面向NLP模型的字符级白盒对抗样本生成方法研究
前置知识
- 白盒攻击:在机器学习模型的安全领域,攻击者如果具有关于模型的全部知识,包括模型的结构、参数和训练数据等,这种攻击被称为“白盒攻击”。攻击者利用这些信息生成对抗样本,目的是欺骗模型做出错误的预测。与之相对的,如果攻击者不知道模型的内部结构,
- 字符级:这意味着对抗性干扰发生在文本数据的最小单位——字符层面。通过在文本数据中添加、删除或替换单个字符,攻击者可以生成与原始数据在人类理解上几乎相同,但在机器学习模型中可能导致不同输出的样本。
- 对抗样本:对抗样本是通过在原始数据上故意添加人类难以察觉的扰动生成的样本,目的是欺骗机器学习模型。在字符级对抗样本的情况下,这些扰动通常是对文本中的字符进行微小的修改。
- 对抗攻击:生成对抗样本让模型产生错误的输出称为对抗攻击。
攻击粒度/生成方法:幅度从大到小,更大地粒度更容易改变模型的输出结果。
句子级:
单词级:
字符级:
一、背景
- 安全性:构造对抗样本干扰模型的输出,导致人工智能应用在关键领域出现判断失误、检测失效、隐私泄露等重大安全隐患。
意义
- 垃圾邮件分类检测,通过模型漏洞,构造样本来规避模型检测。
