MIT6.830-Lab5
介绍
在这个实验中,你将实现一个B+树索引,用于高效的查找和范围扫描。我们已经为你提供了所有需要实现树结构的底层代码。你将实现搜索、页面分裂、在页面之间重新分配元组以及页面合并。
阅读教材中的第10.3至10.7节可能会对B+树的结构以及搜索、插入和删除的伪代码有详细的了解,这可能对你有所帮助。
正如教材和课堂上讨论的那样,B+树中的内部节点包含多个条目,每个条目由一个键值、一个左子指针和一个右子指针组成。相邻的键共享一个子指针,因此包含m个键的内部节点有m+1个子指针。叶子节点可以包含数据条目,也可以包含指向其他数据库文件中的数据条目的指针。为了简化起见,我们将实现一个B+树,其中叶子页面实际上包含数据条目。相邻的叶子页面通过右和左兄弟指针链接在一起,因此范围扫描只需要通过根和内部节点进行一次初始搜索,以找到第一个叶子页面。随后的叶子页面通过跟随右(或左)兄弟指针找到。
任务
Search
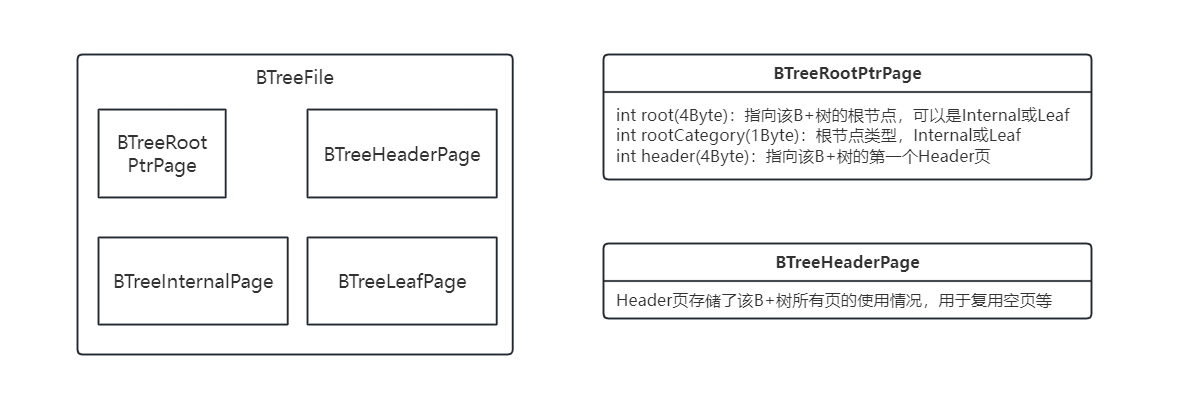
查看index/和BTreeFile.java。这是B+树实现的核心文件,也是你在本实验中编写所有代码的地方。与HeapFile不同,BTreeFile由四种不同类型的页面组成。正如你所预期的那样,树的节点有两种不同类型的页面:内部页面和叶子页面。内部页面的实现在BTreeInternalPage.java中,叶子页面的实现在BTreeLeafPage.java中。为了方便起见,我们在BTreePage.java中创建了一个抽象类,其中包含对叶子和内部页面都通用的代码。此外,头部页面的实现在BTreeHeaderPage.java中,用于跟踪文件中哪些页面正在使用。最后,在每个BTreeFile的开头有一个页面,它指向树的根页面和第一个头部页面。这个单例页面的实现在BTreeRootPtrPage.java中。熟悉这些类的接口,特别是BTreePage、BTreeInternalPage和BTreeLeafPage。你需要在实现B+树时使用这些类。
你的第一个任务是在BTreeFile.java中实现findLeafPage()函数。该函数用于找到给定特定键值的适当叶子页面,用于搜索和插入操作。例如,假设我们有一个具有两个叶子页面的B+树(见图1)。根节点是一个内部页面,带有一个条目其包含了一个键(在本例中为6)和两个子指针。给定值1,此函数应返回第一个叶子页面。同样,给定值8,此函数应返回第二个页面。较不明显的情况是,如果我们给定键值6,由于可能存在重复的键,因此两个叶子页面上可能都有6。在这种情况下,该函数应返回第一个(左侧)叶子页面。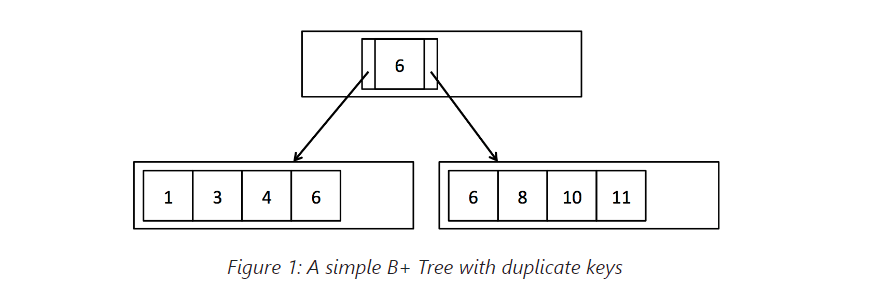
你的findLeafPage()函数应该通过递归搜索内部节点,直到找到与提供的键值相对应的叶子页面。为了找到每一步的适当子页面,你应该迭代内部页面中的条目,并将条目值与提供的键值进行比较。BTreeInternalPage.iterator()提供了使用BTreeEntry.java中定义的接口访问内部页面条目的方式。这个迭代器允许你遍历内部页面的键值,并访问每个键的左右子页面ID。递归的基本情况是当传入的BTreePageId的pgcateg()等于BTreePageId.LEAF时,表示它是一个叶子页面。在这种情况下,你只需从缓冲池中获取页面并返回。无需确认它是否实际包含提供的键值 f。
