凤凰架构笔记
1.架构师的视角
本地事务
- A(atomicity原子性):在同一项业务处理过程中,事务保证了对多个数据的修改,要么同时成功,要么同时被撤销。
- C(consistency一致性):事务必须是使数据库从一个一致性状态变到另一个一致性状态。
- I (isolation隔离性):在不同的业务处理过程中,事务保证了各自业务正在读、写的数据互相独立,不会彼此影响。
- D(durability持久性):事务应当保证所有成功被提交的数据修改都能够正确地被持久化,不丢失数据。
原子性、隔离性、持久性都是为一致性服务的
如何保证原子性和持久性
发生崩溃的情况
- 未提交事务,写入后崩溃:程序还没修改完三个数据,但数据库已经将其中一个或两个数据的变动写入磁盘,此时出现崩溃,一旦重启之后,数据库必须要有办法得知崩溃前发生过一次不完整的购物操作,将已经修改过的数据从磁盘中恢复成没有改过的样子,以保证原子性。(undo log)
- 已提交事务,写入前崩溃:程序已经修改完三个数据,但数据库还未将全部三个数据的变动都写入到磁盘,此时出现崩溃,一旦重启之后,数据库必须要有办法得知崩溃前发生过一次完整的购物操作,将还没来得及写入磁盘的那部分数据重新写入,以保证持久性。(redo log)
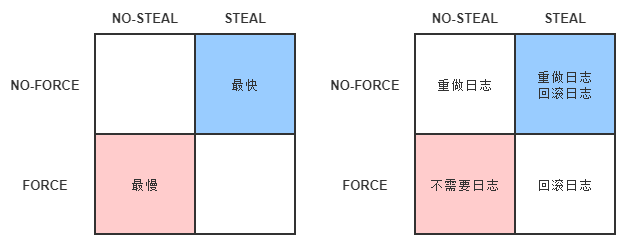
事务提交和写入时间分类
- FORCE:当事务提交后,要求变动数据必须同时完成写入则称为 FORCE,如果不强制变动数据必须同时完成写入则称为 NO-FORCE。现实中绝大多数数据库采用的都是 NO-FORCE 策略,因为只要有了日志,变动数据随时可以持久化,从优化磁盘 I/O 性能考虑,没有必要强制数据写入立即进行。
- STEAL:在事务提交前,允许变动数据提前写入则称为 STEAL,不允许则称为 NO-STEAL。从优化磁盘 I/O 性能考虑,允许数据提前写入,有利于利用空闲 I/O 资源,也有利于节省数据库缓存区的内存。
恢复崩溃时的操作
- 分析阶段(Analysis):该阶段从最后一次检查点(Checkpoint,可理解为在这个点之前所有应该持久化的变动都已安全落盘)开始扫描日志,找出所有没有 End Record 的事务,组成待恢复的事务集合,这个集合至少会包括 Transaction Table 和 Dirty Page Table 两个组成部分。
- 重做阶段(Redo):该阶段依据分析阶段中产生的待恢复的事务集合来重演历史(Repeat History),具体操作为:找出所有包含 Commit Record 的日志,将这些日志修改的数据写入磁盘,写入完成后在日志中增加一条 End Record,然后移除出待恢复事务集合。
- 回滚阶段(Undo):该阶段处理经过分析、重做阶段后剩余的恢复事务集合,此时剩下的都是需要回滚的事务,它们被称为 Loser,根据 Undo Log 中的信息,将已经提前写入磁盘的信息重新改写回去,以达到回滚这些 Loser 事务的目的。
如何保证隔离性
现代数据库的三种锁
写锁(Write Lock,也叫作排他锁,eXclusive Lock,简写为 X-Lock):如果数据有加写锁,就只有持有写锁的事务才能对数据进行写入操作,数据加持着写锁时,其他事务不能写入数据,也不能施加读锁。
读锁(Read Lock,也叫作共享锁,Shared Lock,简写为 S-Lock):多个事务可以对同一个数据添加多个读锁,数据被加上读锁后就不能再被加上写锁,所以其他事务不能对该数据进行写入,但仍然可以读取。对于持有读锁的事务,如果该数据只有它自己一个事务加了读锁,允许直接将其升级为写锁,然后写入数据。
范围锁(Range Lock):对于某个范围直接加排他锁,在这个范围内的数据不能被写入(不可新增或删除)。如下语句是典型的加范围锁的例子:
1
SELECT * FROM books WHERE price < 100 FOR UPDATE;
四种隔离级别
- 可串行化:对所有操作加写锁,读锁,范围锁。性能差,隔离级别最高。
- 可重复读(幻读):对事务所涉及的数据加读锁和写锁,且一直持有至事务结束,但不再加范围锁。
注意,这里的插入操作不需要加写锁。
1
2
3SELECT count(1) FROM books WHERE price < 100 /* 时间顺序:1,事务: T1 */
INSERT INTO books(name,price) VALUES ('深入理解Java虚拟机',90) /* 时间顺序:2,事务: T2 */
SELECT count(1) FROM books WHERE price < 100 /* 时间顺序:3,事务: T1 */ - 读已提交(幻读,不可重复读):对事务涉及的数据加的写锁会一直持续到事务结束,但加的读锁在查询操作完成后就马上会释放。
1
2
3SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 立刻释放读锁,因此之后可以进行update操作*/
UPDATE books SET price = 110 WHERE id = 1; COMMIT; /* 时间顺序:2,事务: T2 */
SELECT * FROM books WHERE id = 1; COMMIT; /* 时间顺序:3,事务: T1 */ - 读未提交(幻读,脏读,不可重复读):对事务涉及的数据只加写锁,会一直持续到事务结束,但完全不加读锁。
1
2
3
4
5
6SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */
/* 注意没有COMMIT */
UPDATE books SET price = 90 WHERE id = 1; /* 时间顺序:2,事务: T2 */
/* 这条SELECT模拟购书的操作的逻辑 */
SELECT * FROM books WHERE id = 1; /* 时间顺序:3,事务: T1 这里不需要加读锁,因此可以在有写锁的情况下进行读操作*/
