组会分享
1.基于LangChain的开源项目
低代码相关
| 名称 | 介绍 | 链接 |
|---|---|---|
| Langflow | LangChain设计的用户界面,使用react-flow设计,通过拖放组件和聊天框,可以轻松地进行实验和原型流程。 | |
| Flowise | Flowise是一个拖放用户界面,基于Langchain.js | |
| Databerry | 无代码平台,基于自定义数据源问答 | Dashboard | Chaindesk. |
| LangchainUI | 停止维护了 | |
| Yeager.ai | Langchain Agent 创建工具,旨在帮助您轻松构建、原型开发和部署人工智能驱动的代理 | |
| Superagent | Superagent 是一个开源代理框架,可让任何开发人员在几分钟内将可投入生产的人工智能助手集成到任何应用程序中。 | |
| Autogen | AutoGen 是一个框架,可以使用多个代理开发 LLM 应用程序,这些代理可以相互对话以解决任务。 |
Databerry
ChatGPT Agent Trained On Your Custom Data:根据您的自定义数据训练的 ChatGPT 代理
优点:
- 无需任何代码,基于数据源问答的机器人
- 支持丰富的数据源接入,原始文本、网页、文件
缺点:
- 功能比较单一,只有基于文档问答
- 大部分功能收费
LangSmith
LangSmith 是一个用于构建生产级 LLM 应用程序的平台。它可以让您调试、测试、评估和监控基于任何LLM框架构建的链和智能代理,并与LangChain无缝集成。目前正在开放测试,waitlist..
2.ChatDev
Introduce
2023年7月清华打造了一家虚拟软件公司。
ChatDev 是一家虚拟软件公司,通过不同的智能代理运营,这些代理担任不同的角色,包括首席执行官、首席产品官、首席技术官、程序员、审核员、测试员、艺术设计师。这些代理组成了一个多代理组织结构,并因 “通过编程彻底改变数字世界 “这一使命而团结在一起。ChatDev 内部的代理通过参加专门的功能研讨会进行合作,包括设计、编码、测试和文档等任务。
ChatDev 的主要目标是提供一个易于使用、高度可定制和可扩展的框架,该框架基于大型语言模型 (LLM),是研究集体智能的理想场景。
人员结构图:
- CEO、CPO、CTO
- 设计
- 编码
- 测试
- 文档

流水线结构: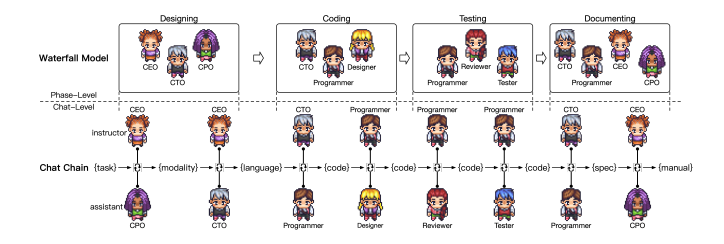
