MIT6.830-Lab1
Lab1
在6.830的实验作业中,你将编写一个名为SimpleDB的基本数据库管理系统。在本实验中,您将专注于实现访问磁盘上存储的数据所需的核心模块;在未来的实验中,您将添加对各种查询处理操作符以及事务、锁定和并发查询的支持。
SimpleDB用Java编写。我们为您提供了一组大部分未实现的类和接口。您需要为这些类编写代码。我们将通过运行一组使用[JUnit]编写的系统测试来给你的代码打分。我们还提供了一些单元测试,我们不会将其用于评分,但您可能会发现它们在验证代码工作时很有用。我们还鼓励您在我们的测试之外开发您自己的测试套件。
本文的其余部分描述了SimpleDB的基本架构,给出了一些关于如何开始编码的建议,并讨论了如何提交实验。我们强烈建议你尽早开始这个实验。它需要您编写相当多的代码!
提示
- 您需要填写任何未实现的代码。在我们认为您应该编写代码的地方,这将是显而易见的。您可能需要添加私有方法或辅助类。您可以更改 API,但确保我们的评分测试仍然运行,并确保在写作中提到、解释和捍卫您的决定。
- 以下是您实施 SimpleDB 的一种粗略方法:
- 你正在实现用于管理元组的类,即Tuple和TupleDesc。我们已经为您实现了Field、IntField、StringField和Type。由于您只需要支持整数和(固定长度的)字符串字段以及固定长度的元组,因此这些都很简单。
- 请实现Catalog(这应该非常简单)。
- 实现BufferPool的构造函数和getPage()方法。
- 实现访问方法,HeapPage和HeapFile以及相关的ID类。其中许多文件的大部分已经为您编写。
- 实现操作符SeqScan。
在这一点上,您应该能够通过ScanTest系统测试,这是此实验的目标。
事务、锁和恢复
当您查看我们提供给您的接口时,您会看到许多与锁、事务和恢复有关的引用。在这个实验中,您无需支持这些功能,但应该在代码的接口中保留这些参数,因为您将在以后的实验中实现事务和锁。我们提供给您的测试代码生成了一个虚假的事务ID,将其传递给运行查询的操作符;您应该将此事务ID传递给其他操作符和缓冲池。
SimpleDB 架构和实现指南
- 代表字段、元组和元组模式的类;
- 将谓词和条件应用于元组的类;
- 一个或多个访问方法(例如,堆文件),用于在磁盘上存储关系并提供通过这些关系的元组的迭代方式;
- 一组操作符类(例如,select、join、insert、delete等),用于处理元组;
- 一个缓冲池,用于在内存中缓存活动元组和页面,并处理并发控制和事务(在此实验中,您无需担心这两者);
- 一个存储有关可用表及其模式的信息的目录。
SimpleDB并不包括您可能认为是“数据库”一部分的许多内容。特别是,SimpleDB没有:
- (在此实验中)SQL前端或解析器,允许您直接在SimpleDB中输入查询。相反,查询是通过将一组操作符链接到手动构建的查询计划中而构建的(参见第2.7节)。我们将在以后的实验中提供一个简单的解析器。
- 视图。
- 除整数和固定长度字符串之外的数据类型。
- (在此实验中)查询优化器。
- (在此实验中)索引。
在本节的其余部分,我们将描述SimpleDB的每个主要组件,您需要在此实验中实现这些组件。您应该使用本讨论中的练习来指导您的实现。这份文档并不是SimpleDB的完整规范;您需要决定如何设计和实现系统的各个部分。请注意,在实验1中,您无需实现任何操作符(例如,select、join、project),只需顺序扫描。您将在以后的实验中添加对其他操作符的支持。
Database class
Database 类提供对一组静态对象的访问,这些对象是数据库的全局状态。具体而言,这包括访问目录(数据库中所有表的列表)、缓冲池(当前驻留在内存中的数据库文件页面的集合)以及日志文件的方法。在此实验中,您无需担心日志文件。我们已经为您实现了 Database 类。您应该查看这个文件,因为您将需要访问这些对象。
Fields和Tuples
SimpleDB 中的元组非常基础。它们由一组 Field 对象组成,每个元组中有一个 Field。Field 是一个接口,不同的数据类型(例如,整数、字符串)都会实现它。Tuple 对象由底层访问方法(例如,堆文件或 B 树)创建,如下一节所述。元组还有一个类型(或模式),称为元组描述符(_tuple descriptor_),由 TupleDesc 对象表示。该对象包含一组 Type 对象,每个字段对应一个 Type,它描述相应字段的类型。