ROLLBACK;
全局事务
在本节里,全局事务被限定为一种适用于单个服务使用多个数据源场景的事务解决方案。现在,我们对本章的场景事例做另外一种假设:如果书店的
用户、商家、仓库分别处于不同的数据库中,其他条件仍与之前相同,那情况会发生什么变化呢?假如你平时以声明式事务来编码,那它与本地事务看起来可能没什么区别,都是标个@Transactional注解而已,但如果以编程式事务来实现的话,就能在写法上看出差异,伪代码如下所示:
1 | public void buyBook(PaymentBill bill) { |
如果businessTransaction.commit()执行出错,则被异常捕获,执行rollback方法,但是此时userTransaction和warehouseTransaction已经commit(),回滚已无济于事,事务的整个一致性被破坏。
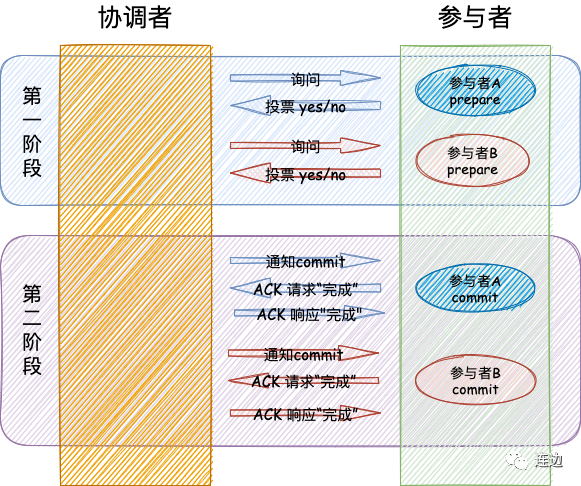
两段式提交(2pc)
- 准备阶段:又叫作投票阶段,在这一阶段,协调者询问事务的所有参与者是否准备好提交,参与者如果已经准备好提交则回复 Prepared,否则回复 Non-Prepared。这里所说的准备操作跟人类语言中通常理解的准备并不相同,对于数据库来说,准备操作是在重做日志中记录全部事务提交操作所要做的内容,它与本地事务中真正提交的区别只是暂不写入最后一条 Commit Record 而已,这意味着在做完数据持久化后并不立即释放隔离性,即仍继续持有锁,维持数据对其他非事务内观察者的隔离状态。(指事务操作已执行,但尚未commit)
- 提交阶段:又叫作执行阶段,协调者如果在上一阶段收到所有事务参与者回复的 Prepared 消息,则先自己在本地持久化事务状态为 Commit,<注意这个时间点可能会出现网络崩溃>在此操作完成后向所有参与者发送 Commit 指令,所有参与者立即执行提交操作;否则,任意一个参与者回复了 Non-Prepared 消息,或任意一个参与者超时未回复,协调者将自己的事务状态持久化为 Abort 之后,向所有参与者发送 Abort 指令,参与者立即执行回滚操作。对于数据库来说,这个阶段的提交操作应是很轻量的,仅仅是持久化一条 Commit Record 而已,通常能够快速完成,只有收到 Abort 指令时,才需要根据回滚日志清理已提交的数据,这可能是相对重负载的操作。(如果所有参与者的事务都操作成功,也就是都准备好了,则一起commit,否则全部回滚(因为此时大家都尚未commit,可以执行rollback))
两段式提交的缺陷
- 单点问题,协调者宕机影响全部参与者。
- 性能问题,整个过程涉及到两次远程服务调用,三次数据持久化
- 一致性风险,协调者commit后,网络崩溃,参与者无法commit
三段式提交(3pc)
三段式提交把原本的两段式提交的准备阶段再细分为两个阶段,分别称为 CanCommit、PreCommit,把提交阶段改称为 DoCommit 阶段。其中,新增的 CanCommit 是一个询问阶段,协调者让每个参与的数据库根据自身状态,评估该事务是否有可能顺利完成。将准备阶段一分为二的理由是这个阶段是重负载的操作,一旦协调者发出开始准备的消息,每个参与者都将马上开始写重做日志,它们所涉及的数据资源即被锁住,如果此时某一个参与者宣告无法完成提交,相当于大家都白做了一轮无用功。所以,增加一轮询问阶段,如果都得到了正面的响应,那事务能够成功提交的把握就比较大了,这也意味着因某个参与者提交时发生崩溃而导致大家全部回滚的风险相对变小。因此,在事务需要回滚的场景中,三段式的性能通常是要比两段式好很多的,但在事务能够正常提交的场景中,两者的性能都依然很差,甚至三段式因为多了一次询问,还要稍微更差一些。
- CanCommit阶段大幅减少了二段式中准备阶段参与者可能出错的情况
- 参与者超时自动提交机制,解决了二段式的
单点问题 - 如果协调者想发送Abort指令,但网络崩溃,参与者超时后会错误的进行Commit,同样导致数据不一致。
分布式事务
CAP和ACID
在分布式系统中,涉及共享数据问题时,以下三个特征最多同时满足两个。
一致性(Consistency):代表数据在任何时刻、任何分布式节点中所看到的都是符合预期的。一致性在分布式研究中是有严肃定义、有多种细分类型的概念,以后讨论分布式共识算法时,我们还会再提到一致性,那种面向副本复制的一致性与这里面向数据库状态的一致性严格来说并不完全等同,具体差别我们将在后续分布式共识算法中再作探讨。
可用性(Availability):代表系统不间断地提供服务的能力,理解可用性要先理解与其密切相关两个指标:可靠性(Reliability)和可维护性(Serviceability)。可靠性使用平均无故障时间(Mean Time Between Failure,MTBF)来度量;可维护性使用平均可修复时间(Mean Time To Repair,MTTR)来度量。可用性衡量系统可以正常使用的时间与总时间之比,其表征为:A=MTBF/(MTBF+MTTR),即可用性是由可靠性和可维护性计算得出的比例值,譬如 99.9999%可用,即代表平均年故障修复时间为 32 秒。
分区容忍性(Partition Tolerance):代表分布式环境中部分节点因网络原因而彼此失联后,即与其他节点形成“网络分区”时,系统仍能正确地提供服务的能力。
强一致性和弱一致性
- 强一致性(线性一致性):
- 复制是同步的
- 任何一次读都能读到某个数据的最近一次写的数据。
- 系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致。(简言之,在任意时刻,所有节点中的数据是一样的。)
- 弱一致性(最终一致性):
- 复制是异步的
- 数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
- 最终一致性就属于弱一致性。
- 最终一致性:
- 不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。
