MIT6.830-Lab2
介绍
在这个实验任务中,你将编写一组SimpleDB的运算符,用于实现表的修改(例如,插入和删除记录)、选择、连接和聚合操作。这些操作将在Lab 1中构建的基础之上,为你提供一个能够在多个表上执行简单查询的数据库系统。
此外,在Lab 1中我们忽略了缓冲池管理的问题:我们没有处理在数据库的生命周期内引用超过内存容量的页面时会出现的问题。在Lab 2中,你将设计一种逐出策略,以将陈旧的页面从缓冲池中清除。
在这个Lab中,你不需要实现事务或锁。
提示
实现Filter和Join运算符,并验证它们相应的测试是否有效。这些运算符的Javadoc注释包含了它们应该如何工作的详细信息。我们已经为你提供了Project和OrderBy的实现,这可能有助于你理解其他运算符的工作原理。
实现IntegerAggregator和StringAggregator。在这里,你将编写实际计算在一系列输入元组中跨多个组对特定字段执行聚合的逻辑。对于计算平均值,使用整数除法,因为SimpleDB只支持整数。StringAggregator只需要支持COUNT聚合,因为其他操作对于字符串来说没有意义。
实现Aggregate运算符。与其他运算符一样,聚合运算符实现了OpIterator接口,以便将它们放入SimpleDB查询计划中。注意,Aggregate运算符的输出是每次调用next()时整个组的聚合值,聚合构造函数接受聚合和分组字段。
在BufferPool中实现与元组插入、删除和页面逐出相关的方法。目前不需要担心事务。
实现Insert和Delete运算符。与所有运算符一样,Insert和Delete实现OpIterator,接受要插入或删除的元组流,并输出一个具有整数字段的单个元组,该字段指示插入或删除的元组数量。这些运算符将需要调用BufferPool中实际修改磁盘上页面的适当方法。确保插入和删除元组的测试正常工作。
请注意,SimpleDB 不实现任何一种一致性或完整性检查,因此可以将重复的记录插入文件中,并且无法强制执行主键或外键约束。
在这一点上,你应该能够通过 systemtest 目标来通过测试,这是这个实验的目标。
你还将能够使用提供的 SQL 解析器对你的数据库运行 SQL 查询!详见第2.7节的简短教程。
最后,你可能会注意到在这个实验中,迭代器扩展了 Operator 类而不是实现 OpIterator 接口。由于next/hasNext的实现通常是重复的、烦人的,并且容易出错,Operator 通用地实现了这个逻辑,只需要你实现一个更简单的 readNext。请随意使用这种风格的实现,或者如果你更喜欢,只需实现 OpIterator接口。要实现 OpIterator 接口,请从迭代器类中删除 extends Operator,并在其位置上放置 implements OpIterator。
任务
Filter and Join
回顾一下,SimpleDB 的 OpIterator 类实现了关系代数的操作。现在,你将实现两个运算符,使你能够执行比表扫描更有趣一些的查询。
Filter(过滤器):该运算符仅返回满足作为其构造函数的一部分指定的
Predicate的元组。因此,它会过滤掉不符合Predicate的任何元组。Join(连接):该运算符根据作为其构造函数的一部分传递的
JoinPredicate连接其两个子运算符的元组。我们仅需要一个简单的嵌套循环连接,但你可以探索更有趣的连接实现。在实验报告中描述你的实现。
Exercise 1
Implement the skeleton methods in:
- src/java/simpledb/execution/Predicate.java