Exercise 1
实现下面类中的部分方法:
- src/java/simpledb/storage/TupleDesc.java
- src/java/simpledb/storage/Tuple.java
此时,您的代码应能通过单元测试 TupleTest 和 TupleDescTest。此时,modifyRecordId() 应该会失败,因为您还没有实现它。
Catalog
目录(SimpleDB 中的 Catalog 类)包含当前数据库中的表和表模式的列表。您需要支持添加新表的功能,以及获取关于特定表的信息。与每个表相关联的是一个 TupleDesc 对象,它允许操作符确定表中字段的类型和数量。
全局目录是 SimpleDB 进程中分配的 Catalog 的单个实例。可以通过 Database.getCatalog() 方法检索全局目录,全局缓冲池也是如此(使用 Database.getBufferPool() 方法)。
Exercise 2
实现下面类中的部分方法:
- src/java/simpledb/common/Catalog.java
此时你应该可以通过CatalogTest
BufferPool
缓冲池(SimpleDB 中的 BufferPool 类)负责缓存最近从磁盘读取的页面到内存中。所有操作符通过缓冲池从磁盘的不同文件中读取和写入页面。它由一定数量的页面组成,该数量由 BufferPool 构造函数的 numPages 参数定义。在后续的实验中,您将实现一个淘汰策略。对于这个实验,您只需要实现构造函数和被 SeqScan 操作符使用的 BufferPool.getPage() 方法。缓冲池应该最多存储 numPages 个页面。对于这个实验,如果对不同页面进行了超过 numPages 次的请求,而没有实现淘汰策略,您可以抛出一个 DbException。在以后的实验中,您将被要求实现淘汰策略。
Exercise 3
实现 getPage() 方法:
- src/java/simpledb/storage/BufferPool.java
我们没有为 BufferPool 提供单元测试。您实现的功能将在下面的 HeapFile 实现中进行测试。您应使用 DbFile.readPage 方法访问 DbFile 的页面。
HeapFile access method
访问方法提供了一种从磁盘读取或写入以特定方式排列的数据的方式。常见的访问方法包括heap文件(Tuples的无序文件)和 B 树;对于这个任务,您只需要实现堆文件访问方法,我们已经为您编写了部分代码。
一个HeapFile 对象被组织成一组页面,每个页面包括用于存储元组的固定字节数(由常量 BufferPool.DEFAULT_PAGE_SIZE 定义),包括一个头部。在 SimpleDB 中,每个数据库表对应一个 HeapFile 对象。HeapFile 中的每个页面都被组织为一组插槽,每个插槽可以容纳一个元组(在 SimpleDB 中,给定表的元组大小都相同)。除了这些插槽外,每个页面都有一个头部,包括一个位图,每个位表示一个元组插槽。如果与特定元组对应的位为 1,则表示该元组有效;如果为 0,则该元组无效(例如,已删除或从未初始化)。HeapFile 对象的页面属于 HeapPage 类型,该类实现了 Page 接口。页面存储在缓冲池中,但由 HeapFile 类进行读取和写入。
SimpleDB 在磁盘上以大致相同的格式存储堆文件,如同它们在内存中存储的方式。每个文件由按顺序排列在磁盘上的页面数据组成。每个页面包括表示头部的一个或多个字节,后跟实际页面内容的 页面大小 字节。每个元组需要 tuple size * 8 位用于其内容和 1 位用于头部。因此,一个单页中可以容纳的元组数量是:
$$
tuplesPerPage = floor((pageSize * 8) / (tupleSize * 8 + 1))
$$
其中,tupleSize 是页面中元组的大小,以字节为单位。这里的思路是每个元组在头部需要额外的一位存储空间。我们计算页面中的位数(通过将页面大小乘以 8),并将此数量除以元组中的位数(包括这个额外的头部位),以得到每页的Tuple数。floor 操作向下取整到最接近的整数元组数(我们不希望在页面上存储部分元组!)
