元组构成,用索引值index表示他在日志中的位置。
- 不同节点上,任期号term和索引值index相同的日志,其一定具有相同的command
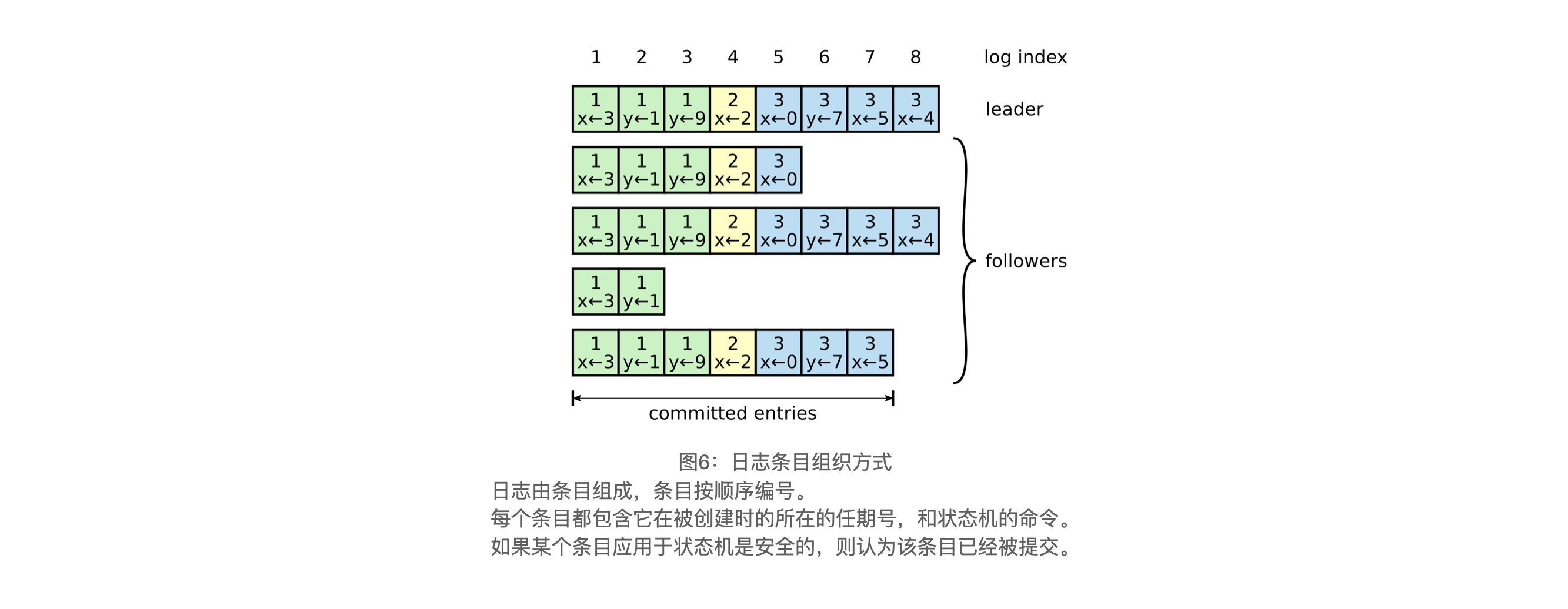
我们设计 Raft 日志机制来使得不同节点上的日志之间可以保持高水平的一致性。这么做不仅简化了系统的行为也使得系统更加可预测,同时该机制也是保证安全性的重要组成部分。Raft 会一直维护着以下的特性,这些特性也同时构成了图 3 中的日志匹配特性(Log Matching Property): - 如果不同日志中的两个条目有着相同的索引和任期值,那么它们就存储着相同的命令
- 如果不同日志中的两个条目有着相同的索引和任期值,那么他们之前的所有日志条目也都相同
日志的一致性检查
当leader发送一个AppendEntries RPCs时,leader还会附加一个上一条日志条目的索引位置和日期号在里面。当follower收到该RPCs后,如果在日志中找不到含有相同索引和任期号的日志条目,那么它就会拒绝,并回复leader。
leader在内部维护了对每一个follower的nextIndex,nextIndex给某个节点发送的下一日志条目的索引,当选出一个新的 leader 时,该 leader 将所有的 nextIndex 的值都初始化为自己最后一个日志条目的 index +1。如果一个 follower 的日志跟 leader 的是不一致的,那么下一次的 AppendEntries RPC 的一致性检查就会失败。AppendEntries RPC 在被 follower 拒绝之后,leader 对 nextIndex 进行减 1,然后重试 AppendEntries RPC。最终 nextIndex 会在某个位置满足 leader 和 follower 在该位置及之前的日志是一致的,此时,AppendEntries RPC 就会成功,将 follower 跟 leader 冲突的日志条目全部删除然后追加 leader 中的日志条目(需要的话)。一旦 AppendEntries RPC 成功,follower 的日志就和 leader 的一致了,并且在该任期接下来的时间里都保持一致。
通过上述机制,日志在AppendEntries的一致性检查时,就会自动趋于一致。
安全性
StartElection:
1.超时
RequestVote
sendRequestVote
handleVoteResult
1 | type AppendEntriesArgs struct { |
ticker
broadcastRPC:区分心跳和附加日志
1.心跳
当nextIndex还是matchIndex
正常情况nextIndex[i] == len[rf.log] == matchIndex[i]+1
表示i号节点不缺log了
2.日志
当nextIndex[i] < len[rf.log]
AppendEntries
1.比较任期
if args.term<rf.currentTerm:
返回自己的任期和False,提醒leader自己已经过期。
2.判断是心跳还是日志附加
if args.term>rf.currnetTerm:
rf.role = Follower
rf.voteFor = -1
rf.currentTerm=args.term
reply.Term = rf.currentTerm
刷新选举时间
if 心跳:
reply.Success = true
更新commit并提交相关log
else:
if 日志匹配
保持和leader一致
else:
reply.Success = false
sendAppendEntries
handleAppendEntries
Lecture 08 - Zookeeper
线性一致:
- 一个线性一致的执行历史中的操作是非并发的,也就是时间上不重合的客户端请求与实际执行时间匹配。
- 每一个读操作都看到的是最近一次写入的值。

提供如下服务
- 统一命名服务
- 配置管理
- 成员管理
- Leader 选举
- 协调分布式事务
- 分布式锁
文件系统
每个树节点被称为znode
znode的类型:
- Regular:客户端通过显式创建和删除常规znode来操作它们