- 简单说,就是在一段时间后,节点间的数据会最终达到一致状态。
柔性事务和刚性事务
- 刚性事务:强一致性下的事务,常见于ACID
- 柔性事务:弱一致性下的事务,常见于BASE
BASE 分别是基本可用性(Basically Available)、柔性事务(Soft State)和最终一致性(Eventually Consistent)的缩写。
可靠事件队列
TCC事务
SAGA事务
透明多级分流系统
Transparent Multilevel Cache,这一章主要是从客户端到服务端的多级缓存机制的概述。
客户端缓存
域名解析DNS系统
传输链路
HTTP0.X、HTTP1.X、HTTP2.0的优化策略
内容分发网络
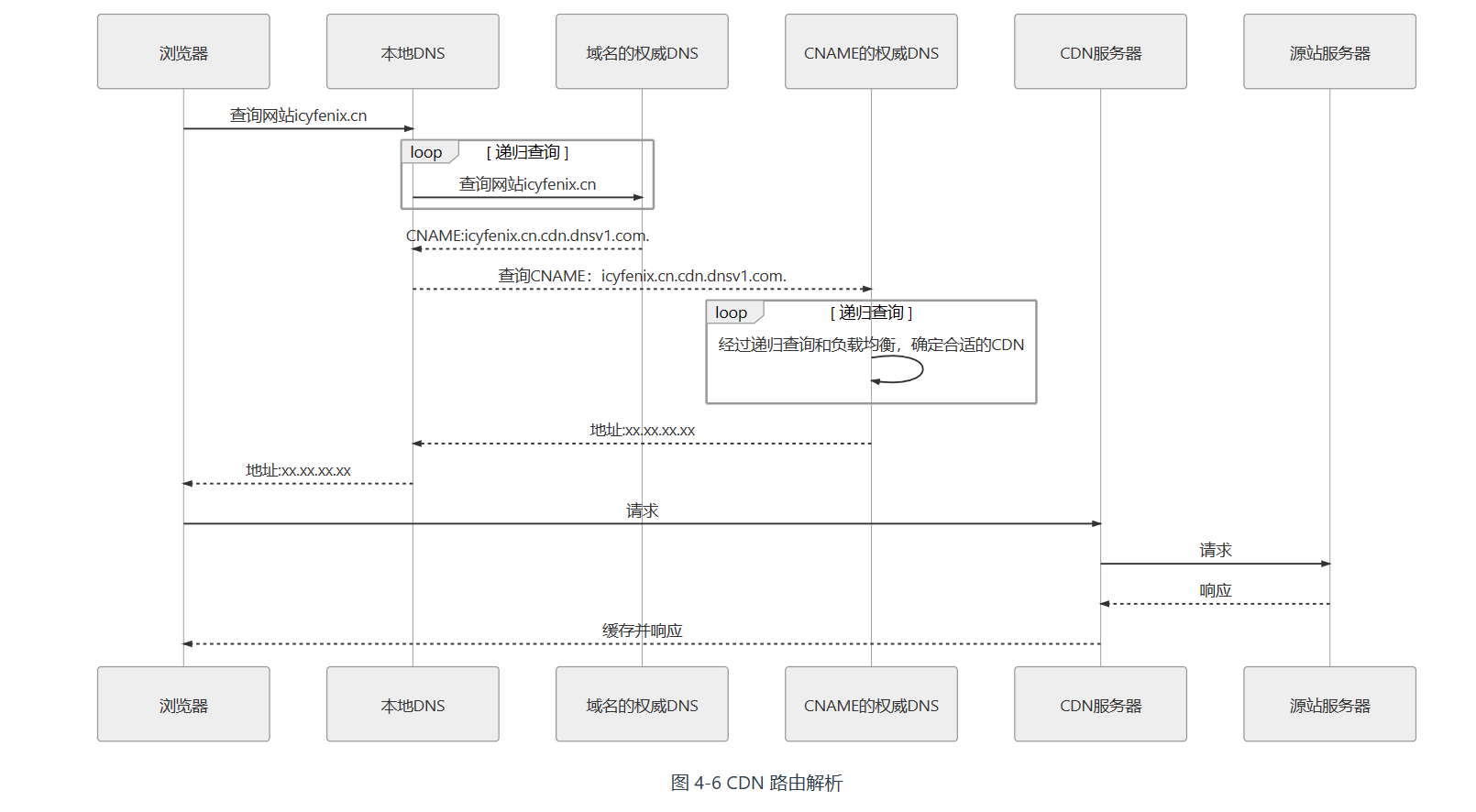
负载均衡
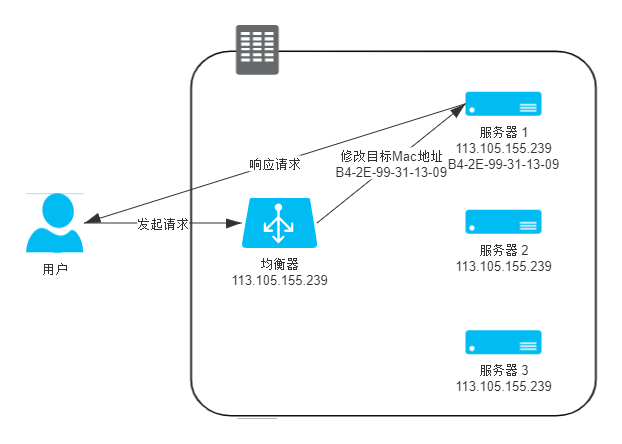
调度后方的多台机器,以统一的接口对外提供服务,承担此职责的技术组件被称为“负载均衡”。
- 数据链路层:修改
数据帧的目标MAC地址,服务器IP需要配置和均衡器的(虚拟)IP一致。
- 网络层:方式一:IP隧道;方式二改变目标数据包
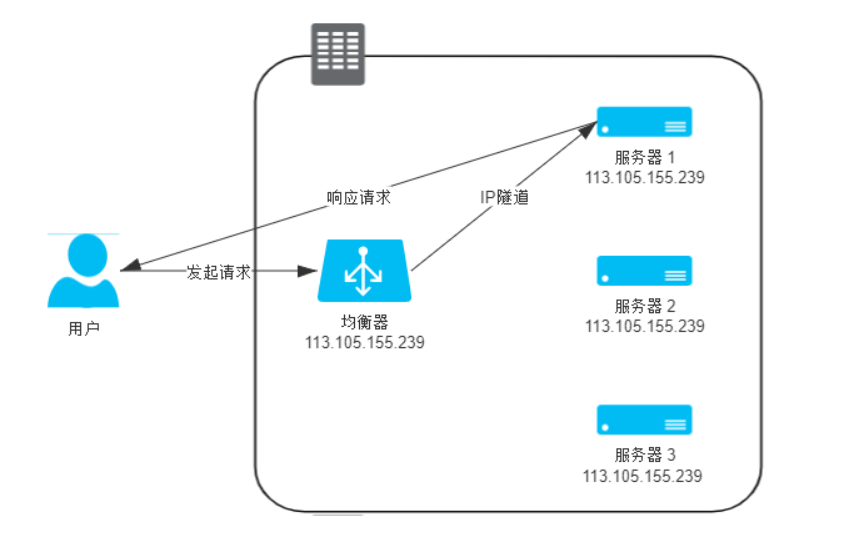
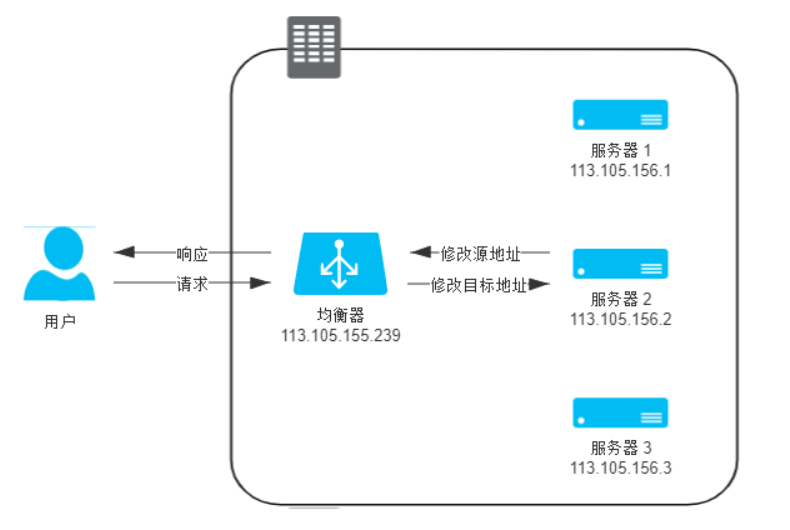
以上四层的负载均衡都属于转发,四层之后的负载均衡模式只能代理
根据哪一方能感知,代理分为如下三类
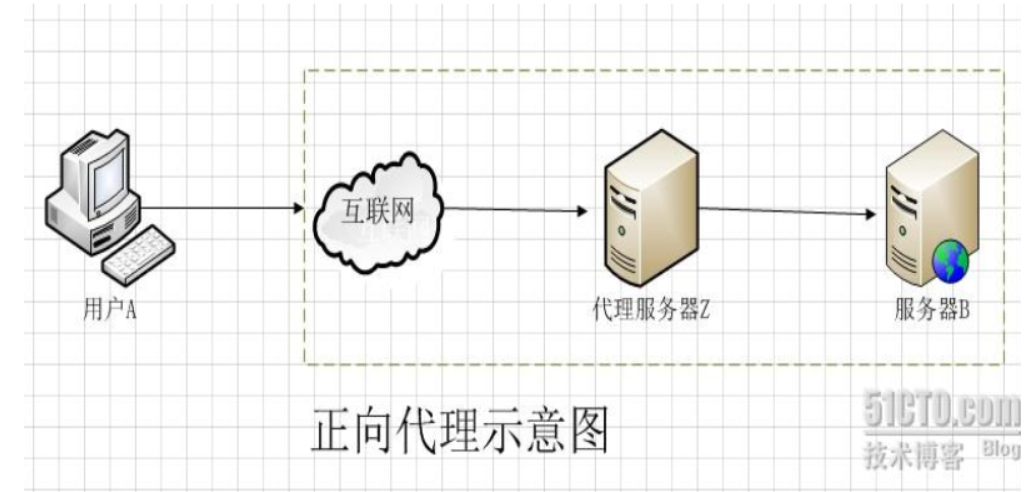
- 正向代理(默认):客户端可知,对服务端透明。代理服务器代替客户端与服务端通信。翻墙VPN使用了该类技术。
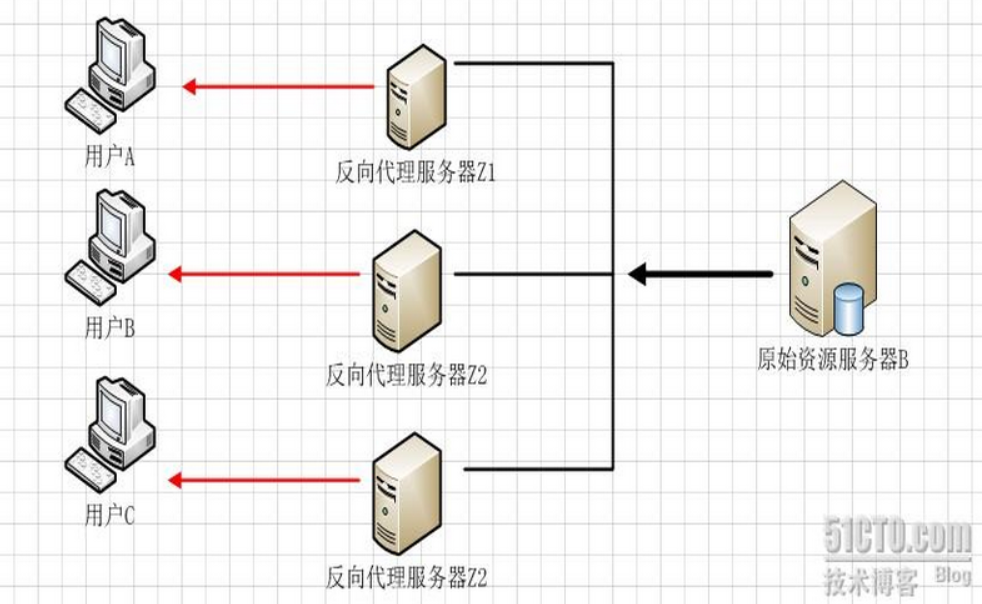
- 反向代理(七层负载均衡属于反向代理):服务端可知,对客户端透明。代理服务器代替服务端和客户端通信,而隐藏了真实服务端。
- 透明代理:对双方都透明。
负载均衡策略
- 轮询均衡
- 权重轮询均衡
- 随机均衡
- 权重随机均衡
- 一致性哈希均衡
- 响应速度均衡
- 最小连接数均衡
服务端缓存
缓存不是越多越好,需要考虑失效、一致性、更新、安全性等
进程内缓存
有Caffeine、ConcurrentLinkedHashMap、LinkedHashMap、Guava Cache、Ehcache 和 Infinispan Embedded
淘汰策略
有LRU,LFU,FIFO,TinyLFU,W-TinyLFU
缓存风险
- 缓存穿透:查询不存在的数据
- 对返回为空(不存在的数据)的key进行缓存一段时间
- 布隆过滤器
- 缓存击穿:热点数据突然失效,大量请求访问数据库
- 热点数据手动管理,计划更新
- 加锁同步,以请求该数据的key值为锁,使得只有第一个请求可以访问真实数据源,其它的暂时阻塞。
- 缓存雪崩:大量缓存同时失效
- 设置随机过期事件,避免同时大批量失效。
- 建设分布式缓存集群,提高可用性;透明多级缓存
- 缓存污染:数据不一致
- 缓存更新策略。
架构安全性
认证
系统如何正确分辨用户的真实身份
授权
系统如何控制一个用户该看到哪些数据、能操作哪些功能?
- 确保授权的过程可靠:OAuth2
- 确保授权的结果可控:RBAC
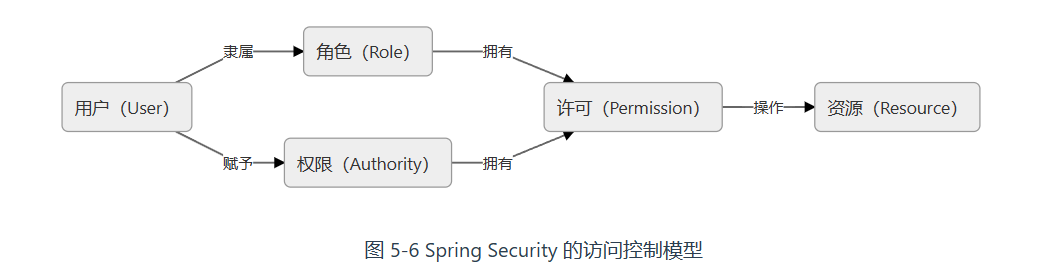
RBAC
谁(User)拥有什么权限(Authority)去操作(Operation)哪些资源(Resource)

OAuth2
用
令牌代替密码,用以解决第三方应用
为什么要用
令牌代替密码
- 密码泄露:如果第三方应用被黑客攻破,那导致授权应用或其他应用的密码同时泄露
- 访问范围:拥有了密码相当于拥有了账号的整个权限,不利于细粒度的访问控制。比如之对外开放查看权限,增删改权限不开放
- 授权回收:收回权限意味着只能修改密码,这样会导致其他使用同样密码的应用失效。
令牌可以设置有效期,过期失效。
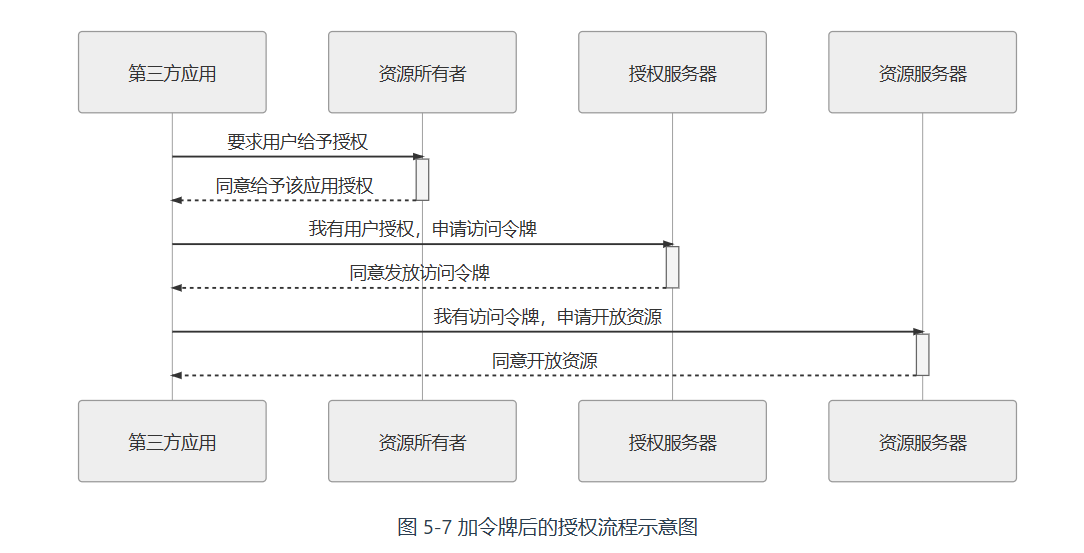
四种角色
- 授权服务器,负责颁发 Access Token,比如微信开放平台授权服务器。
- 资源所有者,你的应用的用户是资源的所有者,授权其他人访问他的资源。比如微信用户是资源所有者。
- 调用方,调用方请求获取 Access Token,经过用户授权后,微信开放平台为其颁发 Access Token。调用方可以携带 Access Token 到资源服务器访问用户的资源。比如调用方是上文说的网站A。
- 资源服务器,接受 Access Token,然后验证它的被赋予的权限项目,最后返回资源。比如微信开放平台资源服务器。
四种授权方式
- 授权码模式(Authorization Code)
- 隐式授权模式(Implicit)
- 密码模式(Resource Owner Password Credentials)
- 客户端模式(Client Credentials)
授权码模式
微信扫码授权功能
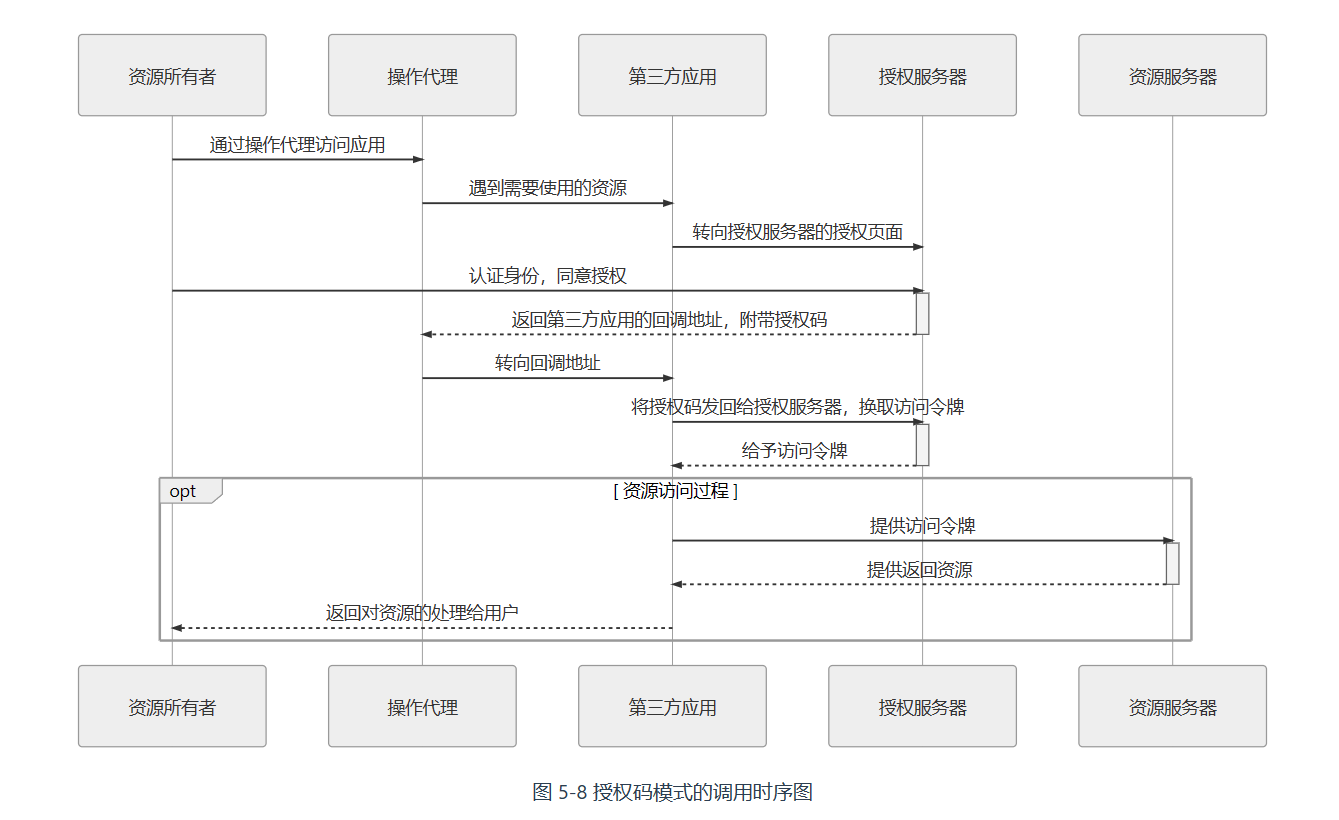
授权过程:
- 第三方应用将资源所有者(用户)导向授权服务器的授权页面,并向授权服务器提供 ClientID 及用户同意授权后的回调 URI,这是一次客户端页面转向。
- 授权服务器根据 ClientID 确认第三方应用的身份,用户在授权服务器中决定是否同意向该身份的应用进行授权,用户认证的过程未定义在此步骤中,在此之前应该已经完成。
- 如果用户同意授权,授权服务器将转向第三方应用在第 1 步调用中提供的回调 URI,并附带上一个授权码和获取令牌的地址作为参数,这是第二次客户端页面转向。
- 第三方应用通过回调地址收到授权码,然后将授权码与自己的 ClientSecret 一起作为参数,通过服务器向授权服务器提供的获取令牌的服务地址发起请求,换取令牌。该服务器的地址应与注册时提供的域名处于同一个域中。