一旦我们知道每页的元组数,存储头部所需的字节数就是:(1个元组需要1bit,换算向上取整就得到了)
$$headerBytes = ceiling(tuplesPerPage / 8)
$$
ceiling 操作向上取整到最接近的整数字节数(我们永远不存储少于一个完整字节的头部信息)。
每个字节的低位(最不重要位)表示文件中较早的插槽的状态。因此,第一个字节的最低位表示页面中第一个插槽是否正在使用。第一个字节的次低位表示页面中第二个插槽是否正在使用,依此类推。还要注意,最后一个字节的高位可能不对应于实际在文件中的插槽,因为插槽的数量可能不是 8 的倍数。同时注意,所有的 Java 虚拟机都是大端序。
Exercise 4
实现以下类中的方法:
- src/java/simpledb/storage/HeapPageId.java
- src/java/simpledb/storage/RecordId.java
- src/java/simpledb/storage/HeapPage.java
尽管在Lab 1中您不会直接使用它们,但我们要求您在 HeapPage 中实现 getNumEmptySlots() 和 isSlotUsed() 方法。这些方法需要在页面头部传递位。您可能会发现查看已在 HeapPage 或 src/simpledb/HeapFileEncoder.java 中提供的其他方法有助于理解页面的布局。
您还需要在页面上实现一个迭代器,用于遍历其中的元组,这可能涉及到一个辅助类或数据结构。
在此阶段,您的代码应该通过 HeapPageIdTest、RecordIDTest 和 HeapPageReadTest 中的单元测试。
在您实现了 HeapPage 后,您将在此实验中为 HeapFile 编写方法,以计算文件中的页面数并从文件中读取页面。然后,您将能够从存储在磁盘上的文件中获取元组。
Exercise 5
实现以下类中的方法:
- src/java/simpledb/storage/HeapFile.java
为了从磁盘读取页面,首先需要计算文件中的正确偏移量。提示:为了能够在任意偏移量读取和写入页面,你需要对文件进行随机访问。在从磁盘读取页面时,不应调用 BufferPool 方法。
你还需要实现 HeapFile.iterator() 方法,该方法应该迭代遍历 HeapFile 中每个页面的元组。迭代器必须使用 BufferPool.getPage() 方法来访问 HeapFile 中的页面。此方法将页面加载到缓冲池中,并最终将在以后的实验中用于实现基于锁的并发控制和恢复。不要在 open() 调用时将整个表加载到内存中,这会导致对于非常大的表发生内存溢出错误。
到目前为止,你的代码应该通过 HeapFileReadTest 中的单元测试。
Operators
运算符负责执行查询计划的实际操作,它们实现了关系代数的各种操作。在SimpleDB中,运算符是基于迭代器的;每个运算符实现了DbIterator接口。
运算符通过将较低级别的运算符传递到较高级别运算符的构造函数中连接在一起,即通过“链接它们在一起”。在计划的底层,叶子节点处的特殊访问方法运算符负责从磁盘读取数据(因此它们下面没有任何运算符)。
在计划的顶部,与SimpleDB交互的程序只需对根运算符调用getNext;然后,此运算符在其子运算符上调用getNext,依此类推,直到调用这些叶子运算符。它们从磁盘获取元组并将其传递到树上(作为getNext的返回参数);元组以这种方式在计划中传播,直到它们在根处输出,或者由计划中的另一个运算符组合或拒绝。
在这个实验中,您只需要实现一个SimpleDB运算符。
Exercise 6
实现以下类中的方法:
- src/java/simpledb/execution/SeqScan.java
这个运算符按顺序扫描构造函数中指定的tableid对应表的所有元组。这个运算符应该通过DbFile.iterator()方法访问元组。
在这一点上,您应该能够完成ScanTest系统测试。做得好!