- src/java/simpledb/execution/JoinPredicate.java
- src/java/simpledb/execution/Filter.java
- src/java/simpledb/execution/Join.java
至此,你的代码应该能通过单元测试PredicateTest, JoinPredicateTest, FilterTest和JoinTest。 进一步地,你应该可以通过系统测试FilterTest 和 JoinTest。
Aggregates
附加的SimpleDB操作符实现了带有GROUP BY子句的基本SQL聚合。您应该实现五个SQL聚合(COUNT,SUM,AVG,MIN,MAX)并支持分组。您只需要支持单个字段的聚合,以及按单个字段分组。
为了计算聚合,我们使用一个聚合器(Aggregator)接口,该接口将一个新元组合并到现有聚合计算中。在构造过程中,聚合器被告诉应该使用什么操作进行聚合。随后,客户端代码应该对子迭代器中的每个元组调用Aggregator.mergeTupleIntoGroup()。合并所有元组后,客户端可以检索聚合结果的OpIterator。除非group by字段的值是Aggregator.NO_GROUPING,否则结果中的每个元组都是(groupValue,aggregateValue)的形式,在这种情况下,结果是单个(aggregateValue)形式的元组。
请注意,此实现需要与不同组的数量成线性的空间。在本实验中,您不需要担心组数超过可用内存的情况。
Exercise 2
实现下面类中的方法:
- src/java/simpledb/execution/IntegerAggregator.java
- src/java/simpledb/execution/StringAggregator.java
- src/java/simpledb/execution/Aggregate.java
此时你的代码应该能够通过单元测试 IntegerAggregatorTest, StringAggregatorTest, and AggregateTest。进一步地,你应该能够通过AggregateTest系统测试。
HeapFile Mutability
现在,我们将开始实现支持修改表的方法。我们从单个页面和文件的级别开始。有两组主要的操作:添加元组和删除元组。
删除元组:要删除一个元组,您需要实现deleteTuple方法。元组包含RecordIDs,这允许您找到它们所在的页面,因此这只是定位属于元组的页面并适当修改页面的标头。
添加元组:HeapFile.java中的insertTuple方法负责将元组添加到堆文件中。要向HeapFile添加新元组,您需要找到一个具有空槽的页面。如果在HeapFile中不存在这样的页面,则需要创建一个新页面并将其追加到磁盘上的物理文件中。您需要确保元组中的RecordID被正确更新。
Exercise 3
实现以下类中的方法:
- src/java/simpledb/storage/HeapPage.java
- src/java/simpledb/storage/HeapFile.java
(Note that you do not necessarily need to implement writePage at this point).
要实现HeapPage,您需要修改头部位图以支持insertTuple()和deleteTuple()等方法。您可能会发现我们在实验1中要求您实现的getNumEmptySlots()和isSlotUsed()方法作为有用的抽象。请注意,有一个markSlotUsed方法作为一个抽象,用于修改页面标头中元组的填充或清除状态。