- 授权服务器核对授权码和 ClientSecret,确认无误后,向第三方应用授予令牌。令牌可以是一个或者两个,其中必定要有的是访问令牌(Access Token),可选的是刷新令牌(Refresh Token)。访问令牌用于到资源服务器获取资源,有效期较短,刷新令牌用于在访问令牌失效后重新获取,有效期较长。
- 资源服务器根据访问令牌所允许的权限,向第三方应用提供资源。
思考的问题:
- 第三方应用在授权服务器注册的时候需要提供一个回调地址URI,这个URI必须要和步骤1中的一致。
- 其他应用假冒第三方应用骗取授权
其他应用没有ClientSecret换取不到令牌。令牌需要ClientID,ClientSecret(第三方应用私有),授权码才能换取令牌。
- 为什么先发授权码,再用授权码换取令牌
授权码相当于临时令牌是给浏览器的,但授权码是暴露的。因此需要借助第三方应用的ClientSecret再去换取令牌
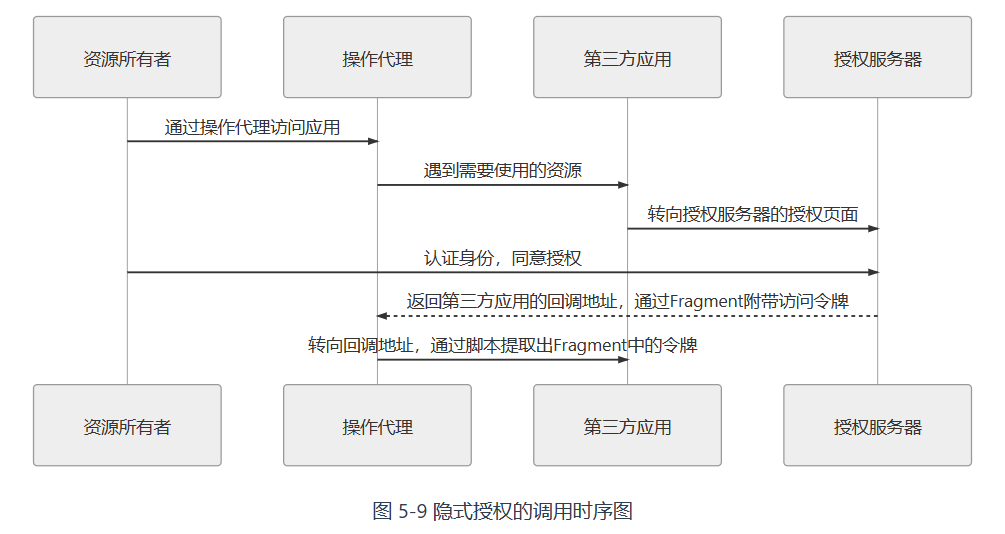
隐式授权模式
省略掉了通过授权码换取令牌的步骤,需要在注册时提供回调域名,此时会要求该域名与接受令牌的服务处于同一个域内。此外,同样基于安全考虑,在隐式模式中明确禁止发放刷新令牌。
密码模式
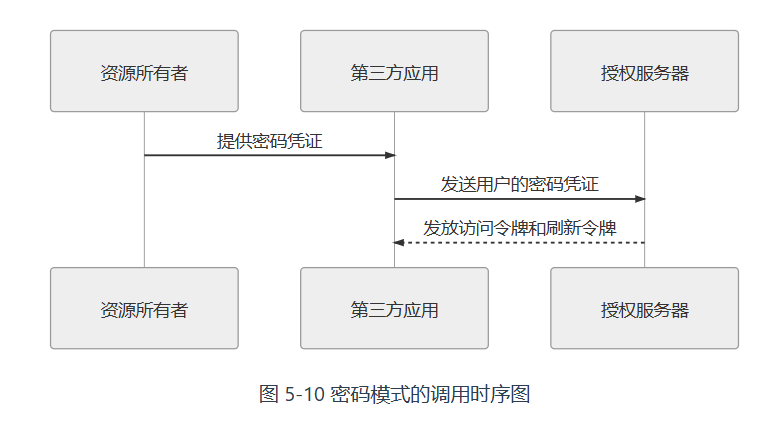
第三方通过用户名和密码换取令牌,但无法保障第三方不会非法保存用户的密码。
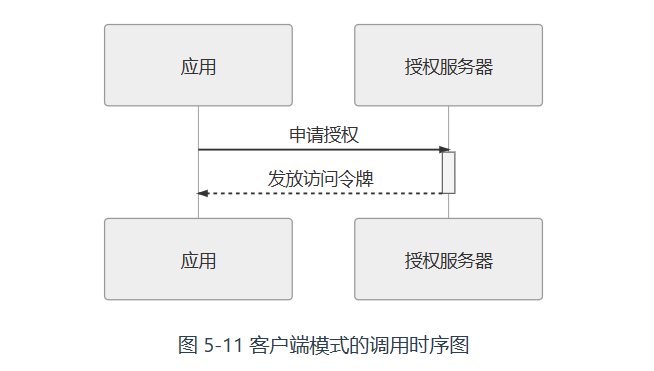
客户模式
该模式不需要用户同意授权,比如超时订单自动取消。
凭证
系统如何保证它与用户之间的承诺是双方当时真实意图的体现,是准确、完整且不可抵赖的?
无状态和有状态
无状态:各个请求对于服务器来说统一无差别处理,请求自身携带了所有服务端所需要的所有参数(服务端自身不存储跟请求相关的任何数据,不包括数据库存储信息
有状态:与之相反,有状态服务在服务端保留之前请求的信息,用以处理当前请求,比如session等
Cookie-Session
特点:
- 存储在服务器,是有状态的。
缺点:
- 在分布式的情况下,水平拓展困难,根据CAP理论,无法同时满足一致性,可用性,分区容忍性
JWT
特点:
- 是服务端发送给客户端的,保存在客户端,每次请求随请求发送到服务器
- 是无状态的
- 由三个部分构成:
令牌头:可以被解密
1
2
3
4{
"alg": "HS256",
"typ": "JWT"
}负载:可以被解密。一般存放用户非敏感信息,过期时间等。
1
2
3
4
5
6
7
8
9
10
11
12
13{
"username": "icyfenix",
"authorities": [
"ROLE_USER",
"ROLE_ADMIN"
],
"scope": [
"ALL"
],
"exp": 1584948947,
"jti": "9d77586a-3f4f-4cbb-9924-fe2f77dfa33d",
"client_id": "bookstore_frontend"
}签名:由于加了密钥进行加密,一般不能被破密。
1
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload) , secret)
缺点:
- 令牌难以主动失效
- 相对更容易遭受重放攻击
- 相对更容易遭受重放攻击
- 必须考虑令牌在客户端如何存储
- 无状态也不总是好的
传输
加密、摘要、签名、证书,一次说明白! - 简书 (jianshu.com)
安全风险类别:
- 窃听风险:现代计算机网络建立在 TCP/IP 协议族提供传输能力上,数据在传输线路上的每个环节都可能被窃听,从而导致敏感数据泄露;
- 纂改风险:数据在传输过程中可能被篡改,例如中间人攻击。攻击者可以和通信双方分别建立独立的连接,使得通信双方误以为它们正在进行一个私密连接,但察觉不到数据被篡改;(中间商)
- 伪装风险:攻击者可以伪装成合法的身份。
实现传输安全:
- 加密 —— 防窃听:将明文转换为密文,只有期望的接收方有能力将密文解密为明文,即使密文被攻击者窃取也无法理解数据的内容;
- 验证完整性 —— 防止篡改:对原始数据计算摘要,并将数据和摘要一起交付给通信对方。接收方收到后也对数据计算摘要,并比较是否和接受的摘要一致,借此判断接收的数据是否被篡改。不过,因为收到的摘要也可能被篡改,所以需要使用更安全的手段:数字签名;
- 认证数据来源 —— 防止伪装: 数字签名能够验证数据完整性,同时也能认证数据来源,防止伪装。
摘要:摘要算法的原理是根据一定的运算规则提取原始数据中的信息,被提取的信息就是原始数据的消息摘要,也称为数据指纹。
- 一致性: 相同数据多次计算的摘要是相同的,不同的数据(在不考虑碰撞时)的摘要是不同的;
- 不可逆性: 只能正向提取原始数据的摘要,无法从摘要反推出原始数据;
- 高效性: 摘要的生成过程高效快速;
加密:加密(Encryption)是将明文(Plaintext)转换为密文(Ciphertext)的过程,只有期望的接收方有能力将密文解密为明文,即使密文被攻击者窃取也无法理解数据的内容。
- 对称加密:加密和解密使用相同的密钥
- 非对称加密:加密和解密使用不同的密钥
1、密钥管理: 对称加密算法中需要将密钥发送给通信对方,存在密钥泄漏风险;非对称加密公钥是公开的,私钥是保密的,防止了私钥外传;
2、密钥功能: 公钥加密的数据,只可使用私钥对其解密。反之,私钥加密的数据,只可使用公钥对其解密(注意:公钥加密的数据无法使用公钥解密,因为公钥是公开的,如果公钥可以解密的话,就失去了加密的安全性);
3、计算性能: 非对称加密算法的计算效率低,因此实际中往往采用两种算法结合的复合算法:先使用非对称加密建立安全信道传输对称密钥,再使用该密钥进行对称加密;
4、认证功能: 非对称加密算法中,私钥只有一方持有,具备认证性和抗抵赖性(第 3 节 数字签名算法 应用了此特性)。
验证
系统如何确保提交到每项服务中的数据是合乎规则的,不会对系统稳定性、数据一致性、正确性产生风险?