在后续的实验中,您将填写其他运算符。
A simple query
这部分的目的是说明这些不同的组件是如何连接在一起来处理一个简单的查询的。
假设你有一个名为 “some_data_file.txt” 的数据文件,其内容如下:
1 | 1,1,1 |
您可以将其转换为SimpleDB可以查询的二进制文件,如下所示:java -jar dist/simpledb.jar convert some_data_file.txt 3
这里,参数 “3” 告诉 convert 输入有3列。
以下代码实现了对此文件的简单选择查询。该代码等效于 SQL 语句 SELECT * FROM some_data_file。
1 | package simpledb; |
我们创建的表具有三个整数字段。为了表示这一点,我们创建一个 TupleDesc 对象,并向其传递一个 Type 对象的数组,以及一个可选的 String 字段名数组。创建了 TupleDesc 后,我们初始化一个 HeapFile 对象,该对象表示存储在 some_data_file.dat 中的表。创建表后,我们将其添加到目录中。如果这是一个已经在运行的数据库服务器,那么目录信息已经被加载了。我们需要显式加载它,以使这段代码是自包含的。
初始化数据库系统后,我们创建一个查询计划。我们的计划仅包含扫描磁盘上的元组的 SeqScan 运算符。通常情况下,这些运算符被实例化为引用适当的表(对于 SeqScan)或子运算符(例如 Filter 的情况)。测试程序然后重复在 SeqScan 运算符上调用 hasNext 和 next。当元组从 SeqScan 输出时,它们将在命令行上打印出来。
我们强烈建议您尝试这个作为一个有趣的端到端测试,这将帮助您获得编写简单数据库的测试程序的经验。您应该在 src/java/simpledb 目录中创建名为 “test.java” 的文件,其中包含上述代码,您应该在代码上方添加一些 “import” 语句,并将 some_data_file.dat 文件放在顶级目录中。然后运行:
1 | ant |
请注意,ant 会编译 test.java 并生成一个包含它的新的 JAR 文件。
实现
首先需要知道每个类的作用和类之间的结构关系。
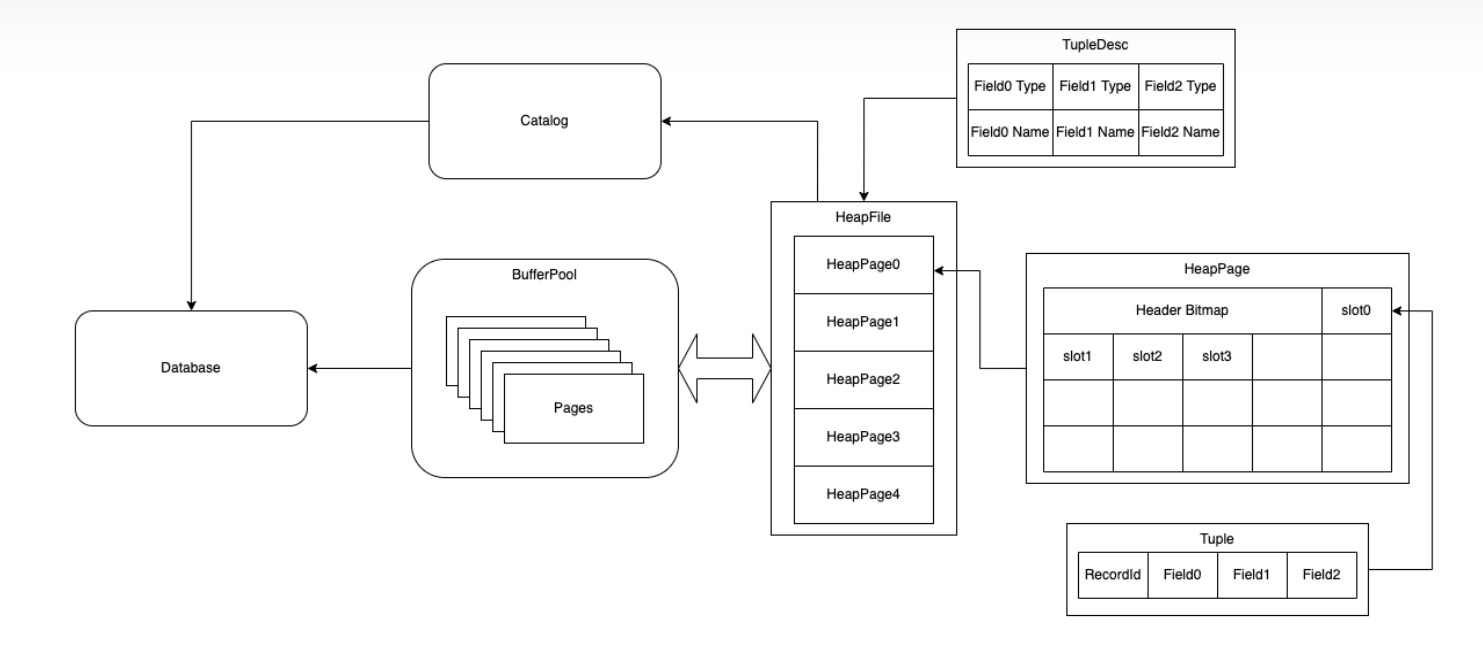