- STEP1.在设计环节开始之前,需要由真人/用户提供一个任务,这也是唯一需要人输入的地方。
- STEP2.CEO会分别与CPO和CTO进行讨论,决定实现上述任务所需要的Modality和Language
- Modality:模态,指呈现方式,Web端/桌面端/移动端/图形界面等
- Language:语言,指实现上述任务的编程语言,Python/Java/JS等

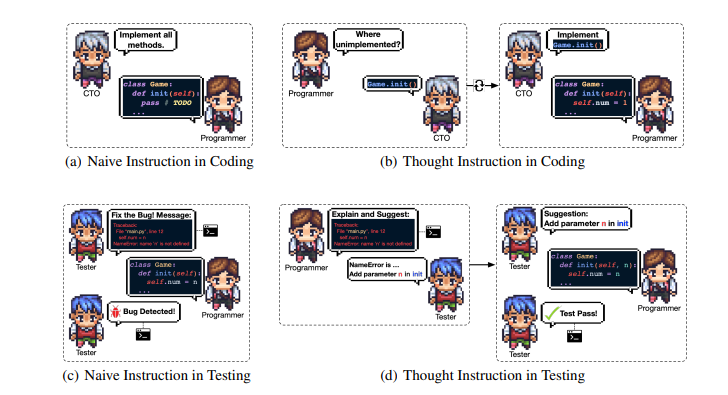
- STEP3.设计工作结束之后,就进入到了编程环节,包括代码撰写和图形界面设计。CTO向「程序员」提出要求和大致思路,然后「程序员」编写代码。设计师会生成GUI方案,并调用有关工具生成图像资源,由程序员进行集成。
- STEP4.程序编好之后,进行测试。测试环节分为对代码的审查和实际运行两步,涉及「代码审查员(Reviewer)」和「测试工程师(Tester)」两个角色。「程序员」根据意见不断修改。
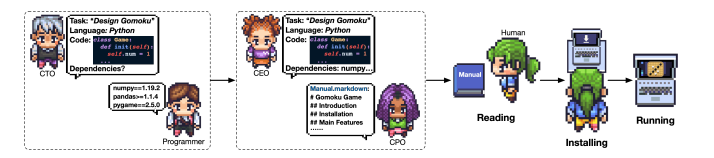
- STEP5.测试完成之后,意味着大功告成,接下来要做的是撰写文档。文档主要包括环境说明和用户手册两类。环境说明,由CTO指导程序员完成,说明了游戏运行所需依赖的环境。用户手册则由是CEO决定包含的内容,交由CPO进行生成。
Cases
ChatDev 可以根据用户指令生成的软件种类丰富,目前覆盖编程助手(网络爬虫、数据库读写、文件批处理、网页设计),休闲小游戏(五子棋、贪吃蛇、乒乓球游戏)、效率管理工具(代办清单、数字时钟、数学计算器、密码生成器),创作辅助工具(词典、绘画板、图片编辑器)等。
case1 CatchGoldHtmlGame
HTML形式游戏
case2 GreedySnakeGame
Python形式贪吃蛇
Insights
- 类似multi-agent框架,虽然ChatDev没有直接引用LangChain,但应该有所借鉴。
- 日志机制,可重放回演,以及提供了可视化整个开发软件过程的机制。
- 可配置的“软件公司”,可以修改CompanyConfig,来定制你“自己的公司”
- 覆盖了需求分析到代码开发再到文档编写整个的流程。其中“反思”机制和“Thought Instruction”机制很巧妙地提升了生成代码的成功率。
- 不仅帮我们把需求分析说明书、用户手册等不想写的文档写好了,甚至把代码都写好了。(虽然很toy
- 但目前只支持GPT_3_5_TURBO、GPT_4、GPT_4_32K,不支持通过本地的OpenAI API使用
过程回放演示:
1 | python online_log/app.py |
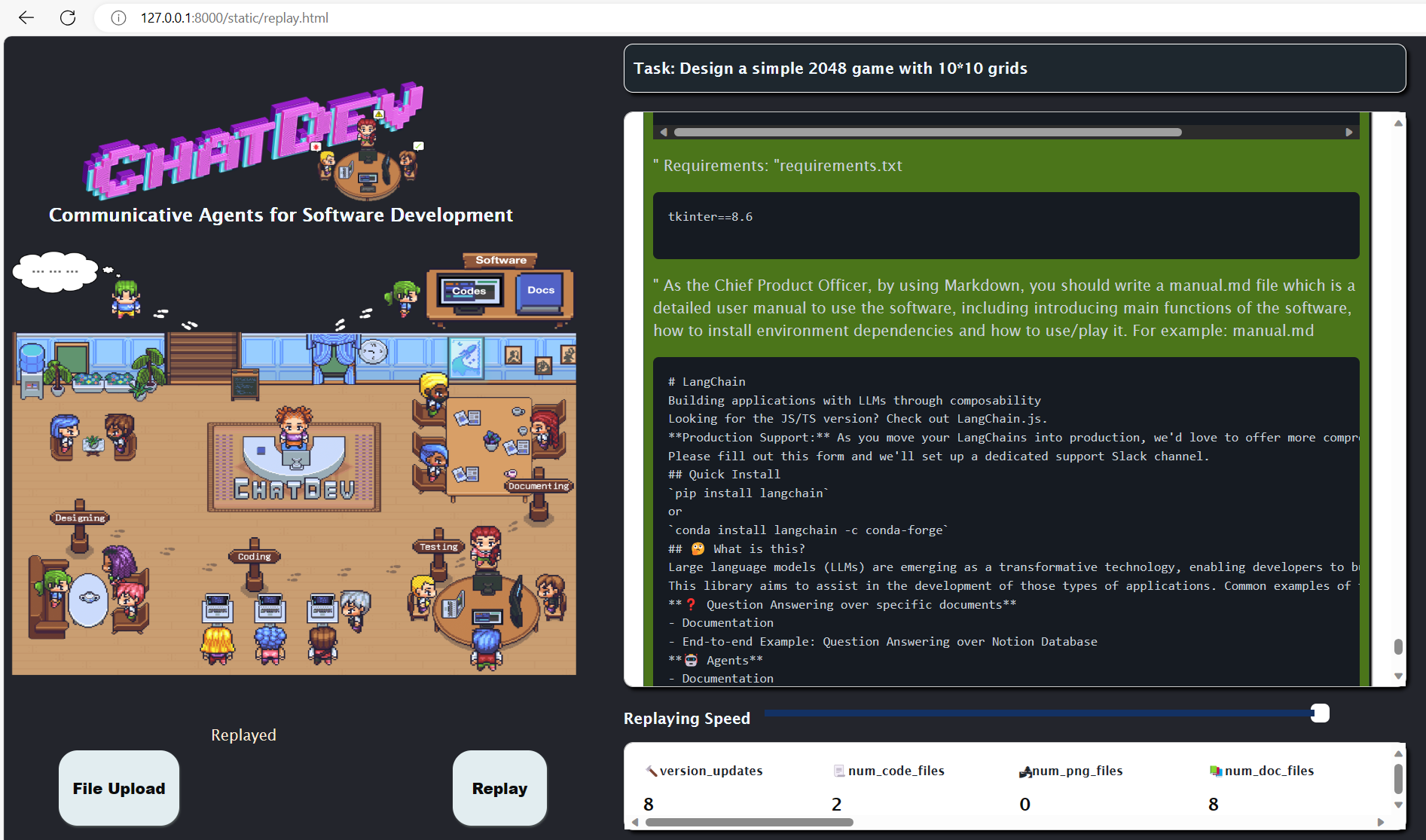
项目链接:ChatDev
论文链接:Communicative Agents for Software Development
3.AutoGen
介绍
通过上述ChatDev的例子,我们可以理解AutoGen是帮助我们建立自己“ChatDev”公司的工具。
通过OpenAI API KEY使用
配置OAI_CONFIG_LIST文件:输入API的Endpoint
1 | [ |
通过本地模型使用
1.问答和代码生成
1 | import autogen |
回答错误(ChatGLM2-6B):生成太久了结果也不太对,再等怕电脑烧了
ChatGLM3-6B:
(但确实在不断纠正和修改中)
1 | user_proxy (to assistant): |
空回答(百川7b模型)
1 | E:\Miniconda3\envs\pyautogen\python.exe E:/pythonProjects/AutoGenDemo/autoGenDemo1.py |
2.数学问题
1 | ''' |
学生党,快来 Azure 一起学习 OpenAI (一):注册 Azure 和申请 OpenAI_azure注册_Jambo Chen的博客-CSDN博客
总结
- 期待后续能构建如Flowise一样的UI界面,通过拖拽组件来构建和配置Agents组
- Multi-agent的互动可视化,回放机制(类似ChatDev,不过AutoGen做了缓存机制)
- 部分代理的提示词和模板是固定的,对GPT4可能会有优化。更换别的LLM后,效果待定?(比如换用中文能力好的LLM,原先用英语编写的提示词效果肯定会差)
4.本地部署大模型
4.1 FastChat
FastChat是一个LMSYS团队推出的开放平台,用于训练、服务和评估基于大型语言模型的框架。FastChat 为 Chatbot Arena (https://chat.lmsys.org/) 提供支持。
核心功能包括
- 为最先进模型(如 Vicuna、MT-Bench)的训练和评估代码。
- 分布式多模型服务系统,带有网页用户界面和兼容 OpenAI 的 RESTful API。
部署ChatGLM2-6B/ChatGLM3-6B
下载ChatGLM2-6B模型
方式一:通过git和git lfs下载,不过在使用git lfs下载模型权重的时候很可能由于网络原因下载失败
1 | git lfs install |