2.分布式的基石
分布式共识算法
Paxos
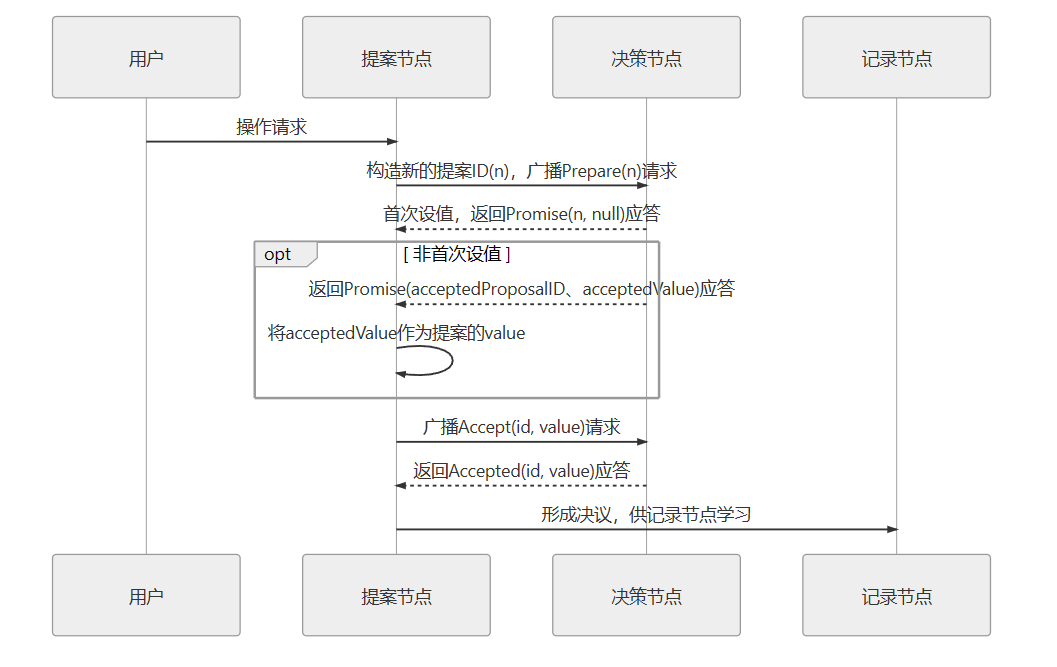
算法中的三类节点(任何节点都可以充当一下三个角色之一)
- 提案节点:称为 Proposer,提出对某个值进行设置操作的节点,设置值这个行为就被称之为提案(Proposal),值一旦设置成功,就是不会丢失也不可变的。请注意,Paxos 是典型的基于操作转移模型而非状态转移模型来设计的算法,这里的“设置值”不要类比成程序中变量赋值操作,应该类比成日志记录操作,在后面介绍的 Raft 算法中就直接把“提案”叫作“日志”了。
- 决策节点:称为 Acceptor,是应答提案的节点,决定该提案是否可被投票、是否可被接受。提案一旦得到过半数决策节点的接受,即称该提案被批准(Accept),提案被批准即意味着该值不能再被更改,也不会丢失,且最终所有节点都会接受该它。(奇数个)
- 记录节点:被称为 Learner,不参与提案,也不参与决策,只是单纯地从提案、决策节点中学习已经达成共识的提案,譬如少数派节点从网络分区中恢复时,将会进入这种状态。
Prepare阶段:提案节点广播新的提案ID(n),决策节点收到后,做出”两个承诺“和”一个应答“,如果自己没有接收其他人的提案,则返回Promise(n,null),如果已经接受了编号更大的提案,则返回Promise(acceptedID,acceptValue)
Accept阶段:在该阶段,提案节点会根据决策节点的Promise来决定行为。
- 如果上一阶段超过半数的机器回复说接受提案,那么Proposer就正式通知所有机器去生效这个操作;
- 如果上一阶段超过半数的机器回复说他们已经先接受了其他编号更大的提案,那么Proposer会更新一个更大的编号去重试(随机延时);
- 如果上一阶段的机器回复说他们已经生效了其他编号的提案,那么Proposer就也只能接受这个其他人的提案,并告知所有机器直接接受这个新的提案;
- 如果上一阶段都没收到半数的机器回复,那么提案取消。
分布式共识算法之Paxos详解 - 知乎 (zhihu.com)
Multi Paxos
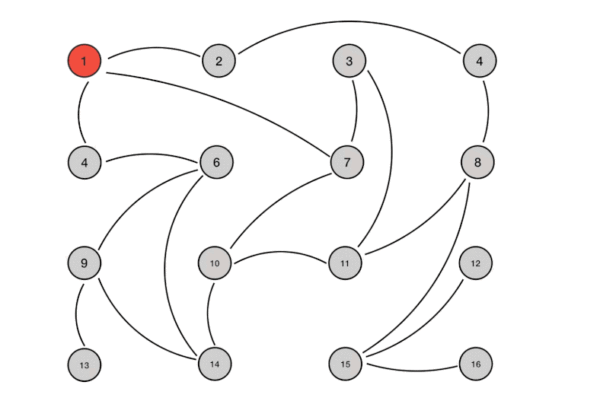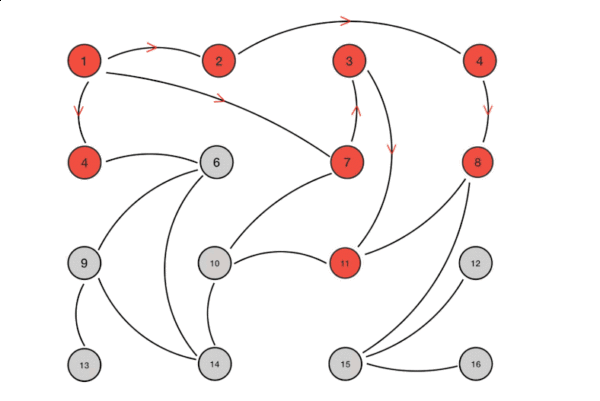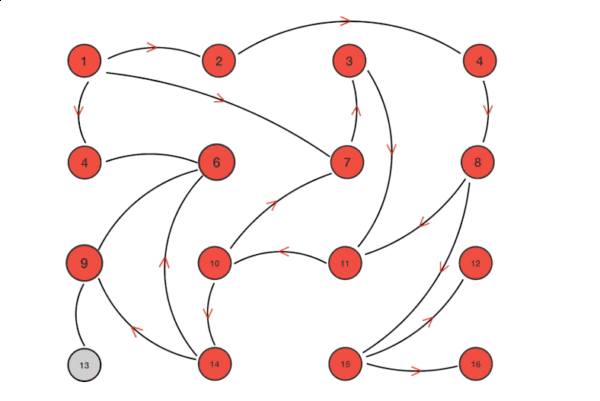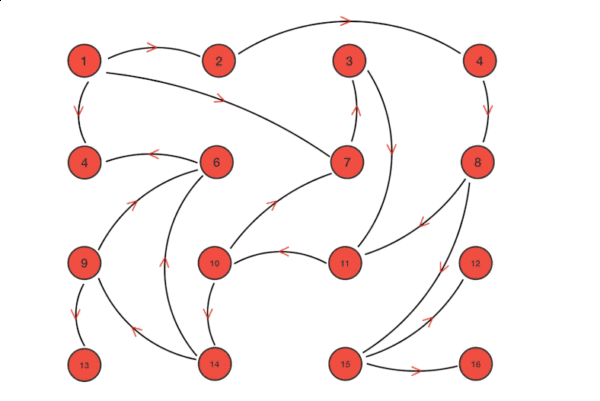
Basic-Paxos存在“活锁”现象,如下图,则所有提案节点会不断增大自己的编号,导致陷入持续等待。
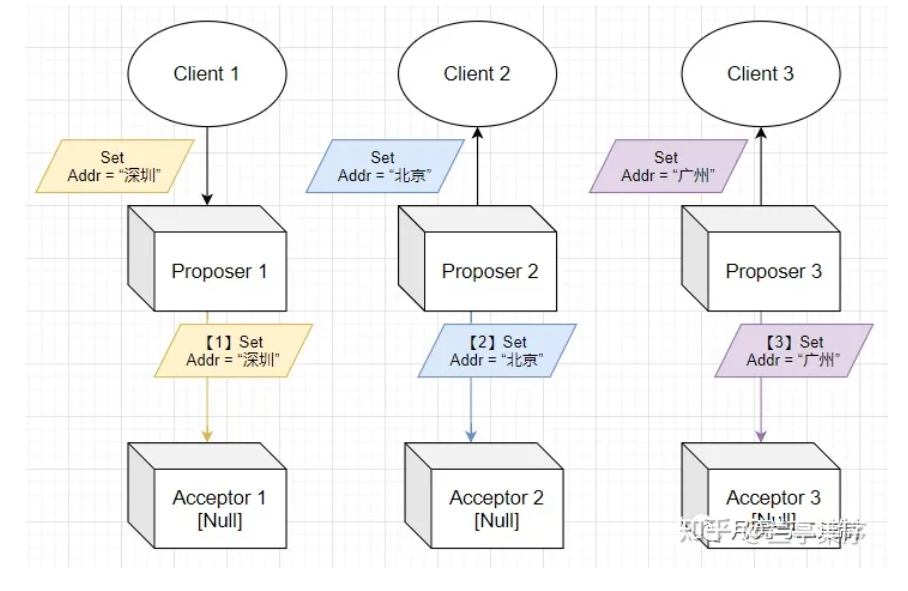
为了解决这个问题,提出了Multi-Paxos算法
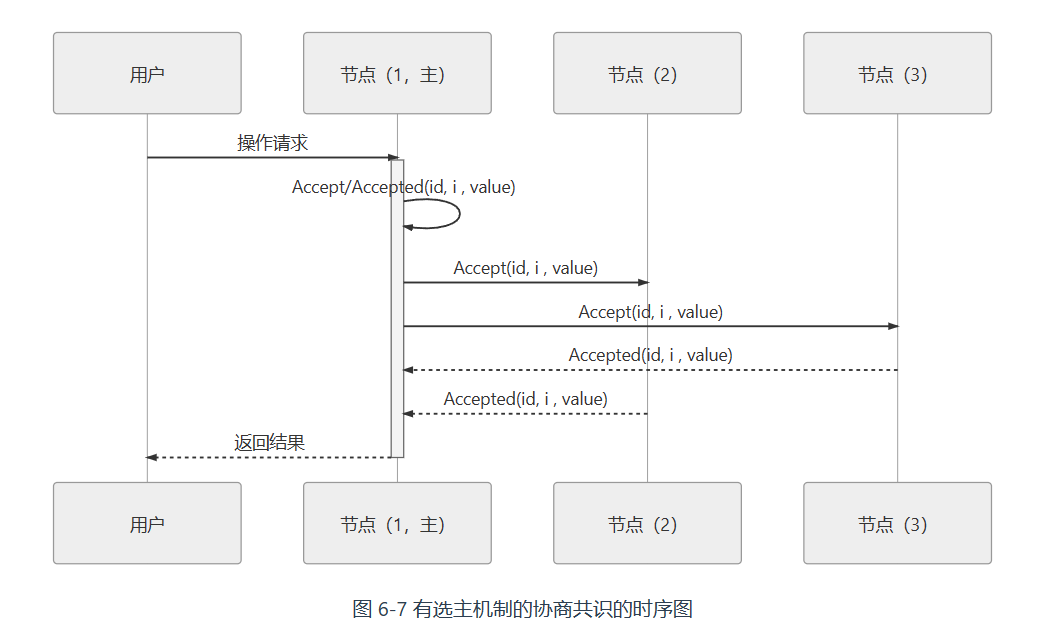
Multi Paxos 对 Basic Paxos 的核心改进是增加了“选主”的过程,提案节点会通过定时轮询(心跳),确定当前网络中的所有节点里是否存在有一个主提案节点,一旦没有发现主节点存在,节点就会在心跳超时后使用 Basic Paxos 中定义的准备、批准的两轮网络交互过程,向所有其他节点广播自己希望竞选主节点的请求,希望整个分布式系统对“由我作为主节点”这件事情协商达成一致共识,如果得到了决策节点中多数派的批准,便宣告竞选成功。当选主完成之后,除非主节点失联之后发起重新竞选,否则从此往后,就只有主节点本身才能够提出提案。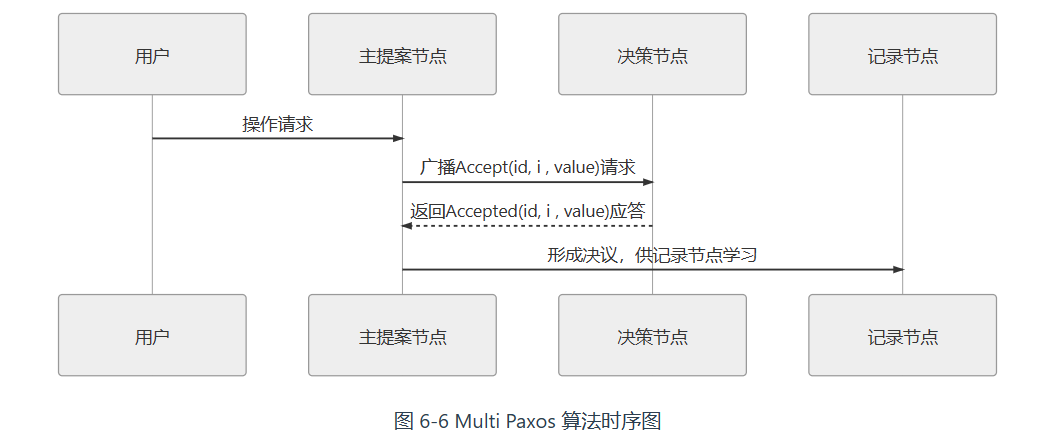
Gossip协议
强一致性协议:Paxos、Raft、ZAB
最终一致性:DNS、Gossip
Gossip过程
如果有某一项信息需要在整个网络中所有节点中传播,那从信息源开始,选择一个固定的传播周期(譬如 1 秒),随机选择它相连接的 k 个节点(称为 Fan-Out)来传播消息。
每一个节点收到消息后,如果这个消息是它之前没有收到过的,将在下一个周期内,选择除了发送消息给它的那个节点外的其他相邻 k 个节点发送相同的消息,直到最终网络中所有节点都收到了消息,尽管这个过程需要一定时间,但是理论上最终网络的所有节点都会拥有相同的消息。
从类库到服务
服务发现
远程服务调用三要素:全限定名、端口号、服务标识
相关的组件:ZooKeeper、Eureka、Nacos
服务发现的步骤
- 服务的注册(Service Registration):当服务启动的时候,它应该通过某些形式(如调用 API、产生事件消息、在 ZooKeeper/Etcd 的指定位置记录、存入数据库,等等)将自己的坐标信息通知到
服务注册中心,这个过程可能由应用程序本身来完成,称为自注册模式,譬如 Spring Cloud 的@EnableEurekaClient 注解;也可能由容器编排框架或第三方注册工具来完成,称为第三方注册模式,譬如 Kubernetes 和 Registrator。 - 服务的维护(Service Maintaining):尽管服务发现框架通常都有提供下线机制,但并没有什么办法保证每次服务都能优雅地下线(Graceful Shutdown)而不是由于宕机、断网等原因突然失联。所以服务发现框架必须要自己去保证所维护的服务列表的正确性,以避免告知消费者服务的坐标后,得到的服务却不能使用的尴尬情况。现在的服务发现框架,往往都能支持多种协议(HTTP、TCP 等)、多种方式(长连接、心跳、探针、进程状态等)去监控服务是否健康存活,将不健康的服务自动从服务注册表中剔除。
- 服务的发现(Service Discovery):这里的发现是特指狭义上消费者从服务发现框架中,把一个符号(譬如 Eureka 中的 ServiceID、Nacos 中的服务名、或者通用的 FQDN)转换为服务实际坐标的过程,这个过程现在一般是通过 HTTP API 请求或者通过 DNS Lookup 操作来完成,也还有一些相对少用的方式,譬如 Kubernetes 也支持注入环境变量来做服务发现。
注册中心实现
- 在分布式 K/V 存储框架上自己开发的服务发现,这类的代表是 ZooKeeper、Doozerd、Etcd。
- 以基础设施(主要是指 DNS 服务器)来实现服务发现,这类的代表是 SkyDNS、CoreDNS。
- 专门用于服务发现的框架和工具,这类的代表是 Eureka、Consul 和 Nacos。
网关路由
网关 = 路由器(基础职能) + 过滤器(可选职能)
网络IO模型
两类五种
两类是指同步 I/O与异步 I/O,五种是指在同步 IO 中又分有划分出阻塞 I/O、非阻塞 I/O、多路复用 I/O和信号驱动 I/O四种细分模型。
- 异步 I/O(Asynchronous I/O):好比你在美团外卖订了个盒饭,付款之后你自己该干嘛还干嘛去,饭做好了骑手自然会到门口打电话通知你。异步 I/O 中数据到达缓冲区后,不需要由调用进程主动进行从缓冲区复制数据的操作,而是复制完成后由操作系统向线程发送信号,所以它一定是非阻塞的。
