Lab 3.KVRaft
Lab 3 - KVRaft
介绍
在本实验中,您将使用lab 2 中的 Raft 库构建容错的键/值存储服务。您的键/值服务将是一个复制状态机,由多个使用 Raft 进行复制的键/值服务器组成。只要大部分服务器还活着并能通信,那么即使出现其他故障或网络分区,您的键/值服务也能继续处理客户端请求。lab 3 结束后,您将实现 Raft 交互图中所示的所有部分(服务器、服务和 Raft)。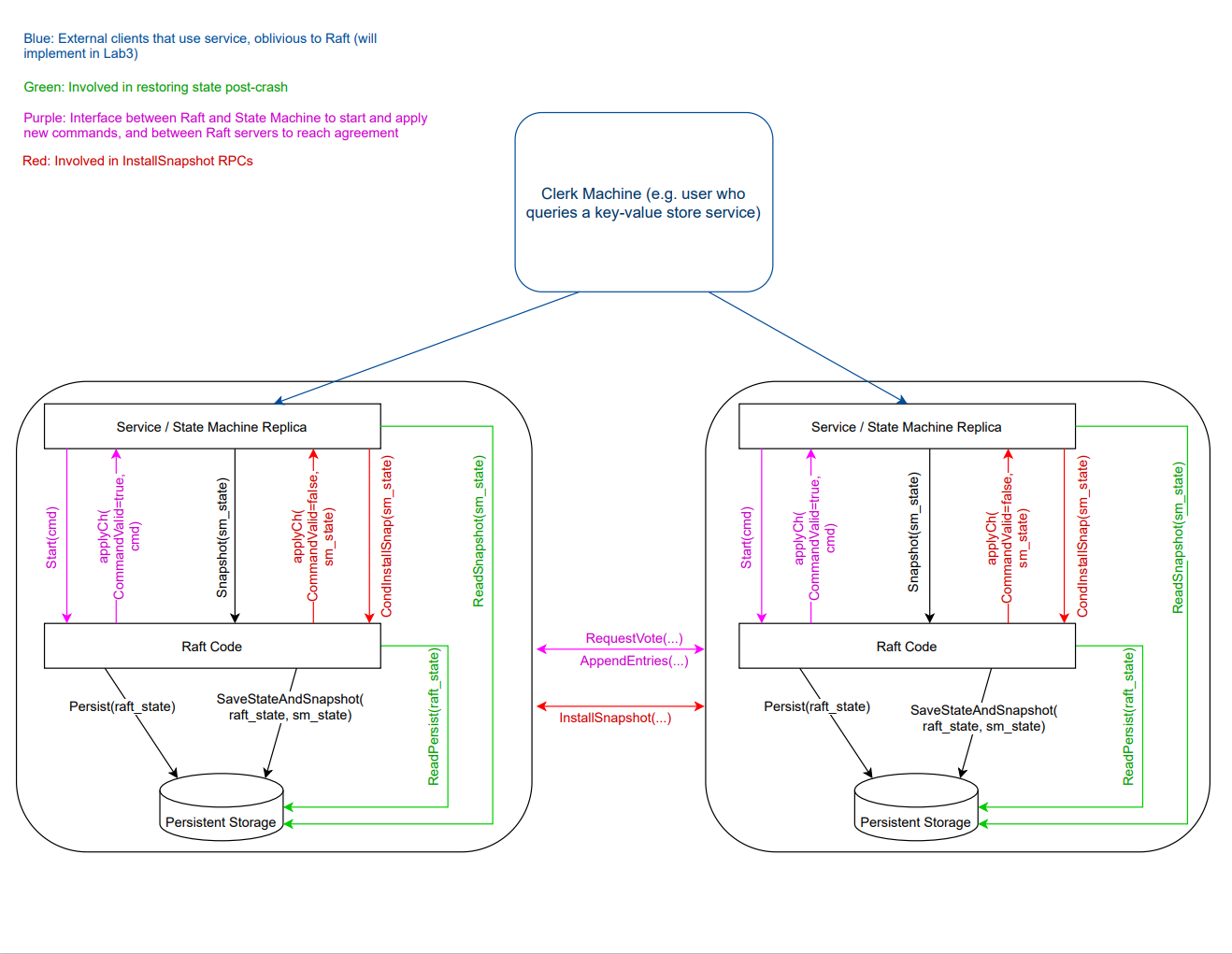
客户端可以向键/值服务发送三种不同的 RPC:Put(key,value)、Append(key,arg) 和 Get(key)。该服务维护一个简单的键/值对数据库。键和值都是字符串。Put(key,value)会替换数据库中特定键的值,Append(key,arg)会将 arg 追加到键的值中,而 Get(key) 则会获取键的当前值。对于不存在的键,Get 应返回空字符串。对不存在的键进行Append 的操作应与 Put 类似。每个客户端都通过一个使用 Put/Append/Get 方法的Clerk与服务对话。Clerk负责管理与服务器之间的 RPC 交互。
您的服务必须确保对Clerk Get/Put/Append 方法的应用程序调用是可线性化的。如果逐次调用,Get/Put/Append 方法的作用应如同系统只有一份状态副本,每次调用都应遵守前一轮调用对状态的修改。对于并发调用,返回值和最终状态必须与按一定顺序逐次执行的操作相同。如果调用在时间上重叠,则属于并发调用:例如,客户机 X 调用 Clerk.Put(),客户机 Y 调用 Clerk.Append(),然后客户机 X 的调用返回。一个调用必须观察所有在该调用开始前已完成的调用的效果。
线性化对应用程序来说非常方便,因为它是一次处理一个请求的单个服务器的行为。例如,如果一个客户端从服务中成功响应了一个更新请求,那么其他客户端随后启动的读取就能保证看到该更新的效果。对于单个服务器来说,提供线性化相对容易。如果服务是复制的,就比较困难,因为所有服务器都必须为并发请求选择相同的执行顺序,必须避免使用不是最新的状态回复客户端,而且必须在故障后以保留所有已确认客户端更新的方式恢复状态。
本实验分为两部分。在 A 部分中,您将使用 Raft 实现来实现键/值服务,但不使用快照。在 B 部分中,您将使用Lab 2D 中的快照实现,这将允许 Raft 丢弃旧的日志条目。请在各部分的截止日期前提交。
您应该阅读 Raft 的扩展论文,尤其是第 7 和第 8 节。如需更广阔的视角,请参阅 Chubby、Paxos Made Live、Spanner、Zookeeper、Harp、Viewstamped Replication 和 Bolosky et al.
开始
我们在 src/kvraft 中为您提供了骨架代码和测试。您需要修改 kvraft/client.go、kvraft/server.go 和 kvraft/common.go
Part A:不带快照的键/值服务
介绍