方式二:直接去Hugging Face的Files and vesions上手动把每个文件都下载下来,存到本地文件夹
THUDM/chatglm2-6b · Hugging Face
终端Cli部署
在命令行和大模型进行交互。如一问一答形式
1 | # --device cpu:表示仅使用CPU运行 |
Web Server部署
终端A运行命令,开启一个服务controller,负责响应API请求,默认的端口是localhost:21002
1
python -m fastchat.serve.controller
终端B运行命令,以Server模式在本地部署指定模型,并关联到上述controller
1
>python -m fastchat.serve.model_worker --model-path ../Models/chatglm2-6b --device cpu --load-8bit
1 | 2023-11-09 10:27:14 | INFO | model_worker | args: Namespace(host='localhost', port=21002, worker_address='http://localhost:21002', controller_addr |
多模型部署
1 | python -m fastchat.serve.multi_model_worker \ |
LangChain支持
LangChain 默认使用 OpenAI 模型名称,因此我们需要为本地模型指定一些假的 OpenAI 模型名称。
1 | python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002" --model-path lmsys/vicuna-7b-v1.5 |
vllm加速(需要cuda支持)
您可以在 FastChat 中使用 vLLM 作为优化的 Worker 实现。它提供先进的连续批处理功能和更高的(约 10 倍)吞吐量。
1 | python -m fastchat.serve.vllm_worker --model-path lmsys/vicuna-7b-v1.5 |
构建Web UI界面
终端C运行命令,开启一个Gradio Web服务器,一个内置的UI界面供用户和模型进行交互
`–host localhost –port 8888可以指定前端的地址和端口号
1 | python -m fastchat.serve.gradio_web_server |
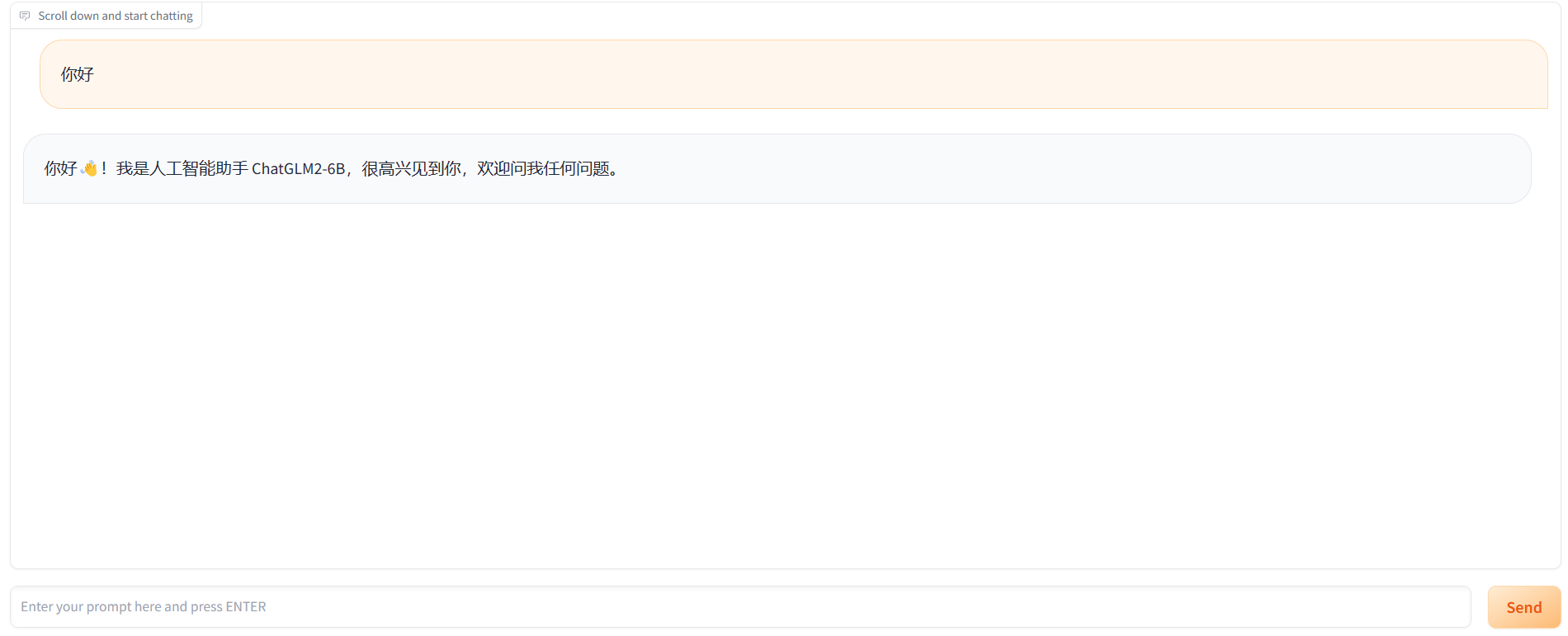
构建Restful Api服务