- 同步 I/O(Synchronous I/O):好比你自己去饭堂打饭,这时可能有如下情形发生:
- 阻塞 I/O(Blocking I/O):你去到饭堂,发现饭还没做好,你也干不了别的,只能打个瞌睡(线程休眠),直到饭做好,这就是被阻塞了。阻塞 I/O 是最直观的 I/O 模型,逻辑清晰,也比较节省 CPU 资源,但缺点就是线程休眠所带来的上下文切换,这是一种需要切换到内核态的重负载操作,不应当频繁进行。
- 非阻塞 I/O(Non-Blocking I/O):你去到饭堂,发现饭还没做好,你就回去了,然后每隔 3 分钟来一次饭堂看饭做好了没,直到饭做好。非阻塞 I/O 能够避免线程休眠,对于一些很快就能返回结果的请求,非阻塞 I/O 可以节省切换上下文切换的消耗,但是对于较长时间才能返回的请求,非阻塞 I/O 反而白白浪费了 CPU 资源,所以目前并不常用。
- 多路复用 I/O(Multiplexing I/O):多路复用 I/O 本质上是阻塞 I/O 的一种,但是它的好处是可以在同一条阻塞线程上处理多个不同端口的监听。类比的情景是你名字叫雷锋,代表整个宿舍去饭堂打饭,去到饭堂,发现饭还没做好,还是继续打瞌睡,但哪个舍友的饭好了,你就马上把那份饭送回去,然后继续打着瞌睡哼着歌等待其他的饭做好。多路复用 I/O 是目前的高并发网络应用的主流,它下面还可以细分 select、epoll、kqueue 等不同实现,这里就不作展开了。
- 信号驱动 I/O(Signal-Driven I/O):你去到饭堂,发现饭还没做好,但你跟厨师熟,跟他说饭做好了叫你,然后回去该干嘛干嘛,等收到厨师通知后,你把饭从饭堂拿回宿舍。这里厨师的通知就是那个“信号”,信号驱动 I/O 与异步 I/O 的区别是“从缓冲区获取数据”这个步骤的处理,前者收到的通知是可以开始进行复制操作了,即要你自己从饭堂拿回宿舍,在复制完成之前线程处于阻塞状态,所以它仍属于同步 I/O 操作,而后者收到的通知是复制操作已经完成,即外卖小哥已经把饭送到了。
客户端负载均衡
案例场景:
假设你身处广东,要上 Fenix’s Bookstore 购买一本书,在程序业务逻辑里,购书其中一个关键步骤是调用商品出库服务来完成货物准备,在代码中该服务的调用请求为:
1 | PATCH https://warehouse:8080/restful/stockpile/3 |
又假设 Fenix’s Bookstore 是个大书店,在北京、武汉、广州的机房均部署有服务集群,你的购物请求从浏览器发出后,服务端按顺序发生了如下事件:
首先是将
warehouse这个服务名称转换为恰当的服务地址,“恰当”是个宽泛的描述,一种典型的“恰当”便是因调用请求来自广东,优先分配给传输距离最短的广州机房来应答。其实按常理来说这次出库服务的调用应该是集群内的流量,而不是用户浏览器直接发出的请求,所以尽管结果没有不同,但更接近实际的的情况是用户访问首页时已经被 DNS 服务器分配到了广州机房,请求出库服务时,应优先选择同机房的服务进行调用,此时请求变为:1
PATCH https://guangzhou-ip-wan:8080/restful/stockpile/3
广州机房的服务网关将该请求与配置中的特征进行比对,由 URL 中的
/restful/stockpile/**得知该请求访问的是商品出库服务,因此,将请求的 IP 地址转换为内网中 warehouse 服务集群的入口地址:1
PATCH https://warehouse-gz-lan:8080/restful/stockpile/3
集群中部署有多个 warehouse 服务,收到调用请求后,负载均衡器要在多个服务中根据某种标准——可能是随机挑选,也可能是按顺序轮询,抑或是选择此前调用次数最少那个,等等。根据均衡策略找出要响应本次调用的服务,称其为
warehouse-gz-lan-node1。1
PATCH https://warehouse-gz-lan-node1:8080/restful/stockpile/3
如果访问
warehouse-gz-lan-node1服务,没有返回需要的结果,而是抛出 500 错。1
HTTP/1.1 500 Internal Server Error
根据预置的故障转移(Failover)策略,重试将调用分配给能够提供该服务的其他节点,称其为
warehouse-gz-lan-node2。1
PATCH https://warehouse-gz-lan-node2:8080/restful/stockpile/3
warehouse-gz-lan-node2服务返回商品出库成功。1
HTTP/1.1 200 OK
以上过程从整体上看,步骤 1、2、3、5,分别对应了服务发现、网关路由、负载均衡和服务容错
客户端负载均衡器
访问请求是由集群内部的某个服务发起,由集群内部的另一个服务进行响应的。一种全新的、独立位于每个服务前端的、分散式的负载均衡方式正逐渐变得流行起来,这就是本节我们要讨论的主角:客户端负载均衡器。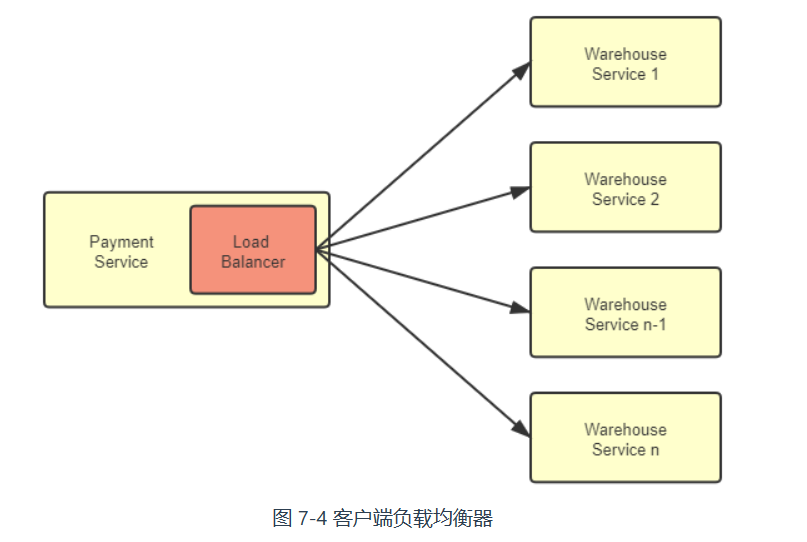
- 客户端均衡器是和服务实例一一对应的,与服务实例在同一个进程之内。
- 均衡器与服务之间信息交换是进程内的方法调用,不存在任何额外的网络开销。
- 不依赖集群边缘的设施,所有内部流量都仅在服务集群的内部循环,避免了出现前文那样,集群内部流量要“绕场一周”的尴尬局面。
- 分散式的均衡器意味着天然避免了集中式的单点问题,它的带宽资源将不会像集中式均衡器那样敏感,这在以七层均衡器为主流、不能通过 IP 隧道和三角传输这样方式节省带宽的微服务环境中显得更具优势。
- 客户端均衡器要更加灵活,能够针对每一个服务实例单独设置均衡策略等参数,访问某个服务,是不是需要具备亲和性,选择服务的策略是随机、轮询、加权还是最小连接等等,都可以单独设置而不影响其它服务。
缺点:
- 同一个进程,意味着难以进行技术异构,使用同一语言开发。
- 共用一个进程,均衡器的稳定性会直接影响整个服务进程的稳定性,同样消耗资源。
- 内部网络安全性
- 服务集群的拓扑关系动态变化,则客户端负载均衡器需要一直轮询服务注册中心。
代理负载均衡器
使用边车代理模式,不是进程内通信,通过网络进行
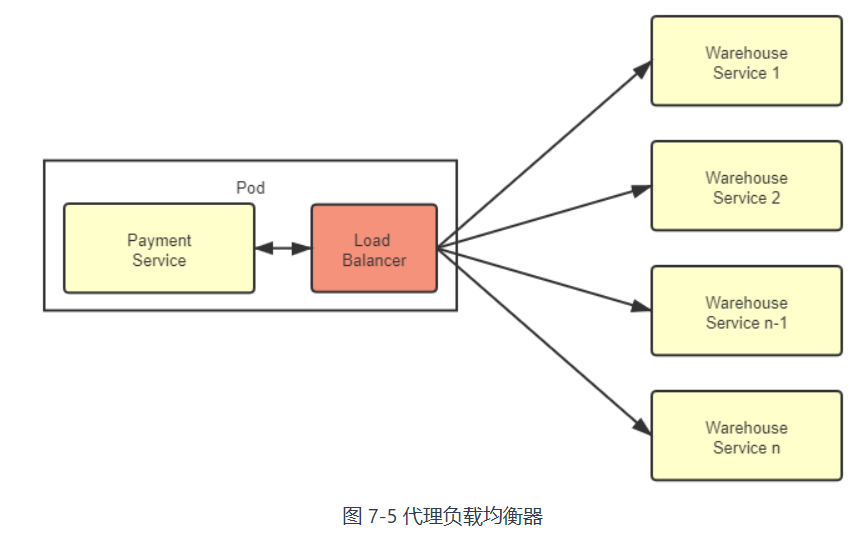
优点:
- 支持了技术异构,独立于服务进程的均衡器也不会由于自身的稳定性影响到服务进程的稳定。
- 在服务拓扑感知方面代理均衡器也要更有优势。由于边车代理接受控制平面的统一管理,当服务节点拓扑关系发生变化时,控制平面就会主动向边车代理发送更新服务清单的控制指令,这避免了此前客户端均衡器必须长期主动轮询服务注册中心所造成的浪费。
- 在安全性、可观测性上,由于边车代理都是一致的实现,有利于在服务间建立双向 TLS 通信,也有利于对整个调用链路给出更详细的统计信息。
地域与区域