- 通过生成对抗样本的训练,提升模型的鲁棒性。
任务类型
- 分类任务:整个输入对应一个标签。
- 序列标注任务:句子->单词标签。
- 机器翻译任务:序列->序列任务
二、相关工作
介绍了目前流行的几种方法
句子级别
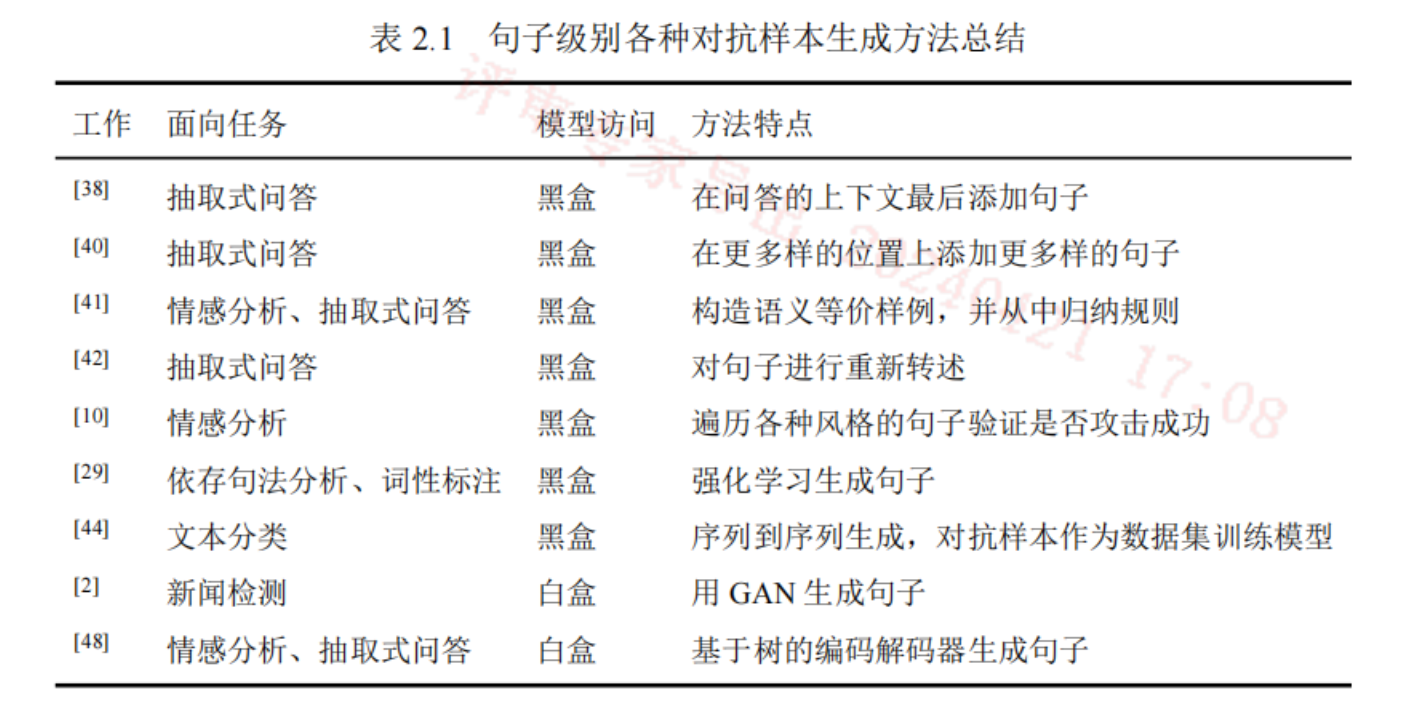
添加句子、替换等价句子、转述句子、改变句子风格、重新生成句子
单词级别
原地修改句子中的某些词汇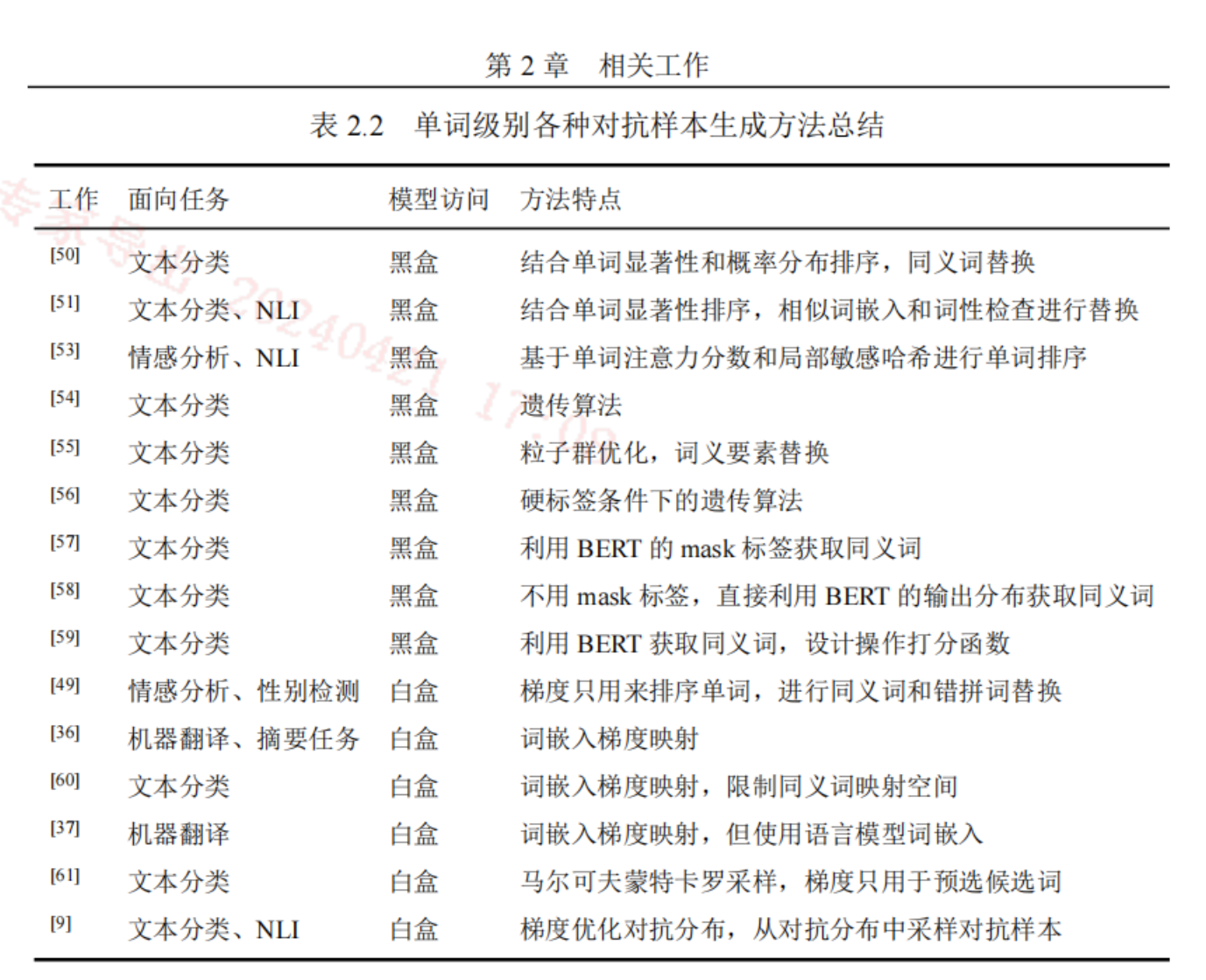
字符级别
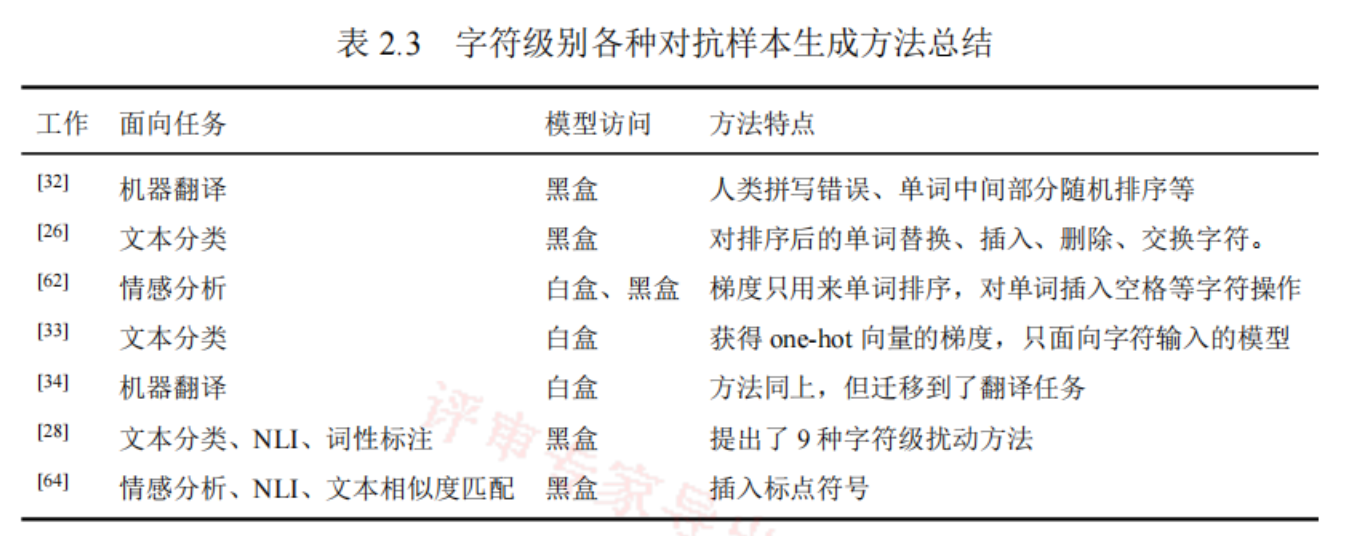
三、本文方法——CLTRA
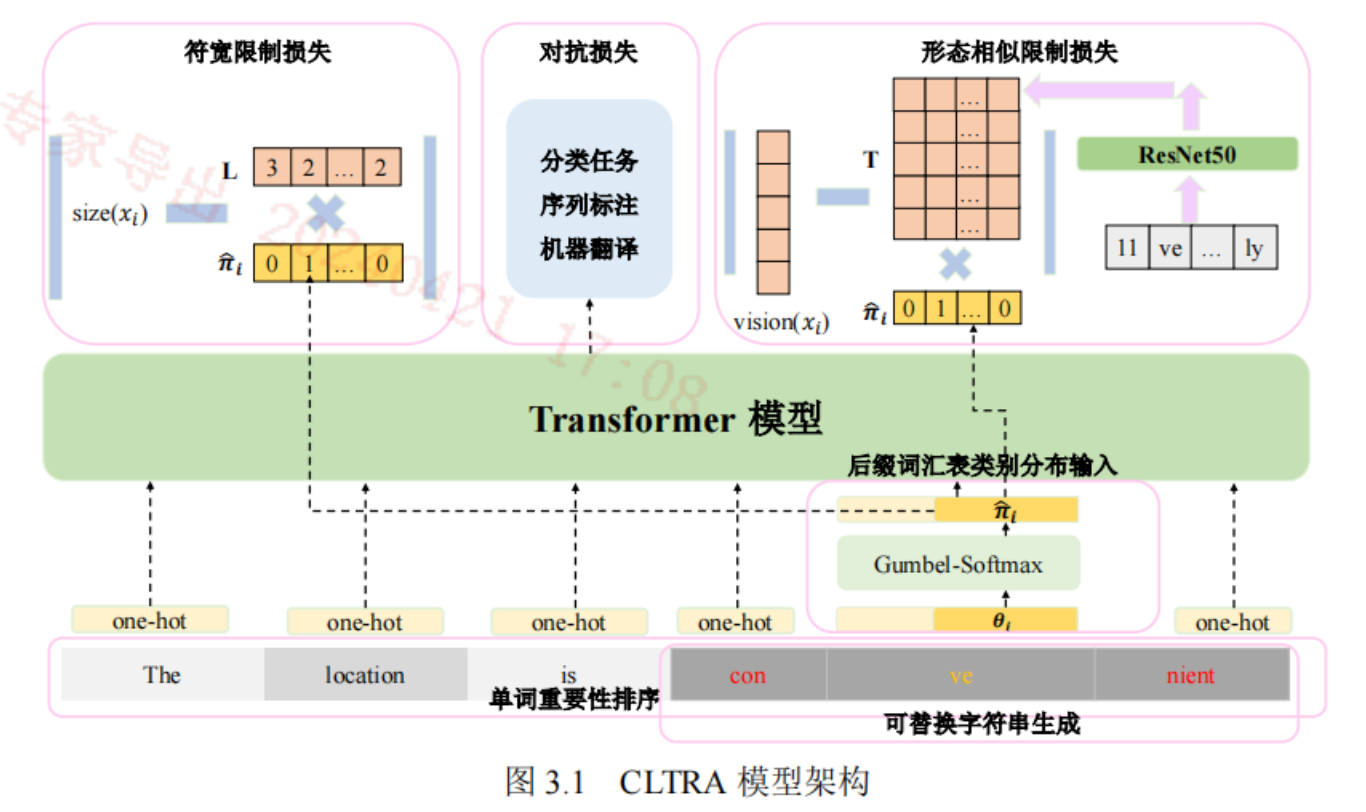
可替换字符串生成算法
每个单词至少被分成三部分:首子词、中间子词(可能多个)、尾子词。子词是指在后缀词汇表中已经存在的。其中首子词和尾子词保证是最长匹配。然后只对中间子词进行扰动。从而重新拼接变成一个新的单词。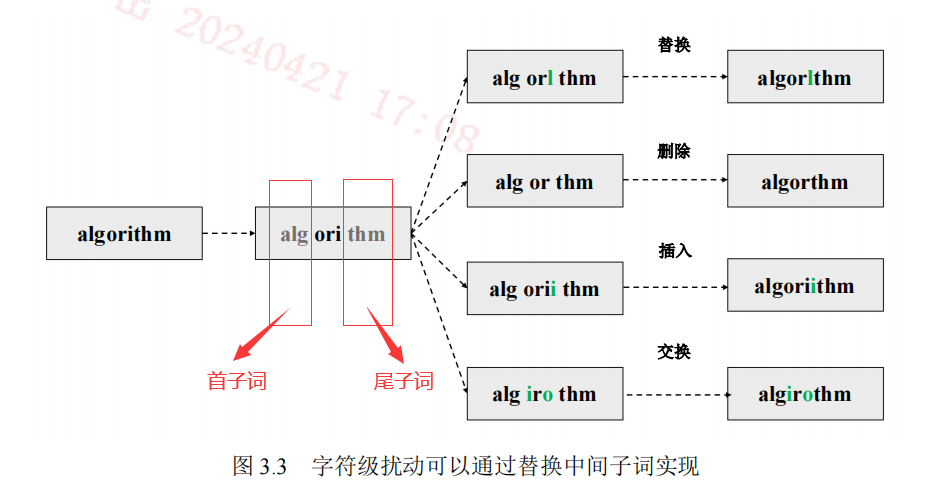
最长匹配特点保证了在对中间子词进行扰动后,拼接成的新单词不会被分词器以和原来不同的切分方式切分。
e.g.
