On the Robustness of Code Generation Techniques:An Empirical Study on GitHub Copilot
介绍
背景:我们在让大模型帮我们生成代码的时候,不同的需求描述对于模型生成的代码影响有多大。换个描述很可能会生成完全不同的结果。
研究目的:对于代码生成模型(以Github Copilot为例),不同但语义等效的自然语言描述是否会产生相同的推荐功能(代码)。
测试方法:892个Java methods来自1401个开源项目,将方法上方的注释作为输入给模型
生成释义的自动化工具:PEGASUS and TP
原始释义-一组语义等效的释义描述(使用PEGASUS and TP生成)
解释一下自动释义技术
PEGASUS
TP
方法
问题:
- RQ0:自动释义技术可以在多大程度上用于测试基于深度学习的代码生成器的鲁棒性?
- RQ1:GitHub Copilot 的输出在多大程度上受到开发人员作为输入提供的代码描述的影响?
<method,code_description>
892个方法: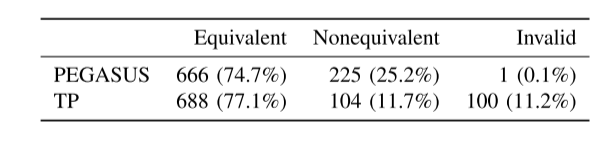
TP:只生成792个有效释义,其中非等效占比
PEGASUS:生成891个有效释义,其中非等效占比
手工:认为全部有效,且等效892
一共:792+891+892=2575 原始释义892 共2575+892=3467,两个上下文场景* 2=6934次调用
研究结果
RQ0:
RQ1:
局限性:
- 通过测试未必意味着生成代码的正确,使用CodeBLEU和编辑距离
- 自动化模拟脚本不能够完全代替模型对于开发者的帮助,开发人员也许会参考模型生成的结果后,灵活变通。
- 在判断语义等效性时,作者的主观性
- 892个数据集中可能部分已经被用于训练copilot,导致结果的不准确
- 仅考虑了Java语言
总结:
- 46%情况下,不同但语义相同的描述会导致生成代码的不同。
- 目前代码生成模型效果一般,仅有13%的生成代码能够通过测试,但作者说了(一部分原因是选取的待生成方法比较复杂,见图,圈复杂度等)
- 要让模型输出正确的代码,必须使用语义等效的描述之一(不好把控,评价指标没说)
- 提高开发者对代码的描述准确性
- 对DWF来说,如果内嵌AI助手,更需要用户能够准确的提供他们的需求/描述以获得期望的结果。
- 最佳实践:可以尝试输入给模型多种不同但意思相近的描述,对比生成的结果,选最佳的
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 LegGasai's CSLearning!
评论