你的findLeafPage()代码还必须处理提供的键值 f 为 null 的情况。如果提供的值为 null,则每次都要递归到最左侧的子页面,以找到最左侧的叶子页面。找到正确的叶子页面后,应返回它。如上所述,你可以使用BTreePageId.java中的pgcateg()函数检查页面的类型。你可以假设只有叶子页面和内部页面会传递到此函数。
建议使用我们提供的包装函数BTreeFile.getPage(),而不是直接调用BufferPool.getPage()来获取每个内部页面和叶子页面。它的工作方式与BufferPool.getPage()完全相同,但接受额外的参数来跟踪脏页列表。在接下来的两个练习中,你将实际更新数据,因此需要跟踪脏页,这使得这个函数变得重要。
你的findLeafPage()实现访问的每个内部(非叶)页面应该以READ_ONLY权限获取,除了返回的叶子页面,叶子页面应该以作为函数参数提供的权限获取。虽然权限级别在本实验中可能不重要,但对于代码在未来实验中正确运行至关重要。
Exercise 1: BTreeFile.findLeafPage()
实现BTreeFile.findLeafPage().
完成这个练习后,你应该能够通过BTreeFileReadTest.java中的所有单元测试和BTreeScanTest.java中的系统测试。
Insert
为了保持B+树元组的有序性并维护树的完整性,我们必须将元组插入到具有包围键范围的叶子页面中。正如上面提到的,findLeafPage()可以用于找到应将元组插入的正确叶子页面。然而,每个页面有限数量的插槽,我们需要能够插入元组,即使相应的叶子页面已满。
如教材所述,尝试将元组插入已满的叶子页面应导致该页面拆分,使元组均匀分布在两个新页面之间。每当叶子页面拆分时,将需要向父节点添加一个对应于第二页中的第一个元组的新条目。偶尔,内部节点可能也已满,无法接受新的条目。在这种情况下,父节点应拆分并向其父节点添加一个新条目。这可能导致递归拆分,最终创建一个新的根节点。
在这个练习中,你将在BTreeFile.java中实现splitLeafPage()和splitInternalPage()。如果被拆分的页面是根页面,你将需要创建一个新的内部节点作为新的根页面,并更新BTreeRootPtrPage。否则,你将需要以READ_WRITE权限获取父页面,如果有必要,递归拆分它,并添加一个新条目。你将发现getParentWithEmptySlots()函数非常有用,用于处理这些不同的情况。在splitLeafPage()中,你应该将键“复制”到父页面,而在splitInternalPage()中,你应该将键“推送”到父页面。如果这令人困惑,请参阅图2并回顾教材第10.5节。记得根据需要更新新页面的父指针(为简单起见,在图中我们未显示父指针)。当内部节点被拆分时,你将需要更新所有已移动的子节点的父指针。你可能会发现updateParentPointers()函数对于这个任务很有用。此外,请记得更新任何已拆分的叶子页面的兄弟指针。最后,返回应插入新元组或条目的页面,如提供的键字段所示。(提示:你不需要担心提供的键实际上可能正好位于要拆分的元组/条目的正中央。在拆分过程中,你应该忽略键,仅使用它来确定应返回的两个页面中的哪一个。)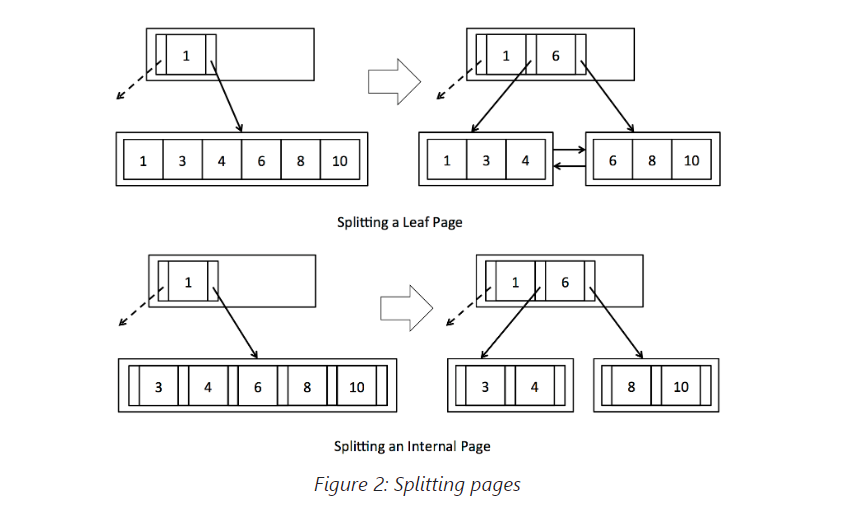