原单词:algorithm
分词器切分后:a lgorith m
进行扰动:a ldorith m
拼接:aldorithm
分词器重新切分:aldo rith m(与原来切分方式不一致,应该被切分为a ldorith m)
后缀词汇表类别分布输入
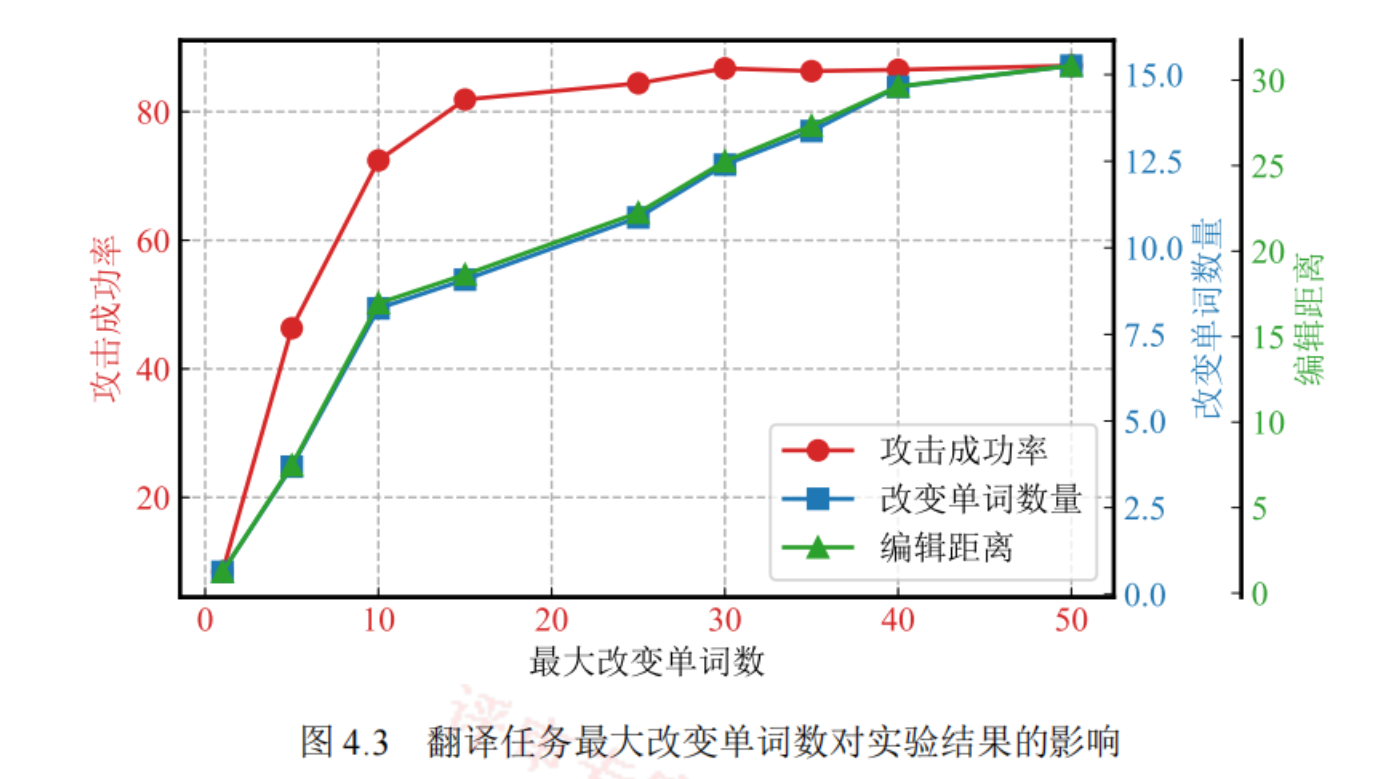
扰动范围
尽可能保证对抗样本s’和原样本s的相似性。
单词限制:取优先级最高的topk个单词进行扰动。
衡量指标:各个子词的梯度向量的二范数的均值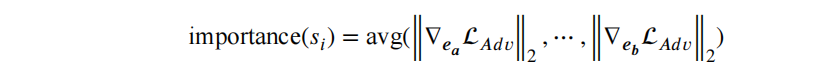
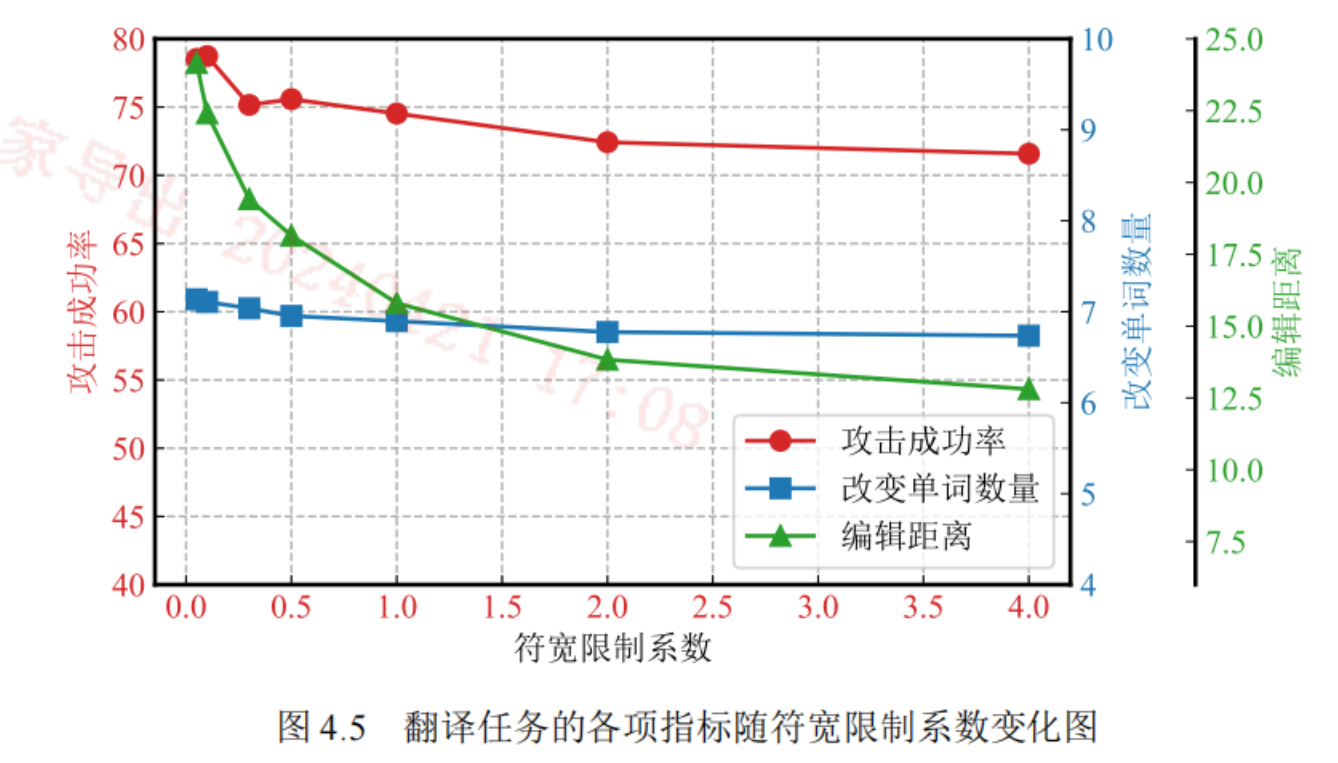
符宽限制:限制子词长度的变化。
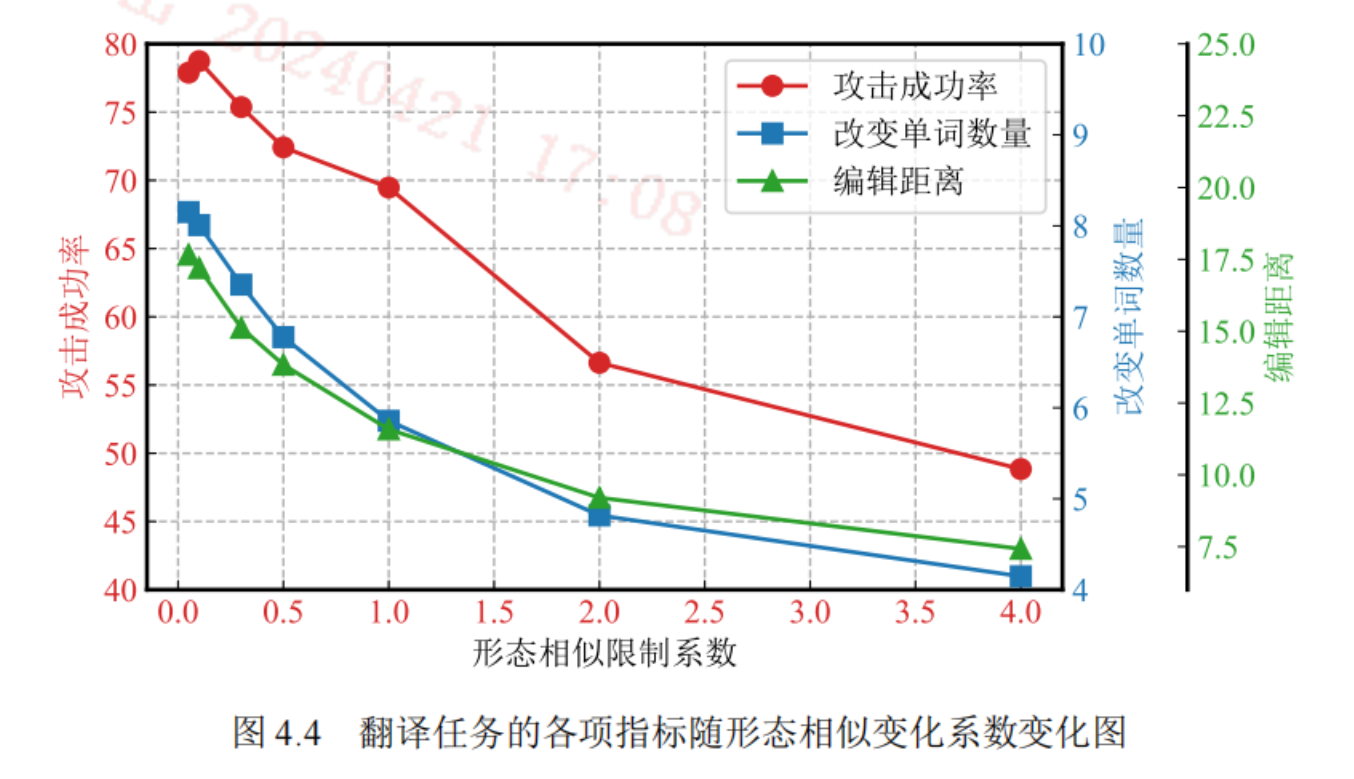
形态相似限制:让被替换的子词和原子词看上去是“相似”的。比如love和1ove。
方法是生成每个子词的图片,衡量其视觉向量的相似度。
损失函数
$Loss = L_{Adv} + \lambda_{size}*L_{size} + \lambda_{vision}*L_{vision}$