TupleDsec:用来描述一张表的表结构。其由若干个TdItem构成,每个TdItem存储了表字段的名称和类型。比如对于学生表,可能有<姓名,String>,<年龄,int>。Tuple:用来表示数据库表的行数据,由若干个Field构成,每个Field存储了字段类型和值。本项目中只有IntField和StringField,分别表示整数和字符串。Database:数据库实例,存放了Catalog和BufferPool以及LogFile。Catalog:全局唯一,管理数据库中所有表的信息。tableId,table Pk,TableName,HeapFile。该类有添加新的数据库表,查询表的相关信息功能。BufferPool:全局唯一,缓冲池。此外提供了事物机制以及缓存了高频Page。HeapFile:实现DbFile,一张数据库表与一个HeapFile一一对应,是存储Page的载体,可以通过计算偏移量来读取某一Page。HeapPage:实现Page,一个数据库表由若干Page组成,存放了header和tuples信息。可以理解为在磁盘上,一张表被分成了若干页进行存储。HeapPageId:实现PageId,通过tableId以及PageNo,唯一的标识了一张表中的某一Page。RecordId:通过tupleNo和PageId,唯一标识了一个Page中的某一Tuple,可以理解为一张表中的某行。
下面的图展示了Lab1涉及到的所有类的关系。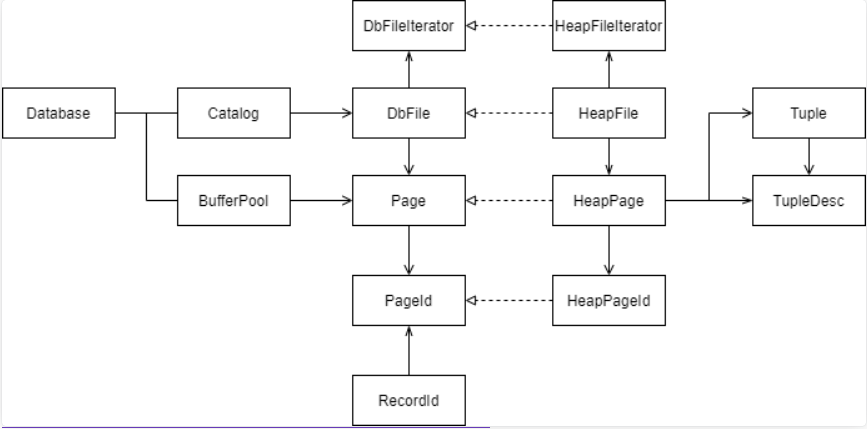
simpleDB查询原理:一个query被组织成operator树,底层operator被传递给上层operator的构造器。最底层叶子结点代表access method,从disk中读取tuple;顶层的operator只需要不断调用getNext(),即可输出符合条件的查询结果。顶层的getNext()调用会不断向下传递,直到access method,然后读取tuple再向上传递。如果query中只包含简单的数据筛选,如value > 100,那么整个query树是可以pipeline化的,数据自底向上源源不断的传递,输出;但是遇上join这种operator,就需要其中一个子节点输出所有tuple后才能继续向上传递。