请注意,HeapFile.insertTuple()和HeapFile.deleteTuple()方法重要的一点是要使用BufferPool.getPage()方法访问页面;否则,在下一个实验中,您对事务的实现可能不会正常工作。
实现类src/simpledb/BufferPool.java中的方法:
- insertTuple()
- deleteTuple()
这些方法应该调用属于被修改表的HeapFile中的适当方法(这种额外的间接性是为了在将来支持其他类型的文件,比如索引)。
在这一点上,您的代码应该通过HeapPageWriteTest和HeapFileWriteTest以及BufferPoolWriteTest中的单元测试。
Insertion and deletion
现在您已经编写了所有用于添加和删除元组的HeapFile机制,接下来您将实现插入Insert和删除Delete运算符。
对于实现插入和删除查询的计划,最顶层的运算符是一个特殊的插入Insert或删除Delete运算符,它修改磁盘上的页面。这些运算符返回受影响的元组数量。通过返回包含计数的单个元组来实现这一点,该元组包含一个整数字段。
插入(Insert):该运算符将从其子运算符读取的元组添加到其构造函数中指定的tableid。它应该使用BufferPool.insertTuple()方法来执行此操作。
删除(Delete):该运算符将从其子运算符读取的元组从其构造函数中指定的tableid中删除。它应该使用BufferPool.deleteTuple()方法来执行此操作。
Exercise 4
实现下面类中的方法:
- src/java/simpledb/execution/Insert.java
- src/java/simpledb/execution/Delete.java
在这一点上,您的代码应该通过 InsertTest 。我们没有提供单元测试对于Delete。进一步的你应该能够通过单元测试InsertTest and DeleteTest。
Page eviction
在Lab 1中,我们没有正确观察由构造函数参数numPages定义的缓冲池中最大页面数的限制。现在,您将选择一个页面驱逐策略,并对任何先前读取或创建页面的代码进行修改,以实现您的策略。
当缓冲池中存在超过numPages个页面时,在加载下一个页面之前,应该从缓冲池中驱逐一个页面。对于驱逐策略的选择取决于您;并不需要实现过于复杂的策略。在实验文档中描述您的策略。
请注意,BufferPool要求您实现flushAllPages()方法。这在实际实现缓冲池时是不需要的。然而,出于测试目的,我们需要这个方法。您不应该从任何真实的代码中调用这个方法。
由于我们已经实现了ScanTest.cacheTest的方式,您需要确保您的flushPage和flushAllPages方法不从缓冲池中驱逐页面,以确保通过这个测试。
flushAllPages应该调用BufferPool中所有页面的flushPage,并且flushPage应该将任何脏页面写入磁盘并将其标记为非脏,同时保留在缓冲池中。
唯一应该从缓冲池中移除页面的方法是evictPage,它应该在驱逐任何脏页面时调用flushPage。
Exercise 5
在以下类中实现 flushPage() 方法和其他额外的辅助方法
- src/java/simpledb/storage/BufferPool.java