对抗损失函数、符宽限制系数,符宽损失函数、形态相似限制系数,形态相似损失函数
四、实验评估
分类任务
数据集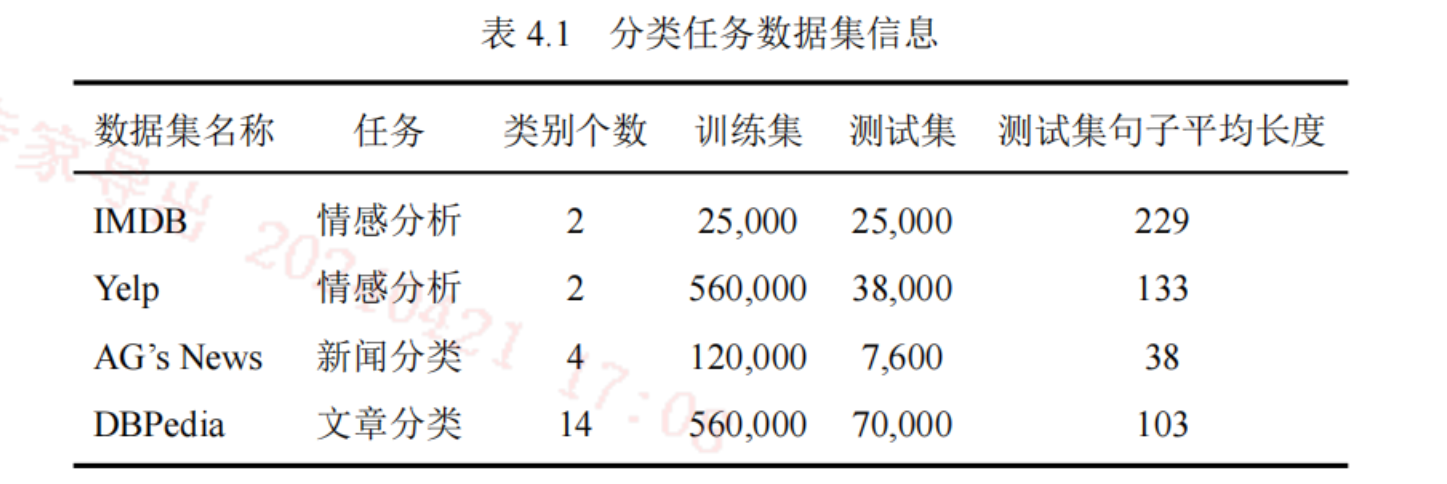
评价指标
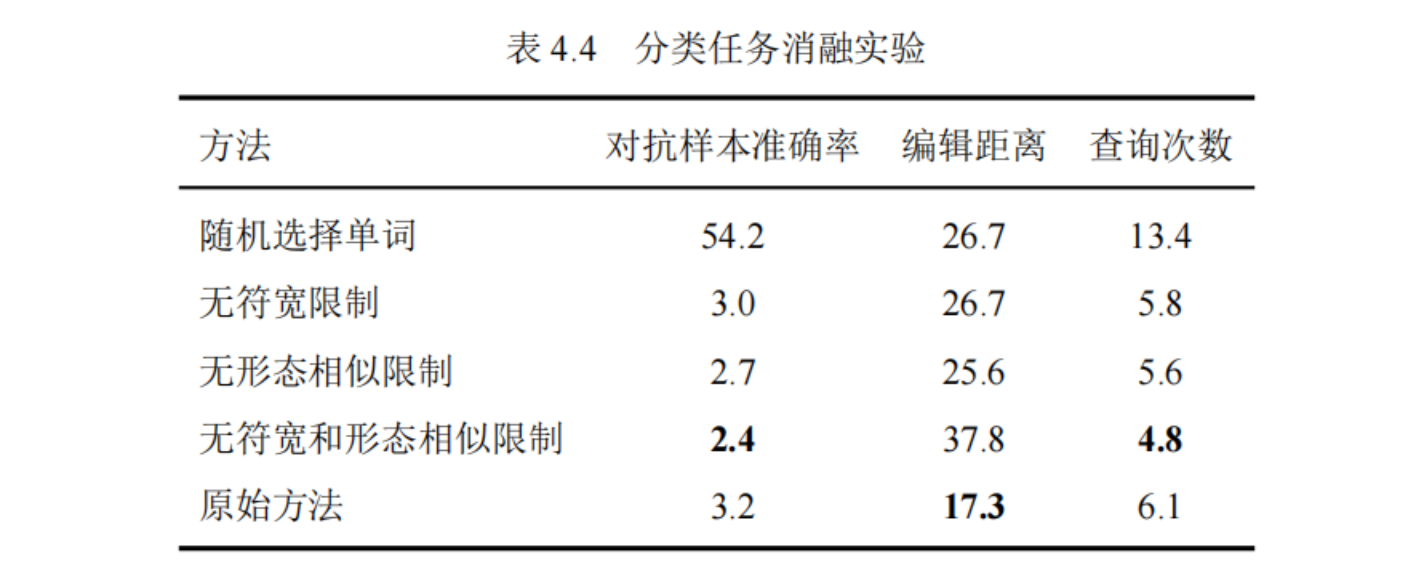
- 准确率:来评估对抗样本是否攻击成功,越低越好。
- 编辑距离:衡量对抗样本与原输入的扰动大小。越低意味着相似度更高。
- 查询次数:在构造对抗样本时,查询目标模型的次数。越低越好,意味着成本和性能更优。
基线方法 - GBDA:目前最优秀的单词级白盒对抗样本生成方法
- DeepWordBug:字符级的黑盒对抗样本生成方法
实验结果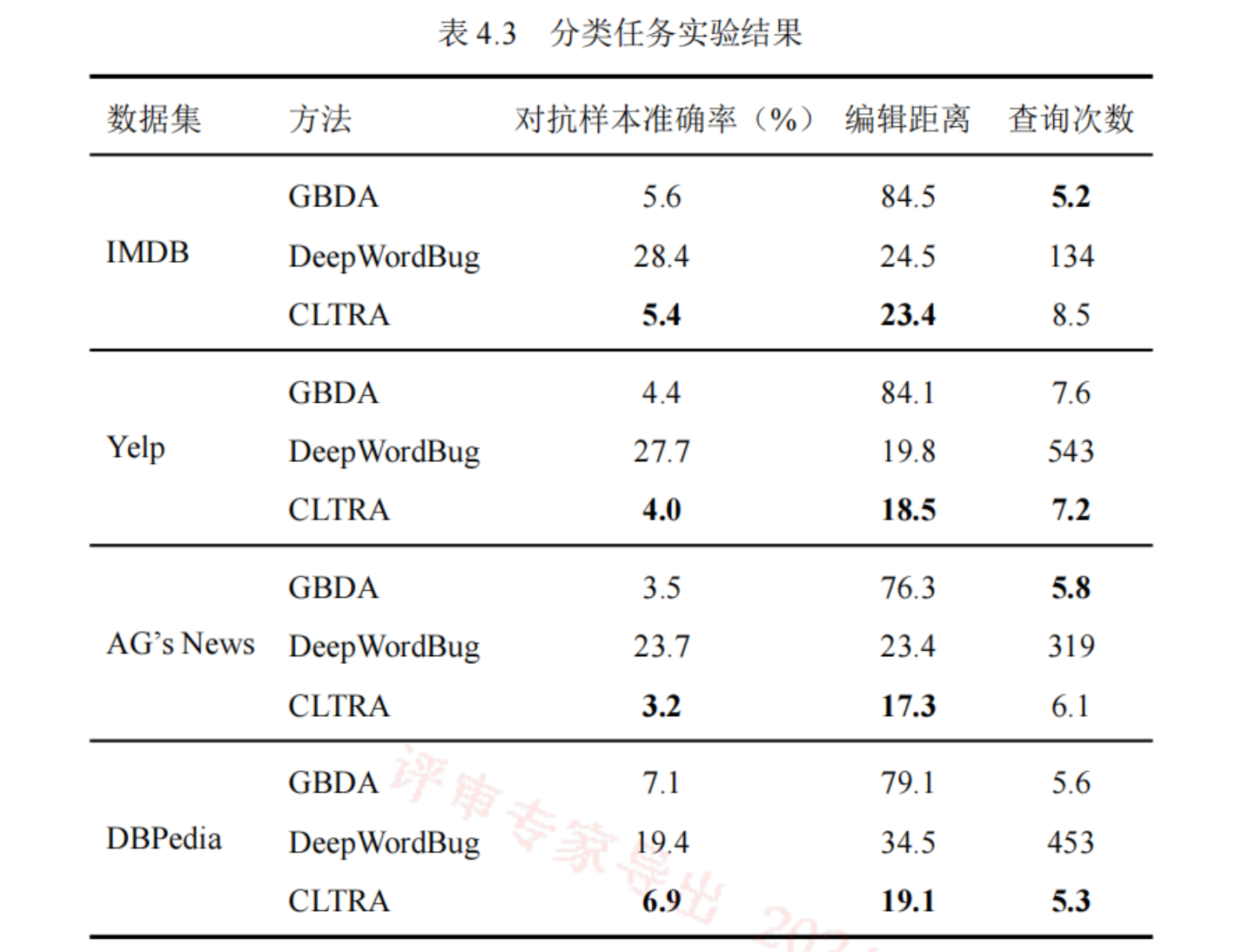
序列标注任务
命名实体识别任务:识别文本中的特定实体,并为这些实体分类。
Case:Apple Inc. announced its new product line in Cupertino on September 10th.
- Apple: (B-ORG)——组织名