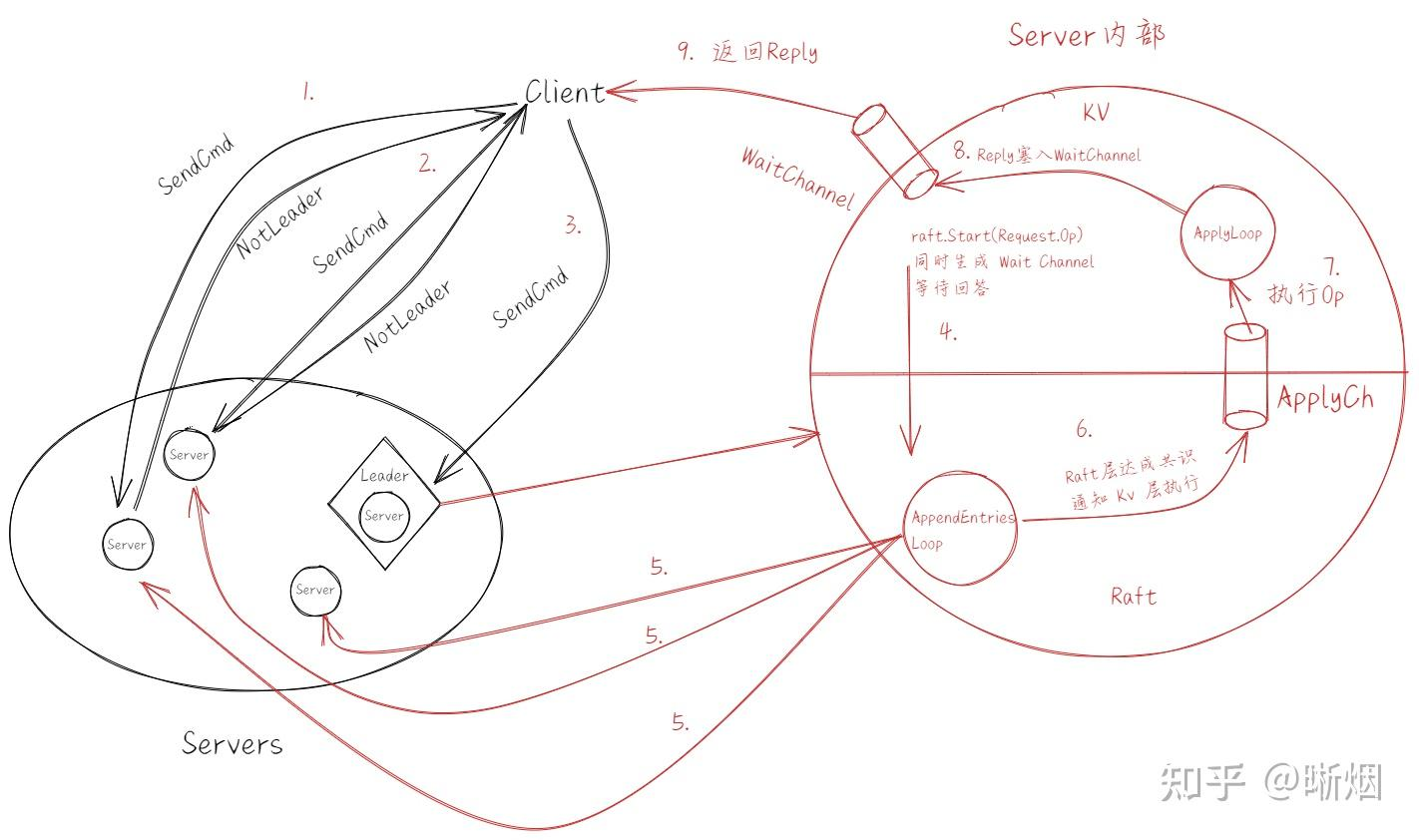
每个你的键/值服务器(”kvservers”)都有一个关联的 Raft peer。办事员向关联 Raft Leader 的 kvserver 发送 Put()、Append() 和 Get() RPCs。kvserver 代码将 Put/Append/Get 操作提交给 Raft,这样 Raft 日志中就保存了一系列 Put/Append/Get 操作。所有 kvserver 都会按顺序执行 Raft 日志中的操作,并将这些操作应用到它们的键/值数据库中;这样做的目的是让服务器保持键/值数据库的相同副本。
Clerk有时不知道哪个 kvserver 是 Raft 的Leader。如果Clerk向错误的 kvserver 发送了 RPC,或者无法联系到该 kvserver,办事员就应该换一个 kvserver 重试。如果 key/value 服务将操作提交到了它的 Raft 日志(并因此将操作应用到了 key/value 状态机),那么Leader就会通过响应办事器的 RPC 来向Clerk报告结果。如果操作提交失败(例如,领导者被替换),服务器就会报错,Clerk就会换一个服务器重试。
您的 kvservers 不应直接通信;它们只应通过 Raft 进行交互。
任务
您的首要任务是实施一个解决方案,在没有丢弃报文和服务器故障的情况下生效。
您需要在 client.go 中的 Clerk Put/Append/Get 方法中添加 RPC 发送代码,并在 server.go 中实现 PutAppend() 和 Get() RPC 处理程序。这些处理程序应使用 Start() 在 Raft 日志中输入 Op;您应在 server.go 中填写 Op 结构定义,以便描述 Put/Append/Get 操作。每个服务器都应在 Raft 提交 Op 命令(即出现在 applyCh 上的命令)时执行这些命令。RPC 处理程序应在 Raft 提交 Op 命令时注意到,然后回复 RPC。
当您可靠地通过测试中的第一个测试时,您就完成了这项任务:”一个客户端”。
提示:
- 调用
Start()后,kvservers 需要等待 Raft 完成协议。已达成一致意见的命令会发送到applyCh。当PutAppend()和Get()处理程序使用Start()向 Raft 日志提交命令时,你的代码需要继续读取applyCh。小心 kvserver 与其 Raft 库之间的死锁。 - 您可以在 Raft
ApplyMsg中添加字段,也可以在 Raft RPC(如 AppendEntries)中添加字段,但这对大多数实现来说并非必要。 - 如果
Get()RPC 不属于多数数据,则 kvserver 不应完成该Get()RPC(这样它就不会提供过期数据)。一个简单的解决方案是在 Raft 日志中输入每一次Get()(以及每一次Put()和Append())。您不必执行第 8 节所述的只读操作优化。 - 最好从一开始就添加锁,因为避免死锁的需要有时会影响整个代码的设计。使用 go test -race 检查代码是否无竞赛。