先决条件:已经在本地开启controller和装载模型
终端C运行下述命令,--host localhost --port 8000可以指定前端的地址和端口号
1 | python -m fastchat.serve.openai_api_server --host localhost --port 8000 |
然后就可以使用Restful Api调用大模型(推理时间很久5分钟)
- 方式一:FastAPI - Swagger UI
- 方式二:命令行curl
- 方式三:Postman等接口工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21{
"id": "chatcmpl-QWCVLS5A64wbJTWHhibYp6",
"object": "chat.completion",
"created": 1699501103,
"model": "chatglm2-6b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! I am ChatGLM2-6B, an AI Assistant based on the GLM model developed by Knowledge Engineering Group, Tsinghua University and Zhipu.AI."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 23,
"total_tokens": 63,
"completion_tokens": 40
}
} - 方式四:编写py程序访问
量化压缩
--load-8bit:使用8bit进行量化,可以减少约50%的内存占用,实测24GB->13GB左右。但推理速度没有明显变化,模型质量和性能会有一定程度下降。
1 | python -m fastchat.serve.cli --model-path ../Models/chatglm2-6b --device cpu --load-8bit |
依赖问题
如果遇到pydantic报错,修改fastchat/serve/openai_api_server.py文件如下,原因是pydantic版本不一致。
1 | from pydantic_settings import BaseSettings |
4.2 llama-cpp-python
llama.cpp库的python绑定,模型格式目前只支持gguf,可以使用convert-llama-ggmlv3-to-gguf.py 脚本进行转换。