- Cupertino: (B-LOC)——地点
- September :(B-DATE)——时间
槽位抽取任务:从文本中抽取特定信息的值,如时间、地点、数量。依赖于NER的结果来识别并分类信息。
Case:I want to book a flight from New York to London on July 15th.
- 意图:book a flight
- 出发地:New York
- 目的地:London
- 日期:July 15th
数据集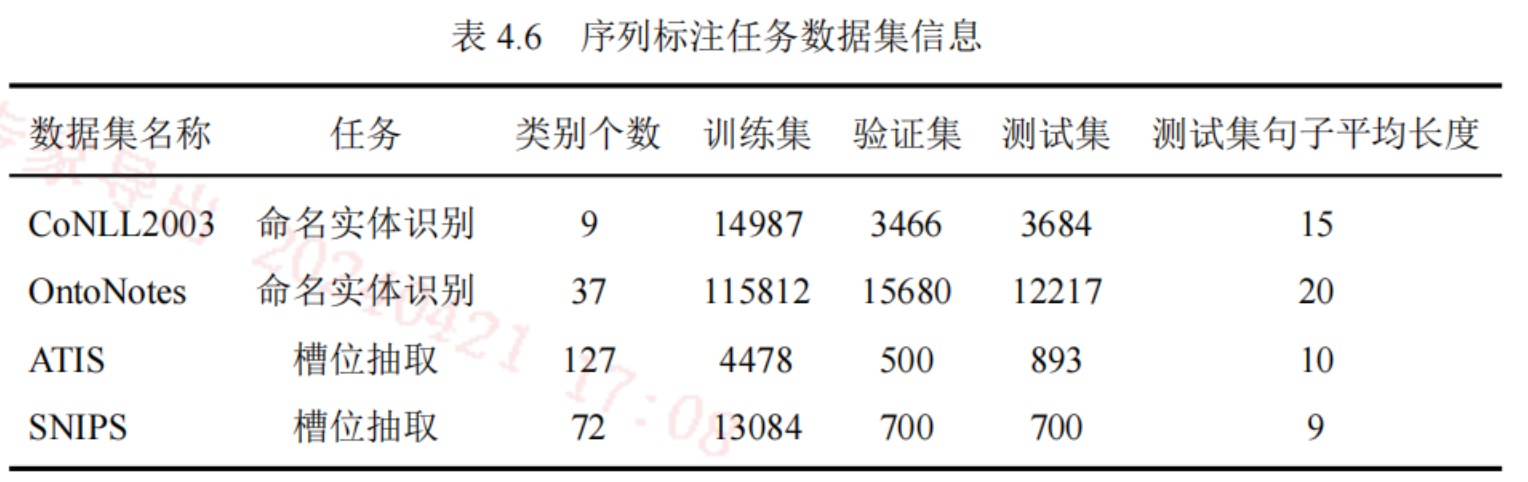
评价指标
- F1-Score:Precision和Recall的调和平均,用于衡量查准率和查全率。
- 实体攻击成功率:所有实体中攻击成功的实体的比例。判断标准是首个单词的B标签是否分类错误,B表示实体的开始。
- 编辑距离:同任务1
- 查询次数:同任务1
基线方法
- Zeroe:基于视觉攻击,用特殊字符进行替换,其原理是因为BERT的词汇表不包含上述这些特殊字符,其会被映射为
[UNK],有效的破坏了单词的语义。