现在,您应该修改解决方案,以便在网络和服务器出现故障时继续运行。你将面临的一个问题是,Clerk可能不得不多次发送 RPC,直到找到一个作出积极回复的 kvserver。如果Leader在向 Raft 日志提交条目后发生故障,Clerk可能收不到回复,因此可能会重新向另一个领导者发送请求。每次调用 Clerk.Put() 或 Clerk.Append() 都只需执行一次,因此必须确保重新发送不会导致服务器执行两次请求。
添加代码以处理故障,并处理重复的Clerk请求,包括Clerk向某个任期的 kvserver 领导者发送请求,在等待回复时超时,然后向另一个学期的新Leader重新发送请求的情况。请求应该只执行一次。您的代码应通过 go test -run 3A -race 测试。
提示:
- 您的解决方案需要处理这样一种情况:Leader为
Clerk的 RPC 调用了Start(),但在请求提交到日志之前失去了领导权。在这种情况下,你应该安排Clerk向其他服务器重新发送请求,直到找到新的领导者。一种方法是让服务器通过注意到Start()返回的索引中出现了不同的请求,或者 Raft 的任期发生了变化,来检测到自己失去了领导权。如果前领导者是自己分区的,它就不会知道新的领导者;但同一分区的任何客户端也无法与新的领导者对话,因此在这种情况下,服务器和客户端可以无限期地等待,直到分区愈合。 - 您可能需要修改您的 Clerk,以便记住哪台服务器是上一个 RPC 的领导者,并将下一个 RPC 首先发送到该服务器。这样可以避免浪费时间在每一次 RPC 中寻找领导者,从而帮助你快速通过某些测试。
- 您需要唯一标识客户操作,以确保键/值服务对每个操作只执行一次。
- 您的重复检测方案应能迅速释放服务器内存,例如,每次 RPC 都意味着客户端已看到前一次 RPC 的回复。假设客户端一次只调用一个
Clerk也没有问题。
1 | $ go test -run 3A |
实现
超时机制
client需要防止给过时的Leader发送请求,导致无限等待。可以尝试轮流给每个节点都发送请求直到返回OK,并记录当前节点ID,认为它是当前的Leader,下次优先向该节点发送请求,加以优化。
1 | func (ck *Clerk) sendCommand(key string,value string,opType OpType) string { |
请求重复执行server需要确保同一个请求不会被重复执行。并且raft可以提交同一个操作日志多次,但只能执行一次。即使是幂等的。实现线性化语义,就需要保证日志仅被执行一次,即它可以被 commit 多次,但一定只能 apply 一次。否则就不满足线性一致性。
考虑如下操作:
A:put(x,1)
B:get(x) -> put(x,2)
在线性一致性系统中(B读取到的值,x的最终值)可能为(1,2)、(0,2)、(0,1)
如果A的put(x,1)被apply了多次,即使它是幂等性操作,也会导致上述结果为(1,1)。也就是当执行了
A:put(x,1)->B:get(x)->B:put(x,2)->A:put(x,1)。这不符合线性一致性系统。