- 通过 ctypes 接口访问 C API 的低级访问权限。
- 用于文本补全的高级 Python API
- 类似 OpenAI 的 API
- 兼容 LangChain
- 可以理解为llama.cpp的python版本,llama.cpp支持的它基本都支持。
部署Baichuan2-7B模型
在huggingface上下载Baichuan2-7b的gguf文件到本地
shaowenchen/baichuan2-7b-chat-gguf at main (huggingface.co)
High-level API
高级应用程序接口通过 Llama 类提供了一个简单的托管接口。
1 | from llama_cpp import Llama |
Web Server
llama-cpp-python 提供了一个网络服务器,旨在替代 OpenAI API。这样,您就可以在任何兼容 OpenAI 的客户端(语言库、服务等)上使用与 llama.cpp 兼容的模型。
1 | pip install llama-cpp-python[server] |
打开🦙 llama.cpp Python API - Swagger UI查看效果
Docker image
可以在docker容器中开启Web Server
1 | docker run --rm -it -p 8000:8000 -v /path/to/models:/models -e MODEL=/models/llama-model.gguf ghcr.io/abetlen/llama-cpp-python:latest |
安装问题
Windows安装报错解决方案:下载Visual Studio安装使用C++的桌面开发的拓展,可能原因是llama-cpp-python依赖于C++运行环境,需要gcc、cmake等工具。Linux平台也需要先安装这些工具。
windows上搭建llama小型私有模型-CSDN博客
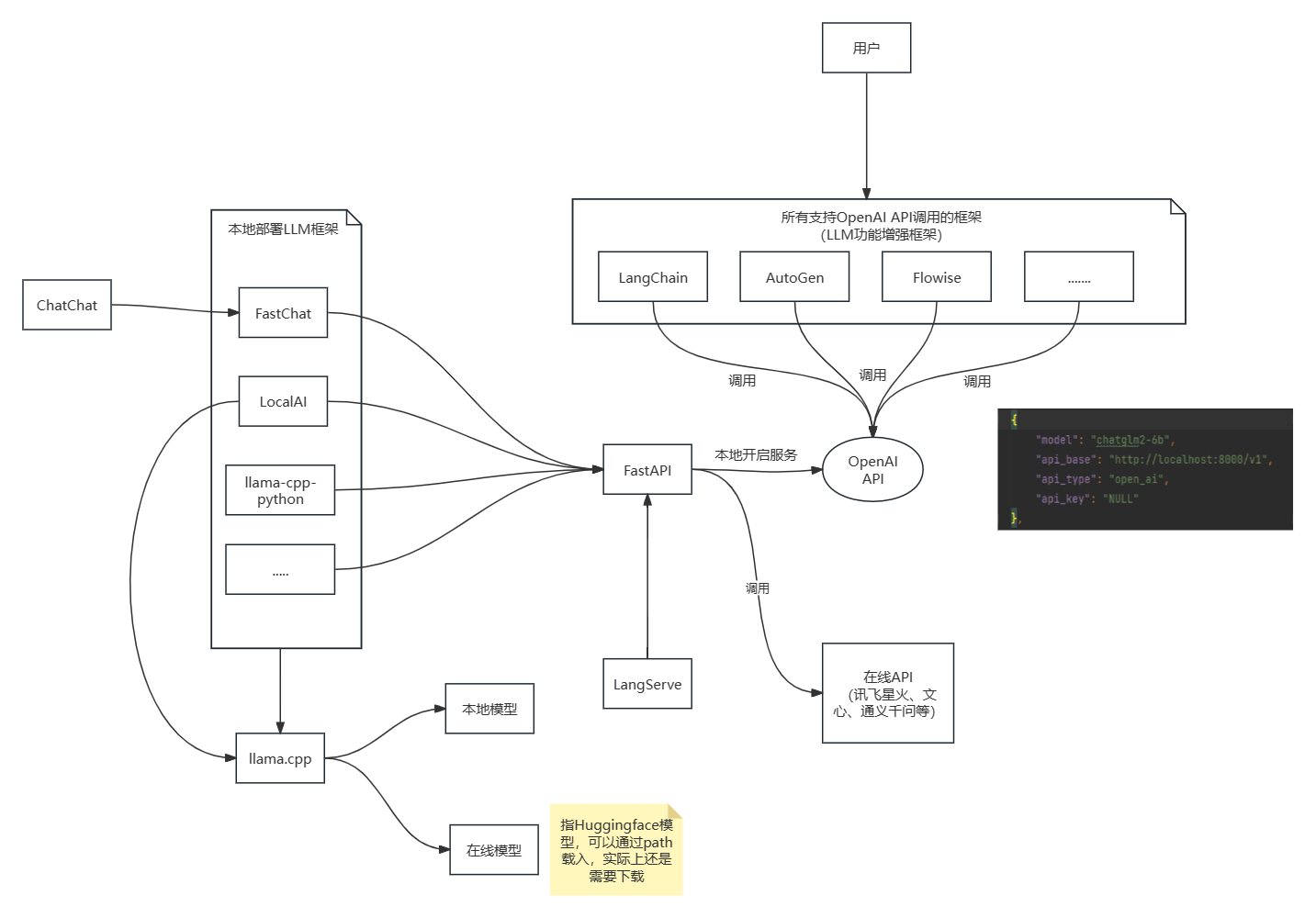
4.3 本地LLM推理框架对比
llama.cpp
- 纯 C/C++ 版本推理LLM
- 无需任何其他依赖(如python需要pytorch、tensorflow)
- 量化、GPU加速/纯CPU…
- Mac OS、Linux、Windows、Docker支持
- 差不多是现在本地运行LLM的鼻祖了,下面几个框架多少都基于它。
- 目前已有大部分编程语言的Bingdings

- 本地 OpenAI Drop-in 替代 REST API。