实验结果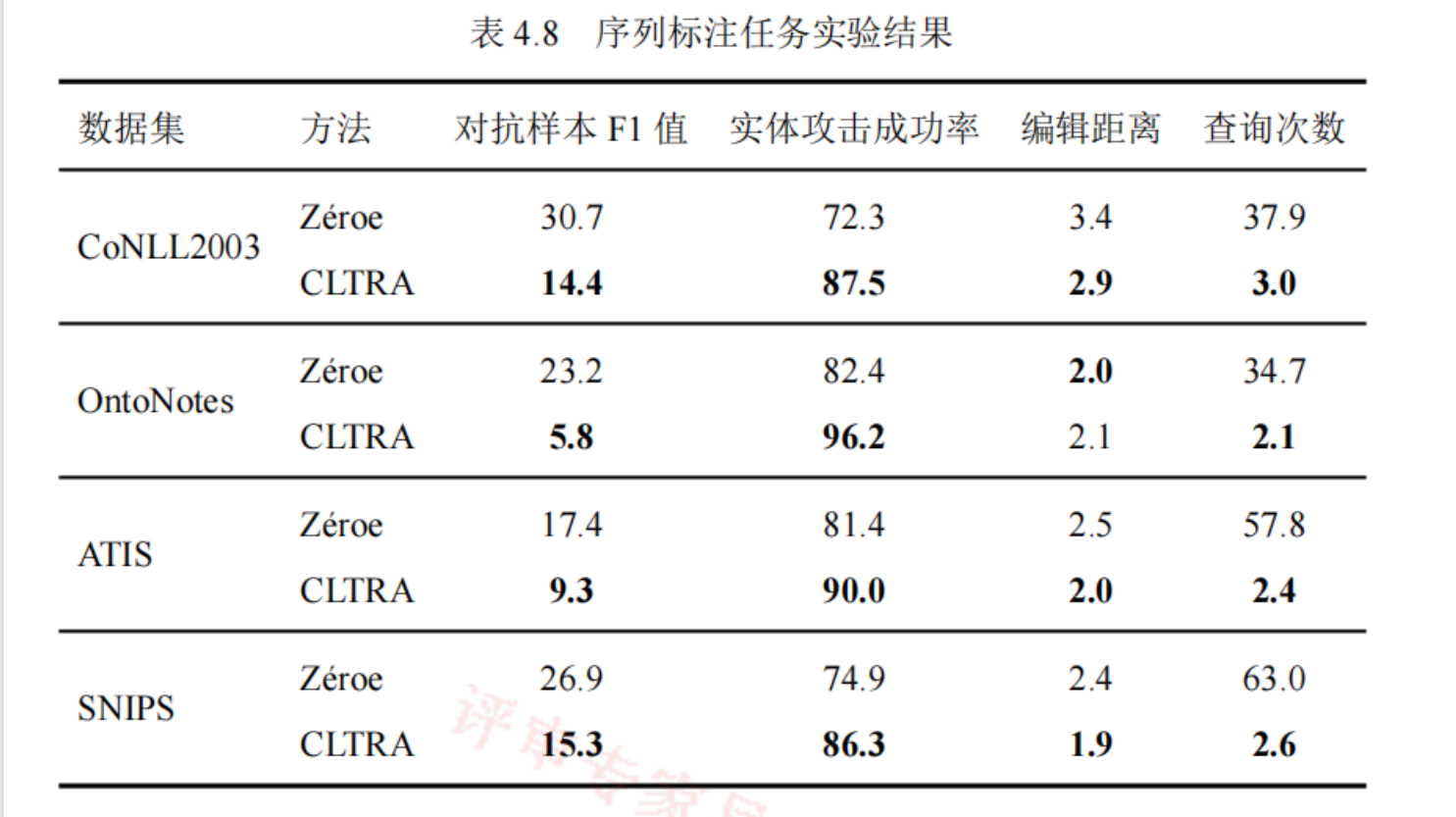
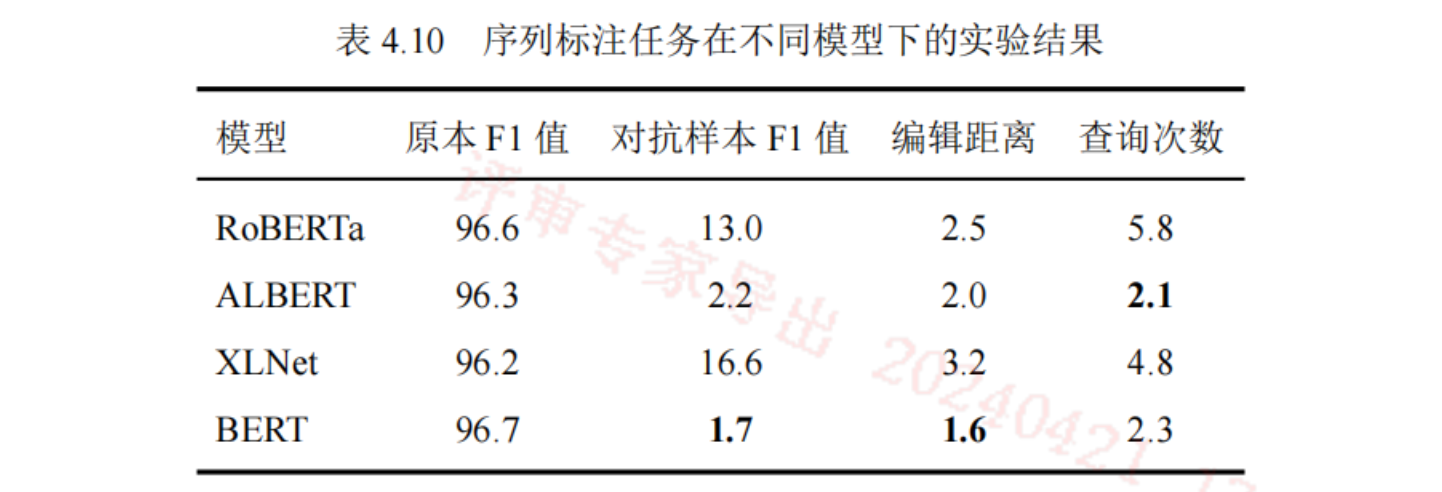
符宽限制系数和形态相似限制系数
更大的形态相似限制系数,使得文本的扰动更小,因此编辑距离变小,导致实体攻击成功率降低。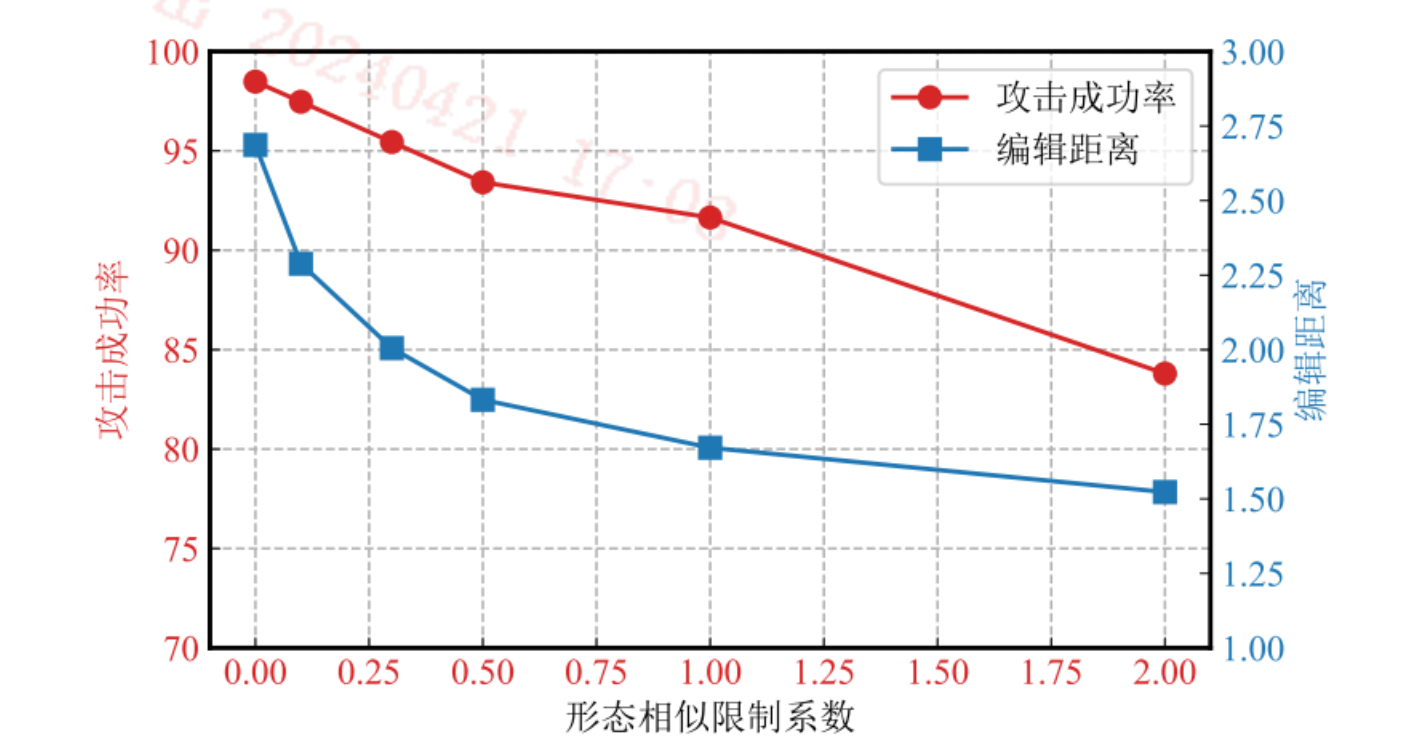
符宽限制系数对实体攻击成功率影响不大,但对编辑距离影响较大。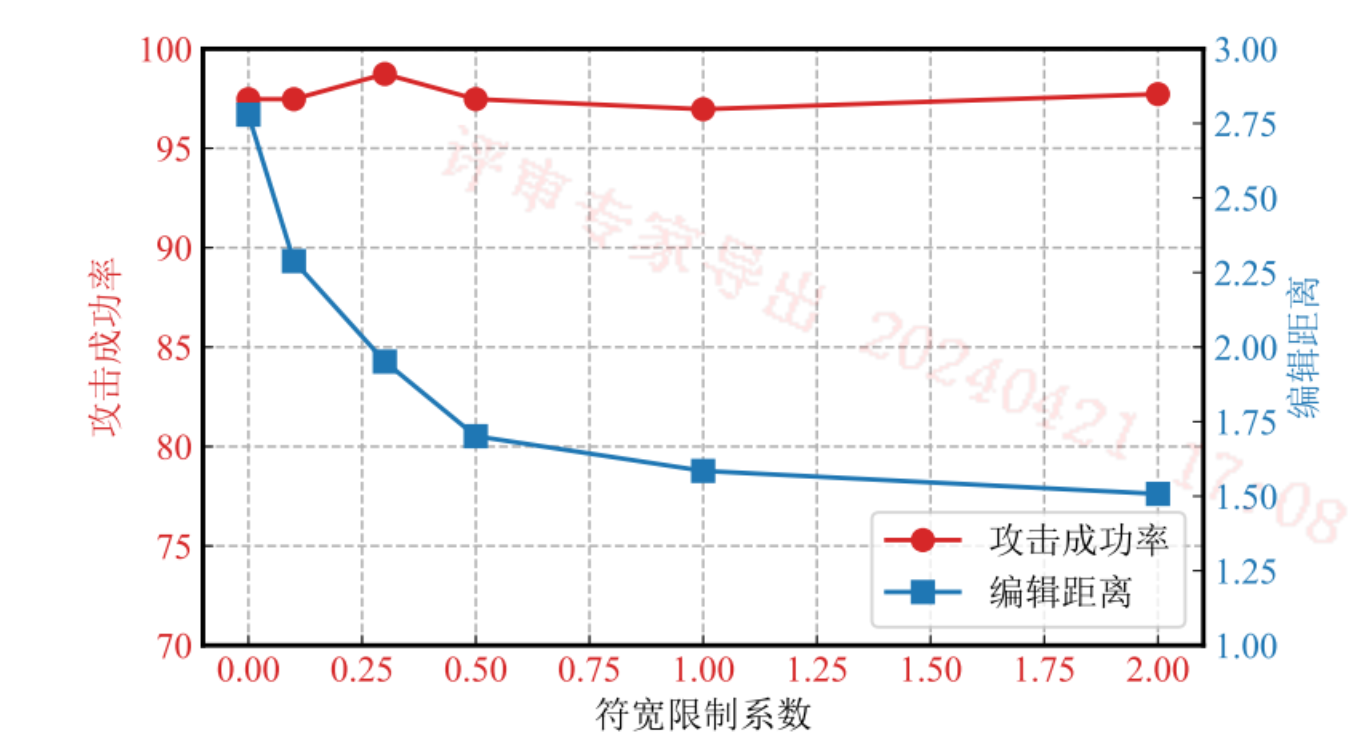
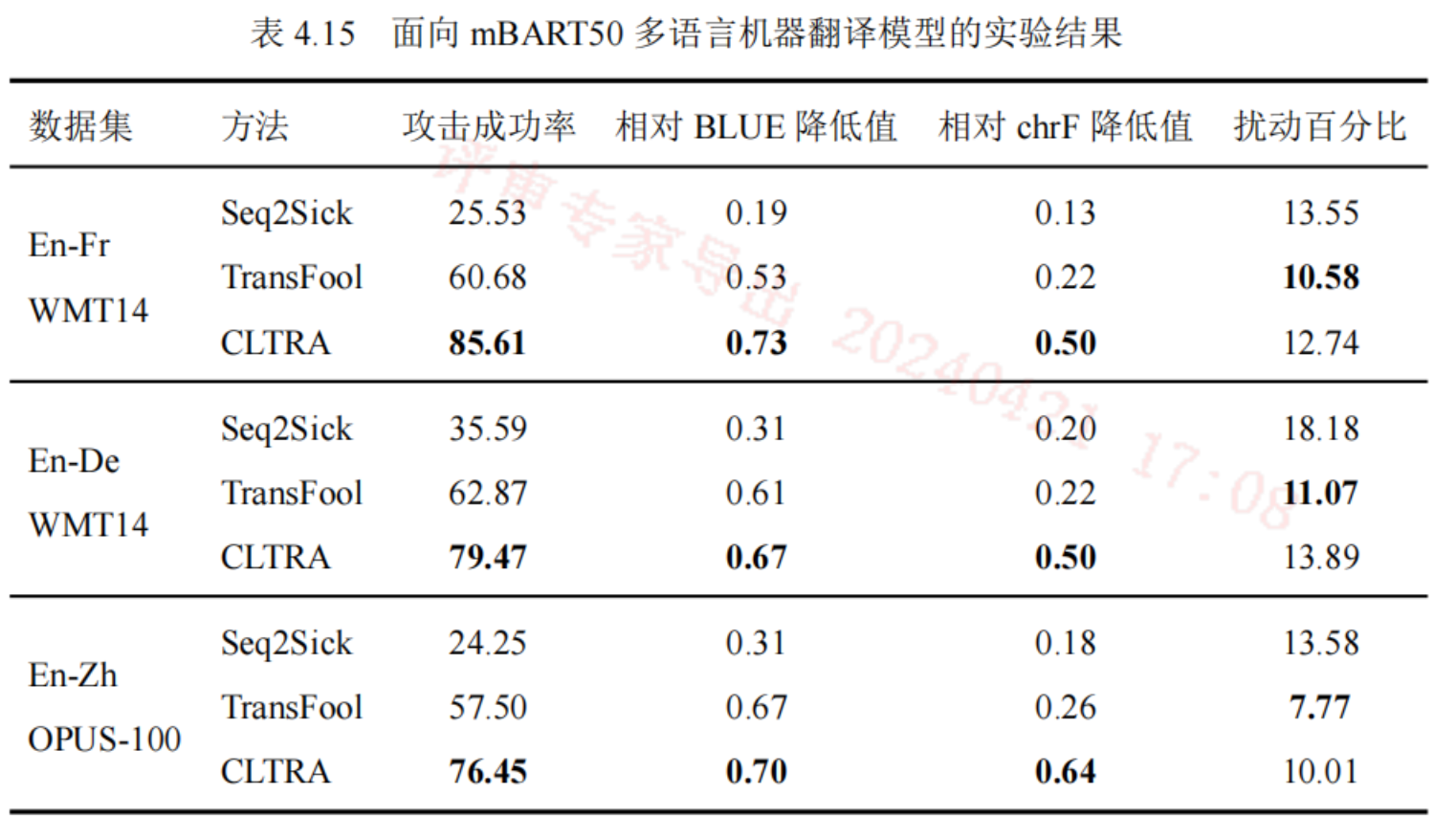
机器翻译任务
数据集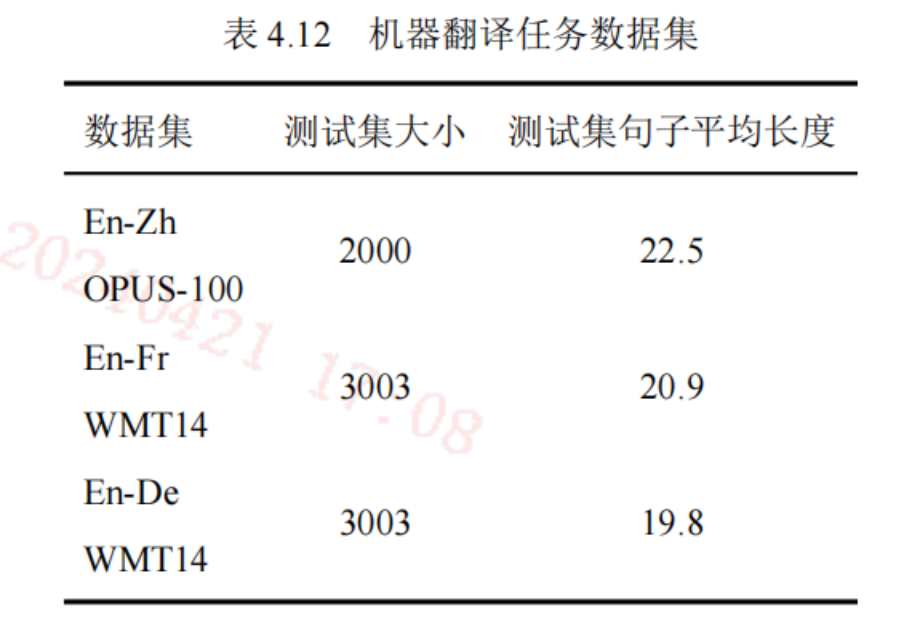
评价指标
- 攻击成功率:对抗样本生成的翻译和参考翻译的BLUE 分数降低为原来的一半以下。
- 相对BLUE降低值:整个数据集平均降低的 BLUE比例,是降低值与原来值的比。
- 相对chrF降低值:整个数据集平均降低的 chrF比例,是降低值与原来值的比。字符级别。
- 扰动百分比:对抗样本与原样本相比扰动的百分比。