- Region:地域,如华北,华东,华南。大型系统就是通过不同地域的机房来缩短用户与服务器之间的物理距离。不同地域之间通过公众互联网连接,而不是内网,服务发现、负载均衡器默认不支持跨地域的服务发现和负载均衡。
- Zone:区域,位于同一地域,如在华东的上海、杭州、苏州的不同机房,使用不同的电力系统和网络系统。同一个区域使用内网连接。
流量治理
容错性设计是微服务中的核心概念,通过服务容错和流量控制等解决方案来尽可能避免。
服务容错
容错策略
- 故障转移:服务有多个副本,失败则切换到其他副本尝试,但有次数上限,不会无限制重试。
- 快速失败:非幂等性服务,需要避免重复调用导致脏数据,如扣款。因此直接返回失败。
- 安全失败:服务有主次之分,如拓展点、事件、AOP注入的日志、调试、审计等功能,假如这些不影响主业务的服务失败了,则主业务应当正确返回,次服务记录一次出错日志即可。
- 沉默失败:若大量服务超时,会导致线程堆积。这种情况就应该先隔离该服务,避免对其他服务的影响。
- 故障恢复:一般是快速失败+故障恢复。它是指当服务调用出错了以后,将该次调用失败的信息存入一个消息队列中,然后由系统自动开始异步重试调用。很显然也是幂等性服务,由于是后台异步重试,适合实时性不高的主路逻辑或旁路逻辑。
- 并行调用:获得最大成功率,双重保险策略。向多个服务副本发送请求,任何一个返回成功即可。(感觉这个也需要幂等服务)
- 广播调用:与并行调用相对,指的是等所有请求都成功,才返回。适用于“刷新分布式缓存”。
| 容错策略 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 故障转移 | 系统自动处理,调用者对失败的信息不可见 | 增加调用时间,额外的资源开销 | 调用幂等服务 对调用时间不敏感的场景 |
| 快速失败 | 调用者有对失败的处理完全控制权 不依赖服务的幂等性 |
调用者必须正确处理失败逻辑,如果一味只是对外抛异常,容易引起雪崩 | 调用非幂等的服务 超时阈值较低的场景 |
| 安全失败 | 不影响主路逻辑 | 只适用于旁路调用 | 调用链中的旁路服务 |
| 沉默失败 | 控制错误不影响全局 | 出错的地方将在一段时间内不可用 | 频繁超时的服务 |
| 故障恢复 | 调用失败后自动重试,也不影响主路逻辑 | 重试任务可能产生堆积,重试仍然可能失败 | 调用链中的旁路服务 对实时性要求不高的主路逻辑也可以使用 |
| 并行调用 | 尽可能在最短时间内获得最高的成功率 | 额外消耗机器资源,大部分调用可能都是无用功 | 资源充足且对失败容忍度低的场景 |
| 广播调用 | 支持同时对批量的服务提供者发起调用 | 资源消耗大,失败概率高 | 只适用于批量操作的场景 |
容错设计模式
断路器模式:设置一个计数器,当服务失败次数达到阈值时,拒绝后续所有服务,直接返回失败,以避免雪崩效应。(服务熔断)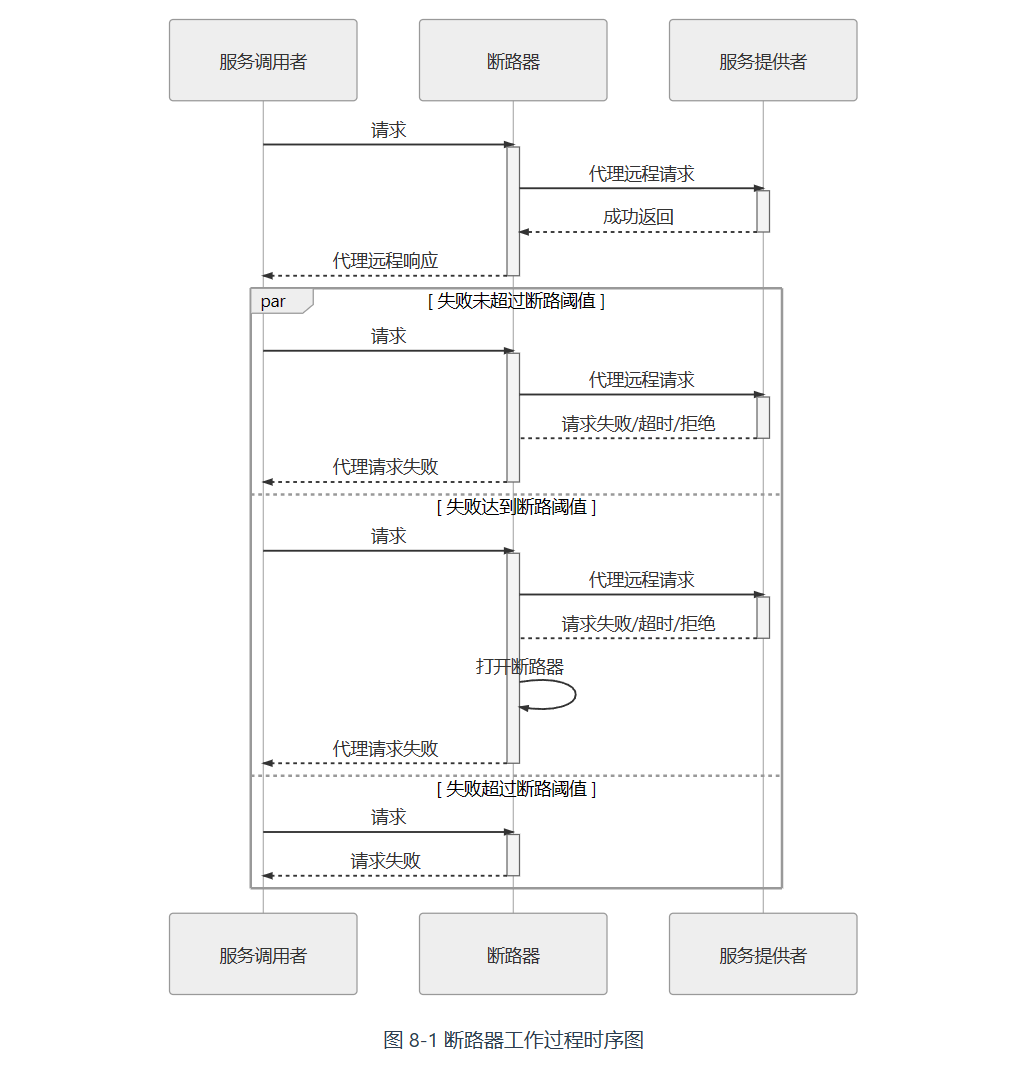
断路器是有限状态机:
- Closed:关闭状态,意味着所有服务会被正常执行和返回。是初始状态
- Open:开启状态,拦截服务,直接返回失败,实现快速失败。
- Half Open:中间状态,表示自动故障修复能力,当断路器处于
Open状态一段时间后,将由下一次请求将其触发为Half Open状态,如果调用成功则恢复至Closed状态,否则继续保持Open
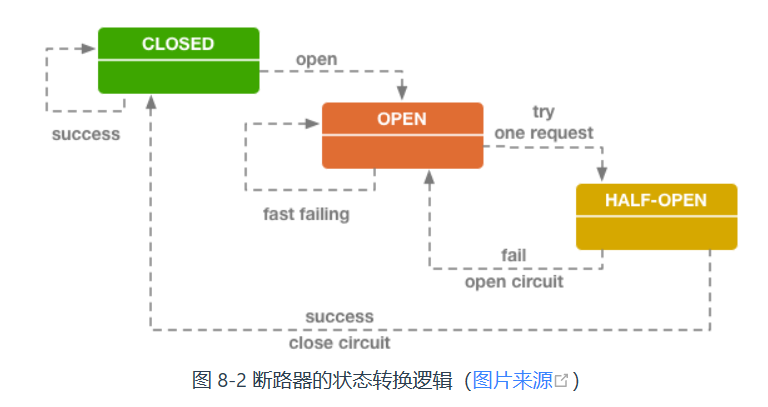
阈值说明:
- 一段时间内(10s),请求数量达到设定阈值(如20个),必须达到某个值,不然无需断路器介入。
- 一段时间内(10s),i请求的故障率达到设定阈值(50%),故障率较高,则说明需要断路器。
舱壁隔离模式
舱壁隔离模式是常用的实现服务隔离的设计模式,舱壁这个词是来自造船业的舶来品,它原本的意思是设计舰船时,要在每个区域设计独立的水密舱室,一旦某个舱室进水,也只是影响这个舱室中的货物,而不至于让整艘舰艇沉没。这种思想就很符合容错策略中失败静默策略。
若系统中服务A发送了超时,由于目前主流的网络访问大多是基于 TPR 并发模型(Thread per Request)来实现的,因此该请求会一直占用该线程。一旦达到例如Tomcat的最大全局线程数量,则所有其他服务也会因为没有空余的线程服务而导致不可用,产生雪崩。
因此,可以为每个服务单独的设置线程池,如每个服务设置5个最大线程数,这样该服务超时,最多阻塞5条线程数,不会导致别的服务也没法用。但局部线程池会增大CPU的开销,导致增加3-10ms的请求处理时间。可以进一步采用信号量机制取代局部线程池,为每个服务设置一个线程安全的计数器即可。
重试模式故障转移和故障恢复策略都需要对服务进行重复调用,差别是这些重复调用有可能是同步的,也可能是后台异步进行;有可能会重复调用同一个服务,也可能会调用到服务的其他副本。无论具体是通过怎样的方式调用、调用的服务实例是否相同,都可以归结为重试设计模式的应用范畴。适用于有可能自己恢复的临时性失灵,网络抖动,临时过载等。
- 仅主路逻辑的关键服务进行同步重试。
- 仅对瞬时故障到的失败(可根据状态码判断),即可自愈的服务。
- 仅对幂等性服务重试。
- 必须有终止条件。
- 超时终止,避免无限期等待
- 次数终止,最多重试2-5次,不可以无限次重试。
可靠通讯
零信任网络
表 9-1 传统网络安全模型与云原生时代零信任模型对比
| 传统、边界安全模型 | 云原生、零信任安全模型 | 具体需求 |
|---|---|---|
| 基于防火墙等设施,认为边界内可信 | 服务到服务通信需认证,环境内的服务之间默认没有信任 | 保护网络边界(仍然有效);服务之间默认没有互信 |
| 用于特定的 IP 和硬件(机器) | 资源利用率、重用、共享更好,包括 IP 和硬件 | 受信任的机器运行来源已知的代码 |
| 基于 IP 的身份 | 基于服务的身份 | 同上 |
| 服务运行在已知的、可预期的服务器上 | 服务可运行在环境中的任何地方,包括私有云/公有云混合部署 | 同上 |
| 安全相关的需求由应用来实现,每个应用单独实现 | 由基础设施来实现,基础设施中集成了共享的安全性要求。 | 集中策略实施点(Choke Points),一致地应用到所有服务 |
| 对服务如何构建、评审、实施的安全需求的约束力较弱 | 安全相关的需求一致地应用到所有服务 | 同上 |
| 安全组件的可观测性较弱 | 有安全策略及其是否生效的全局视图 | 同上 |
| 发布不标准,发布频率较低 | 标准化的构建和发布流程,每个微服务变更独立,变更更频繁 | 简单、自动、标准化的变更发布流程 |
| 工作负载通常作为虚拟机部署或部署到物理主机,并使用物理机或管理程序进行隔离 | 封装的工作负载及其进程在共享的操作系统中运行,并有管理平台提供的某种机制来进行隔离 | 在共享的操作系统的工作负载之间进行隔离 |
服务安全
建立信任
零信任网络不存在默认的信任关系,只可通过权威公证人:公开密钥基础设施PKI。通过PKI构建传输安全层(TLS)。在零信任网络安全中,常常使用双向TSL认证。