- 无需 GPU。可选GPU 加速可在与 llama.cpp 兼容的 LLM 中使用。
- 支持多种模型
- 使用 C++ 绑定,推理速度更快,性能更好。
- 功能丰富,本地推理只是其中的一个功能。还具有训练、微调、模型评估和基准测试等功能
- 兼容OpenAI APIs、Hugging Face APIs、LangChain集成
- 集成Web服务器 & UI界面
- 提供分布式多模型部署框架
- 部署过程中发现似乎可以把千帆、星火的api key也改造成OpenAI APIs。相当于我们可以直接使用千帆、星火来作为GPT4的平替。
- Python Bindings (从 Python 调用 C 或 C++以及C/C++和 Python 之间传递数据)
| OpenAI API规范 | 容器部署 | 支持的LLM | 多模型部署 | Stars | |
|---|---|---|---|---|---|
| LocalAI | ✔️ | ✔️ | Model compatibility | ✔️ | 13K |
| FastChat | ✔️ | ✔️ | Support Model | ✔️ | 29k |
| llama-cpp-python | ✔️ | ✔️ | 仅gguf格式 | ❌ | 4k |
5.总结
- 随着LLMs的迭代升级,目前很多框架不仅仅局限于其简单的对话能力,而是在不断扩展和压榨LLM的能力,从而进行功能的增强,如LangChain的链机制,LLM Agent的智能代理(被动到高度主动的自主行为),各种工具集成(Chatgpt的plugins的功能增强)。
- 从Single-agent到Multi-agents,进一步加强了合作和互动能力,可能是未来LLM的一个方向
- DWF集成:使用AutoGen先预定义不同的“代理集合”
- 脚本类代理:专门用来生产JS脚本的代理,根据输入的需求生成脚本,并迭代
测试和执行步骤,直到生成的脚本完全可用。但完全可用不好定义,如果用户不提供测试用例,代理只能保障生成的JS脚本可被执行不报错,不能保证其功能正确性。用户可以在test-agent中提供几个测试用例,确保生成的JS能够通过这些样例。 - 实体类代理:专门根据需求,生成对应的实体类结构,以便直接添加到DWF实体类中。需要agent识别需求描述中的各个实体类,及其属性,字段类型。
- 问答类代理:类似客服,基于文档检索的QA,可以根据DWF用户手册来回答相关问题,比如
如何为按钮添加事件、如何控制控件的显示和隐藏。
- 脚本类代理:专门用来生产JS脚本的代理,根据输入的需求生成脚本,并迭代