- Ephemeral:客户端创建这样的znode,它们要么显式删除它们,要么在创建它们的会话终止时(故意或由于故障)让系统自动删除它们。
这样组合后其实有四种类型的 znode:
PERSISTENTEPHEMERALPERSISTENT_SEQUENTIALEPHEMERAL_SEQUENTIAL
客户端通过watch机制能够不需要轮询就可以及时接收更改通知
会话(Sessions)
客户端通过一个会话来和ZooKeeper建立连接。
客户端API
create(path,data,flags):创建一个路径名为path的znode,并存放data数据,返回该新znode的名称。flag使客户端能够选择znode的类型:常规、短暂,并设置顺序标志。delete(path,version):删除指定路径path下的znode如果它处于给定的version下。exists(path,watch):判断指定路径path下是否存在znode。该watch标志能够使客户端在该znode设置一个监听。getData(path,watch):返回与znode关联的数据和元数据,如版本信息。watch标志的工作方式与它对exists()的工作方式相同,只是如果znode不存在,ZooKeeper不会设置watch;setData(path,data,version):如果版本号是znode的当前版本,则将data写入指定路径path的znode;getChildren(path,watch):返回路径为path的zndoe所有孩子节点名称集合。sync(path):等待在操作开始时挂起的所有更新传播到客户端连接的服务器。该路径当前被忽略。
所有方法都有通过API提供的同步和异步版本。
更新方法通常有一个预期版本号,只有匹配时才能更新成功。
Zookeeper guarantees
zookeeper提供了两个基本的顺序保证:线性写和先进先出的客户端请求
- Linearizable writes:所有更新ZooKeeper状态的请求都是可序列化的,并尊重优先级;
- FIFO client order:来自给定客户端的所有请求都按照客户端发送的顺序执行。
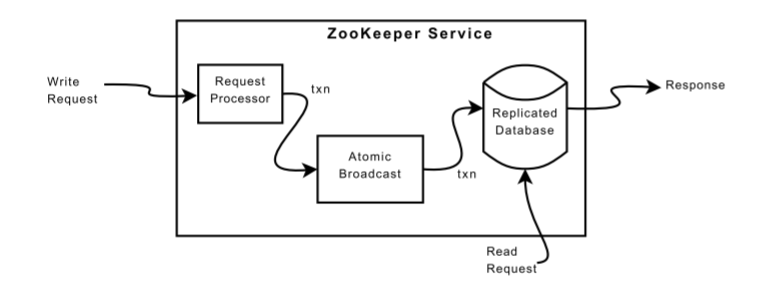
Request Processor
由于消息传递层是原子的,我们保证本地副本永远不会发生分歧,尽管在任何时刻,某些服务器可能应用了更多的事务。与从客户端发送的请求不同,事务是幂等的。当领导者收到写请求时,它计算在应用写操作时系统的状态,并将其转换为一个事务,捕捉这个新状态。必须计算未来的状态,因为可能存在尚未应用于数据库的未完成事务。例如,如果客户端执行条件setData,且请求中的版本号与要更新的znode的未来版本号匹配,则服务生成一个包含新数据、新版本号和更新时间戳的setDataTXN。如果发生错误,例如版本号不匹配或要更新的znode不存在,就会生成一个errorTXN。
Atomic Broadcast
所有更新ZooKeeper状态的请求都会被转发到Leader进行。
原子广播协议Zab,多数决策(类似Raft协议)
使用TCP传输消息,以确保顺序
写前日志和幂等事务
Replicated Database
每个复制副本都有一个ZooKeeper状态的副本。
使用定期快照避免恢复时间过长,快照采用模糊快照(fuzzy snapshot)
Client-Server Interactions
Lab
Lab 1.MapReduce
Lab 2.Raft
Lab 3.KVRaft
Lab 4.ShardKV
参考资料
中文笔记 - MIT6.824 (gitbook.io)
6.824 Home Page: Spring 2020 (mit.edu)
MIT 6.824分布式 LAB3: kvraft - 知乎 (zhihu.com)
Consensus: Bridging Theory and Practice (stanford.edu)
OneSizeFitsQuorum/MIT6.824-2021: 4 labs + 2 challenges + 4 docs (github.com)
MIT 6.824 (现6.5840) 通关记录 - 知乎 (zhihu.com)
MIT 6.824 Lab Raft测试框架 - 知乎 (zhihu.com)