基线模型
- Seq2Sick:白盒攻击方法,梯度来构造词嵌入空间的扰动,再映射回离散序列。
- TransFool:白盒攻击方法,同上,但使用了词嵌入。
实验结果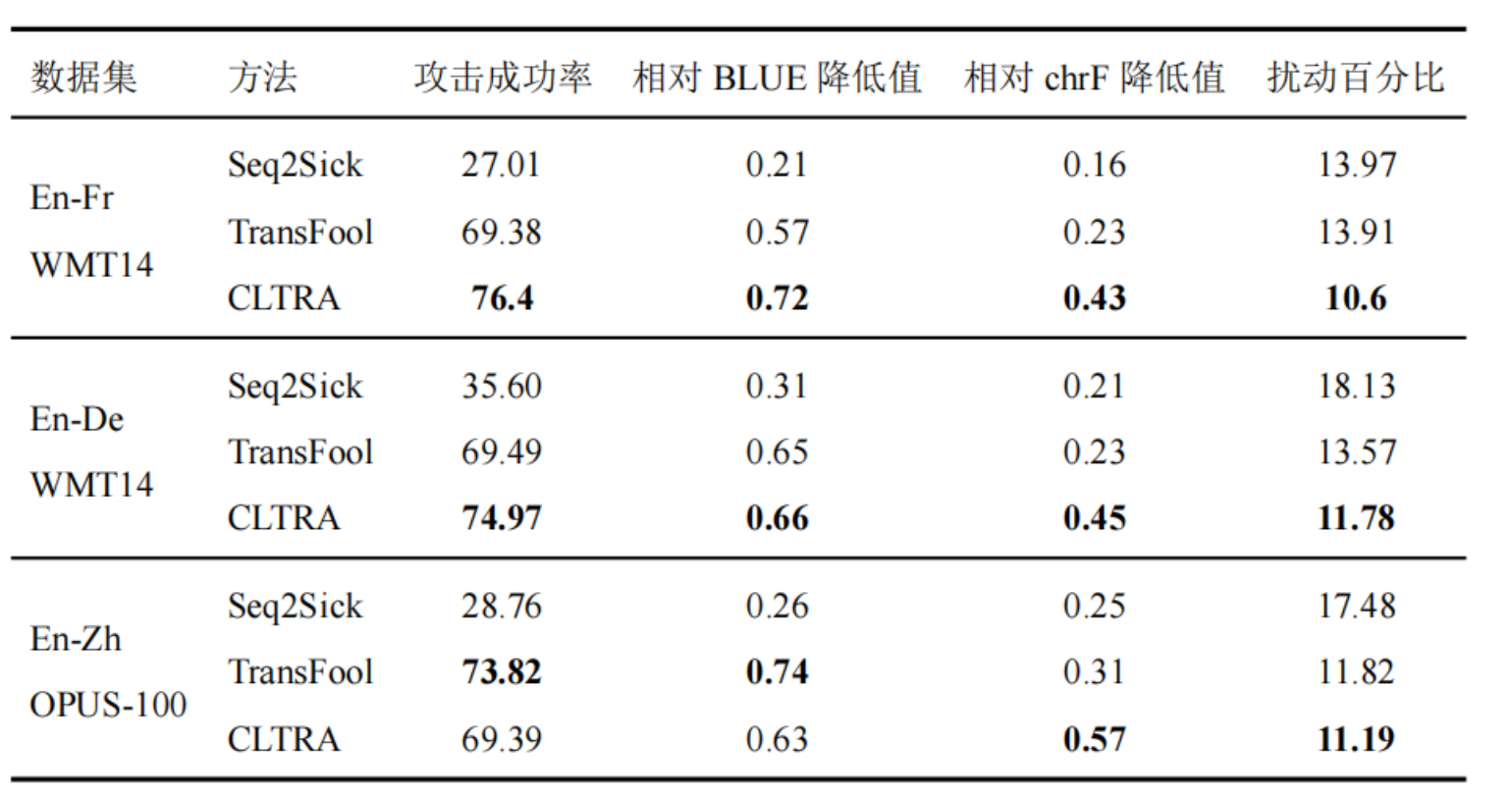
五、总结
优点
- 字符级粒度,意味着最高的相似程度,编辑距离值小,扰动范围小。
- 白盒方法,更少的模型查询次数,性能更优,充分利用了梯度。
- 普适性:在分类任务,序列标注任务,机器翻译任务上均取得了不错的效果。
- 创新型算法:可替换字符串上传算法;扰动限制损失函数
未来展望
- 拓展其他任务:对于现有大模型的安全性、鲁棒性验证。
- 面向中文:需要改造分词算法
- 如何利用对抗样本:本文提出了构造对抗样本的方法,来揭示模型的缺陷和鲁棒性。如何利用对抗样本对模型进行强化?一种方式是将对抗样本作为训练集进行对抗训练。
六、
NLP VS LLM
一些局限性:
- 感觉本篇的工作可能是之前所做的,沉淀了一段时间,是在大语言模型出现之前的(模型基本都是用的BERT,也可以从他发表在EMNLP上的时间2022年推断出),试验了一下论文中提及的几个对抗样本,对现在的大语言模型似乎无效。作者也在未来展望中提到了未来运用到大模型上的一些想法。