单向 TLS 认证:只需要服务端提供证书,客户端通过服务端证书验证服务器的身份,但服务器并不验证客户端的身份。单向 TLS 用于公开的服务,即任何客户端都被允许连接到服务进行访问,它保护的重点是客户端免遭冒牌服务器的欺骗。
双向 TLS 认证:客户端、服务端双方都要提供证书,双方各自通过对方提供的证书来验证对方的身份。双向 TLS 用于私密的服务,即服务只允许特定身份的客户端访问,它除了保护客户端不连接到冒牌服务器外,也保护服务端不遭到非法用户的越权访问。
认证
参考Spring Security
授权
谁拥有什么权限,RBAC模型
在Spring Security中可以通过两种方式配置,一种是在配置类中,另一种是通过注解标明到方法体上
可观测性
学术界一般会将可观测性分解为三个更具体方向进行研究,分别是:事件日志、链路追踪和聚合度量
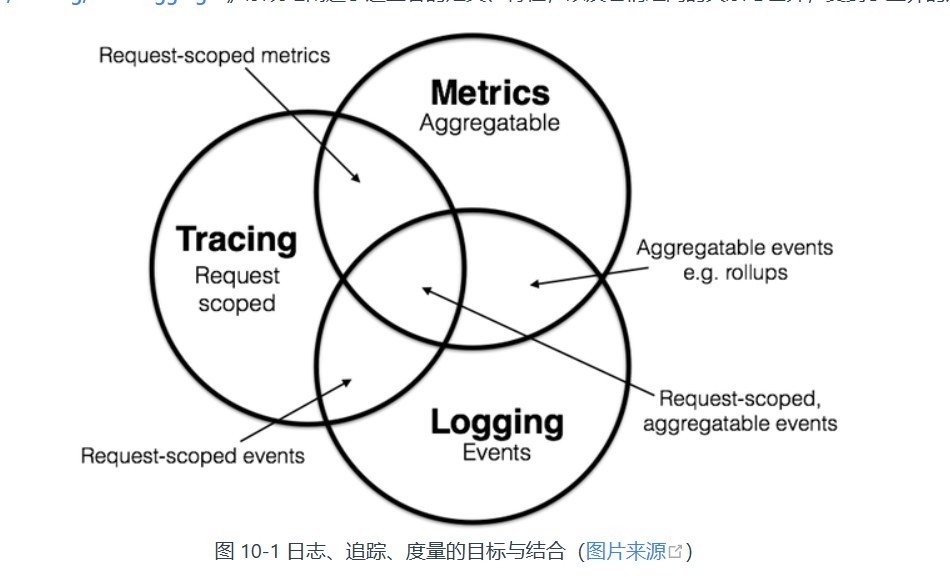
- 日志(Logging):记录事件,分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。
- 追踪(Tracing):全链路追踪,追踪的主要目的是排查故障,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期。
- 度量(Metrics):对系统中某一类信息的统计聚合。度量的主要目的是监控(Monitoring)和预警(Alert),如某些度量指标达到风险阈值时触发事件,以便自动处理或者提醒管理员介入。
事件日志
- 避免打印敏感信息。
- 避免引用慢操作。
- 避免打印追踪诊断信息
- 避免误导他人
- 记录请求时的TraceID
- 系统运行过程中的关键事件
- 启动时输出配置信息
| 数据项 | 值 |
|---|---|
| IP | 14.123.255.234 |
| Username | null |
| Datetime | 19/Feb/2020:00:12:11 +0800 |
| Method | GET |
| URL | /index.html |
| Protocol | HTTP/1.1 |
| Status | 200 |
| Size | 1314 |
| Refer | https://icyfenix.cn |
| Agent | Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36 |
链路追踪
聚合度量
指标收集
- 计数度量器(Counter):这是最好理解也是最常用的指标形式,计数器就是对有相同量纲、可加减数值的合计量,譬如业务指标像销售额、货物库存量、职工人数等等;技术指标像服务调用次数、网站访问人数等都属于计数器指标。
- 瞬态度量器(Gauge):瞬态度量器比计数器更简单,它就表示某个指标在某个时点的数值,连加减统计都不需要。譬如当前 Java 虚拟机堆内存的使用量,这就是一个瞬态度量器;又譬如,网站访问人数是计数器,而网站在线人数则是瞬态度量器。
- 吞吐率度量器(Meter):吞吐率度量器顾名思义是用于统计单位时间的吞吐量,即单位时间内某个事件的发生次数。譬如交易系统中常以 TPS 衡量事务吞吐率,即每秒发生了多少笔事务交易;又譬如港口的货运吞吐率常以“吨/每天”为单位计算,10 万吨/天的港口通常要比 1 万吨/天的港口的货运规模更大。
- 直方图度量器(Histogram):直方图是常见的二维统计图,它的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条图的形式表示具体数值。譬如经济报告中要衡量某个地区历年的 GDP 变化情况,常会以 GDP 为纵坐标,时间为横坐标构成直方图来呈现。
- 采样点分位图度量器(Quantile Summary):分位图是统计学中通过比较各分位数的分布情况的工具,用于验证实际值与理论值的差距,评估理论值与实际值之间的拟合度。譬如,我们说“高考成绩一般符合正态分布”,这句话的意思是:高考成绩高低分的人数都较少,中等成绩的较多,将人数按不同分数段统计,得出的统计结果一般能够与正态分布的曲线较好地拟合。
- 除了以上常见的度量器之外,还有 Timer、Set、Fast Compass、Cluster Histogram 等其他各种度量器,采用不同的度量系统,支持度量器类型的范围肯定会有差别,譬如 Prometheus 支持了上面提到五种度量器中的 Counter、Gauge、Histogram 和 Summary 四种。
表 10-2 常用 Exporter
| 范围 | 常用 Exporter |
|---|---|
| 数据库 | MySQL Exporter、Redis Exporter、MongoDB Exporter、MSSQL Exporter 等 |
| 硬件 | Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter、Node Exporter 等 |
| 消息队列 | Beanstalkd Exporter、Kafka Exporter、NSQ Exporter、RabbitMQ Exporter 等 |
| 存储 | Ceph Exporter、Gluster Exporter、HDFS Exporter、ScaleIO Exporter 等 |
| HTTP 服务 | Apache Exporter、HAProxy Exporter、Nginx Exporter 等 |
| API 服务 | AWS ECS Exporter, Docker Cloud Exporter、Docker Hub Exporter、GitHub Exporter 等 |
| 日志 | Fluentd Exporter、Grok Exporter 等 |
| 监控系统 | Collectd Exporter、Graphite Exporter、InfluxDB Exporter、Nagios Exporter、SNMP Exporter 等 |
| 其它 | Blockbox Exporter、JIRA Exporter、Jenkins Exporter, Confluence Exporter 等 |
存储查询
避免日志过于庞大,引入
时序数据库。
- 以日志结构的合并树(Log Structured Merge Tree,LSM-Tree)代替传统关系型数据库中的B+Tree作为存储结构,LSM 适合的应用场景就是写多读少,且几乎不删改的数据。
- 设置激进的数据保留策略,譬如根据过期时间(TTL)自动删除相关数据以节省存储空间,同时提高查询性能。对于普通数据库来说,数据会存储一段时间后就会被自动删除这种事情是不可想象的。
- 对数据进行再采样(Resampling)以节省空间,譬如最近几天的数据可能需要精确到秒,而查询一个月前的数据时,只需要精确到天,查询一年前的数据时,只要精确到周就够了,这样将数据重新采样汇总就可以极大节省存储空间。