如果您在上面的HeapFile.java中没有实现writePage(),则您还需要在这里进行实现。最后,您还应该实现discardPage()以从缓冲池中移除页面而不将其刷新到磁盘。在这个实验中,我们不会测试discardPage(),但它将在未来的实验中变得必要。
在这一点上,您的代码应该通过EvictionTest系统测试。
由于我们不会检查任何特定的驱逐策略,这个测试通过创建一个包含16个页面的BufferPool来进行工作(注意:虽然DEFAULT_PAGES是50,但我们初始化BufferPool时使用的是更少的页面!),然后扫描一个具有远多于16个页面的文件,看看JVM的内存使用是否增加了超过5 MB。如果您没有正确实现驱逐策略,您将无法驱逐足够的页面,从而超过了大小限制,导致测试失败。
您现在已经完成了这个实验。做得好!
Query walkthrough
以下代码实现了两个表之间的简单连接查询,每个表都由三列整数组成。 (文件 some_data_file1.dat 和 some_data_file2.dat 是该文件中页面的二进制表示)。此代码等效于以下SQL语句:
1 | SELECT * |
为了更全面地了解查询操作的示例,您可能会发现浏览连接、筛选和聚合的单元测试对您有帮助。
1 | package simpledb; |
两个表都有三个整数字段。为了表示这一点,我们创建了一个TupleDesc对象,并向其传递了一个Type对象数组,指示字段类型,以及一个String对象数组,指示字段名称。创建了TupleDesc之后,我们初始化了两个表示表的HeapFile对象。一旦创建了这些表,我们将它们添加到Catalog中(如果这是一个已经运行的数据库服务器,我们将加载这个目录信息;我们只需要为这个测试加载这些信息)。
一旦我们完成了数据库系统的初始化,我们就创建了一个查询计划。我们的计划包括两个SeqScan运算符,它们从磁盘上的每个文件中扫描元组,连接到第一个HeapFile上的一个Filter运算符,连接到一个Join运算符,根据JoinPredicate连接表中的元组。通常,这些运算符被实例化为引用适当的表(在SeqScan的情况下)或子运算符(在Join的情况下)。测试程序然后重复调用Join运算符上的next,Join运算符依次从其子运算符中拉取元组。当元组从Join输出时,它们将在命令行上打印出来。
Query Parser
我们为您提供了一个用于SimpleDB的查询解析器,您可以在完成本实验中的练习后使用它来编写和运行对数据库的SQL查询。
第一步是创建一些数据表和一个目录。假设您有一个名为data.txt的文件,其内容如下:
1 | 1,10 |
您可以使用 convert 命令将其转换为 SimpleDB 表(确保先键入 ant!):
1 | java -jar dist/simpledb.jar convert data.txt 2 "int,int" |
这样就创建了一个文件 data.dat。除了表格的原始数据外,两个附加参数还指定每条记录有两个字段,其类型分别为 int 和 int。
接下来,创建一个目录文件 catalog.txt,内容如下:
1 | data (f1 int, f2 int) |
这会告诉 SimpleDB 有一个表,即 data(存储在 data.dat),其中有两个名为 f1 和 f2 的整数字段。
最后,调用解析器。你必须从命令行运行 java(ant 不能在交互式目标下正常工作):
1 | java -jar dist/simpledb.jar parser catalog.txt |
你会看到如下类似的输出:
1 | Added table : data with schema INT(f1), INT(f2), |
最后,您可以运行查询:
1 | SimpleDB> select d.f1, d.f2 from data d; |
解析器相对功能齐全(包括对SELECT、INSERT、DELETE和事务的支持),但存在一些问题,并且不一定提供完全详细的错误消息。以下是一些需要注意的限制:
- 必须在每个字段名前加上其表名,即使字段名是唯一的(可以使用表名别名,如上面的示例,但不能使用AS关键字)。
- WHERE子句中支持嵌套查询,但FROM子句中不支持。
- 不支持算术表达式(例如,不能对两个字段求和)。
- 最多允许一个GROUP BY和一个聚合列。
- 不允许使用IN、UNION和EXCEPT等面向集合的运算符。
- 只允许在WHERE子句中使用AND表达式。
- 不支持UPDATE表达式。
- 允许使用字符串运算符LIKE,但必须完全写出(即,不允许使用Postgres的波浪符[~]缩写)。
实现
Exercise1-2
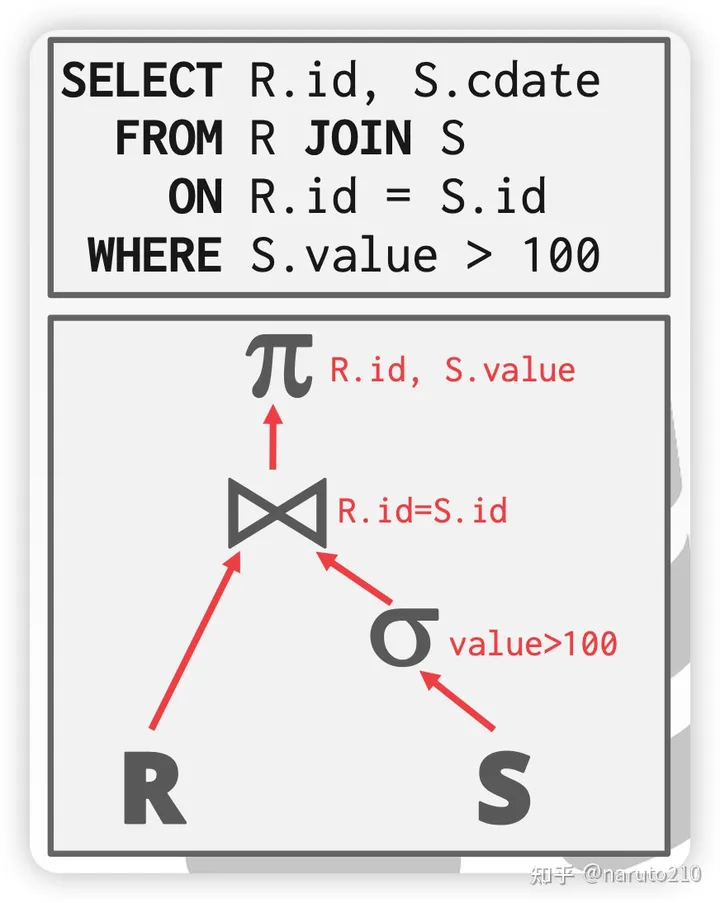
需要理解各个运算符的规则。本质上所有的运算符都是在处理Tuple,比如Filter运算符会过滤掉不符合条件的Tuple。Join运算符会连接多个输入流,并保留满足条件的。比如t1.oid = t2.oid。运算符自顶向下,且都继承了OpIterator。OpIterator是一个迭代器,可以对Tuple进行迭代。
上层运算符调用Open方法开始接收其子运算符输入的Tuple。注意上层运算符的Open方法中,先调用了其子运算符的Open,所以整个过程是递归进行的,自下而上(如图所示)。底层运算符将Tuple源源不断地传递到它的上层,上层对Tuple进行特定处理(过滤、聚合等)后,继续向上传递。直至顶层出口。
Example
1 | SeqScan ss1 = new SeqScan(tid, table1.getId(), "t1"); |
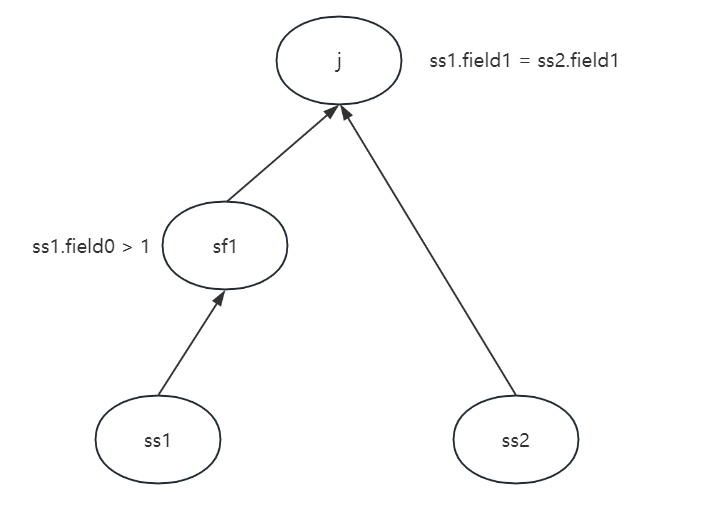
Exercise3-5
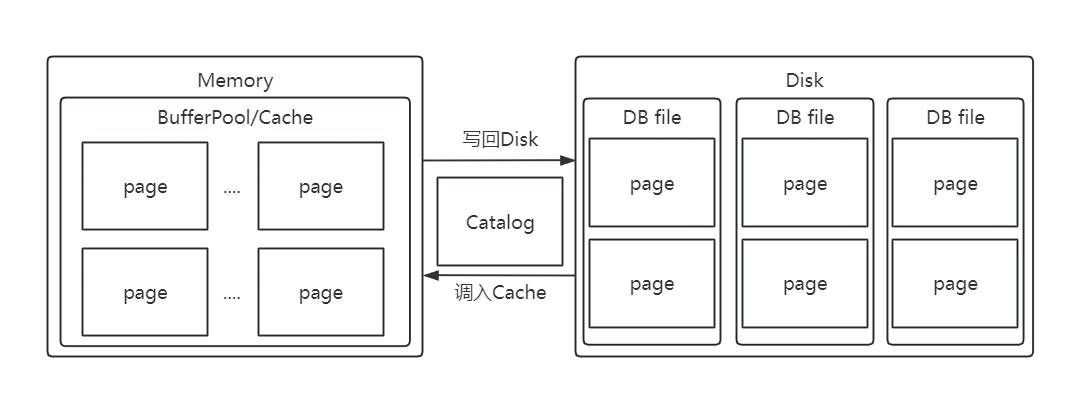
注意:
- 对
Page的操作必须在BufferPool中操作,因为其后续提供了锁机制,脏页的处理。 - 对内存(也就是
BufferPool中)中的Page修改后,其存储在磁盘上的数据(以DB File形式)并不会同步修改,更具体地,内存中的Page只是一个java对象。修改后,该Page被标记为脏页,并驻留在BufferPool中,因此后续其他操作需要读取该页时,可以读取到最新修改。(但这里的隔离级别是读未提交)
Debug
操作符实现的不正确,是否应该在open()的时候从child()中读入所有的tuples数据,并存放到一个支持迭代的容器中?
对于OrderBy:这个是必须的,因为需要对所有tuples进行排序。上层操作符通过fetchNext就能从上述容器中获取结果。如果通过fetchNext一次拿一个数据,那就无法实现全局排序了。
对于join:不能在open的时候加载它child的所有数据,考虑一张非常大的表,直接全部加载到内存中会OOM,因此必须通过child.fetchNext一条一条的拿取。
1 | protected Tuple fetchNext() throws TransactionAbortedException, DbException { |
对于大部分其他操作符,也必须如此。
对于Aggregator:题目说了不需要考虑组数超过可用内存,因此直接存储所有child传递的tuple后,一起处理即可。但只需要存储tuple中分组字段和聚合字段即可。其他属性不需要存,节省空间。