一个出乎意料的BUG
1 | func (kv *KVServer) applier() { |
加了select - case - default运行变得很慢
对于在for不断循环的select语句,不宜使用default语句,否则会一直循环的执行default语句,引起cpu占用过高的现象。如果不加default,select就会一直阻塞,直到其中一个通道准备就绪,并不会一直死循环。
Part B:具有日志压缩功能的键/值服务
介绍
目前的情况是,你的 key/value 服务器并没有调用 Raft 库的 Snapshot() 方法,因此重启的服务器必须重放完整的持久化 Raft 日志才能恢复其状态。现在,你将修改 kvserver,以便与 Raft 合作,使用 Lab 2D 中的 Raft Snapshot() 来节省日志空间并缩短重启时间。
测试会将 maxraftstate 传递给 StartKVServer()。maxraftstate 表示持久化 Raft 状态允许的最大大小,单位为字节(包括日志,但不包括快照)。应将 maxraftstate 与 persister.RaftStateSize() 进行比较。每当键/值服务器检测到 Raft 状态的大小接近这个阈值时,它就应该调用 Raft 的快照功能来保存快照。maxraftstate 适用于 Raft 传递给 persister.SaveRaftState() 的 GOB 编码字节。
修改 kvserver,使它能在持久化的 Raft 状态过大时检测到,然后将快照交给 Raft。当 kvserver 服务器重新启动时,它应从 persister 读取快照,并从快照中恢复其状态。
提示:
- 思考 kvserver 应在何时对其状态进行快照,以及快照中应包含哪些内容。Raft 会使用
SaveStateAndSnapshot()将每个快照连同相应的 Raft 状态一起存储到persister对象中。您可以使用 ReadSnapshot() 读取最新存储的快照。 - kvserver 必须能检测到日志中跨检查点的重复操作,因此快照中必须包含用于检测重复操作的任何状态。
- 将快照中存储的结构的所有字段大写。
- 您的 Raft 库中可能存在本实验室暴露的错误。如果您修改了 Raft 实现,请确保它能继续通过Lab 2 的所有测试。
- Lab 3 测试所需的合理时间为 400 秒实际时间和 700 秒 CPU 时间。此外,
go test -run TestSnapshotSize实际耗时应少于 20 秒。
1 | $ go test -run 3B -race |
思路
快照的目的:
- 通过保存当前状态,压缩日志信息,将已经提交到状态机的日志废弃。
- 快速恢复,当Server崩溃后,可以快速通过快照中存储的“较新”状态来恢复,而不必对所有日志进行重放。只需要重放快照lastIncludedIndex之后的日志即可。
首先需要考虑对于Raft协议之上的状态机哪些数据需要放到快照中。
- 状态机的状态数据:这毫无疑问是肯定需要进行快照的,因为快照的目的就是通过状态取代日志信息。