CASE 1:翻译任务
大语言模型可以识别错误并正确地猜测出了原文,根本骗不到大模型~
CASE 2:情感分类
大语言模型依旧可以正确判断对抗样本,并且能够帮你进行纠错,比如teruible -> terrible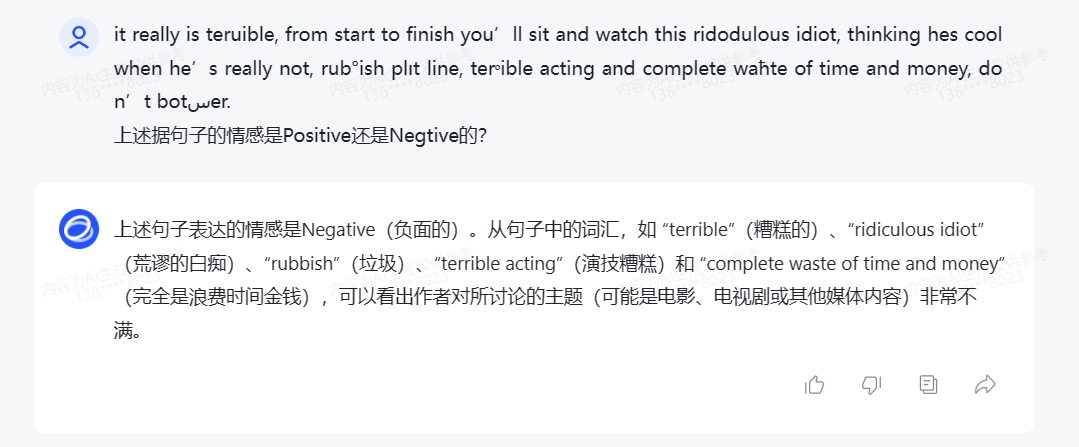
CASE 3:序列标注任务
可以正确标注,并且能够将对抗样本中的扰动 baliimore -> baltimore进行纠正
- 这篇文章我认为写的非常不错,提出了比较创新的算法,并通过详细的实验数据作为支撑,验证了其算法的高效性。(相关算法已发表在NLP领域顶会EMNLP,其有效性、真实性可保证)
- 验证了一个观点,LLM的出现让传统NLP无路可走。
- 不过值得注意的是,上述的训练集都来自领域内非常流行的公开语料库,不排除大模型使用它们进行了训练,所以才导致了对抗样本失效。
- 由于目前大模型存在安全性、可解释性、幻觉等方面的缺陷,如果能通过有效的对抗样本学习来解决上述问题,是未来大模型优化的一个点。