- 状态机存储的客户端回复缓存:这使得状态机在崩溃恢复后,能够知道回复客户端的情况,避免出现重复执行指令,保证幂等性。考虑如下情况:客户端A发送了一个PUT/APPEND请求,Server执行成功了(缓存中有该请求了),但还未来得及回复客户端前,就崩溃了。客户端超时未收到答复会进行重试,那么当Server重启后,如果没保存客户端回复缓存的话,会再次执行请求,破坏了幂等性原则。
快照的流程:
- Servers认为需要对状态机进行一次快照(可能是日志数量/大小达到了某个阈值)
- 生成快照,并通过调用Raft的
Snapshot()方法通知Raft执行快照。 - 更新状态机必要的数据,lastSnapshot更新为lastApplied,表示快照中最后提交的日志索引
服务器安装快照流程:
- 某个服务器可能由于停机很久,导致状态落后很多。那么Leader会发送它最新的快照来让其快速恢复。
- Raft层收到Leader发来的快照后,先更新Raft中的状态,然后向上层应用(即状态机或Server)发送一个
SnapshotValid = true的AppleMsg,告诉Server需要更新自己的状态。 - Server收到后,更新自己的状态数据以及lastApplied。
注意的地方,调用快照的时机。本实验中raft的状态数据大小不可超过8 * maxraftstate,否则会无法通过测试。那么服务器可以在每次从ApplyCh收到Raft提交的msg后来检测RaftStateSize(),为保守起见,认为RaftStateSize() > maxraftstate时就执行快照。并且这里需要使用同步阻塞的方式,否则可能不断有新的日志添加,导致超出大小限制。这里网上很多的参考答案通过另外启动一个全局线程,定期检查RaftState大小来实现,但这种方式可能会有问题,如果在某一个检测间隔内,服务器收到大量的请求,那么很容易就超了。
修复一个BUG:当server等待raft达成共识后,返回AppleMsg时,开启和关闭waitCh的方式
BUG
1 | // command()伪代码 |
本质是创建waitCh的时机。不知道谁先谁后
- 如果command中已经创建了Ch,那么通过kv.waitChMap[msg.CommandIndex]获取是没问题的。
- 如果applier在command创建Ch之前就达成了一致,并发送了AppleMsg,那么就拿不到Ch,意味着select会一直阻塞。如果不设置超时,command会无限阻塞。解决办法是如果applier先,那么就applier创建Ch。
总结:
- 对于
Server,所有修改Server状态的操作都需要提交给Raft层来完成,保持集群内部统一。上层应用通过调用rf.Start(Command)方法提交命令给Raft层,然后从ApplyCh中监听Raft提交的命令,并执行应用到状态机。 rf.Start(Command)的命令未必一定会被Apply,考虑到Leader还没将Command广播出去就挂了的情况。- 对状态机所有的修改必须在
Applier方法中通过ApplyCh拿到的已经被raft提交的日志