在创建新页面时,无论是由于拆分页面还是创建新的根页面,都要调用getEmptyPage()来获取新页面。此函数是一个抽象,它将允许我们重用由于合并而被删除的页面(在下一节中讨论)。
我们期望你将使用BTreeLeafPage.iterator()和BTreeInternalPage.iterator()与叶子页面和内部页面进行交互,以遍历每个页面中的Tuple/Entry。为方便起见,我们还为两种类型的页面提供了反向迭代器:BTreeLeafPage.reverseIterator()和BTreeInternalPage.reverseIterator()。这些反向迭代器在从页面移到其右兄弟的子集中特别有用。
如上所述,内部页面迭代器使用BTreeEntry.java中定义的接口,该接口具有一个键和两个子指针。它还有一个recordId,用于标识底层页面上键和子指针的位置。我们认为一次处理一个条目是与内部页面交互的一种自然方式,但重要的是要记住,底层页面实际上并不存储条目列表,而是存储有序列表的 m 个键和 m+1 个子指针。由于BTreeEntry只是一个接口,而不是实际存储在页面上的对象,更新BTreeEntry的字段不会修改底层页面。为了更改页面上的数据,你需要调用BTreeInternalPage.updateEntry()。此外,删除一个条目实际上只删除一个键和一个单独的子指针,因此我们提供了函数BTreeInternalPage.deleteKeyAndLeftChild()和BTreeInternalPage.deleteKeyAndRightChild()来明确此操作。条目的recordId用于找到要删除的键和子指针。插入一个条目也只插入一个键和一个单独的子指针(除非是第一个条目),因此BTreeInternalPage.insertEntry()检查提供的条目中的一个子指针是否与页面上的现有子指针重叠,并且在该位置插入条目是否会保持键的排序顺序。
在splitLeafPage()和splitInternalPage()中,你将需要更新脏页集,其中包括任何新创建的页面以及由于新指针或新数据而修改的任何页面。这就是BTreeFile.getPage()将会派上用场的地方。每次获取页面时,BTreeFile.getPage()都会检查页面是否已存储在本地缓存(dirtypages)中,如果在那里找不到请求的页面,则从缓冲池中获取它。由于BTreeFile.getPage()假设很快这些页面将被标记为脏页,因此它还会将以读写权限获取的页面添加到dirtypages缓存中。这种方法的一个优点是它防止在单个元组插入或删除期间多次访问相同页面时丢失更新。
请注意,与HeapFile.insertTuple()有很大不同,BTreeFile.insertTuple()可能会返回一组大的脏页,特别是如果有任何内部页面被拆分。正如你可能记得的之前的实验中一样,返回脏页集是为了防止缓冲池在刷新之前驱逐脏页。
警告:由于B+树是一种复杂的数据结构,在修改它之前了解每个合法B+树必需的属性是有帮助的。以下是一个非正式的列表:
- 如果父节点指向子节点,则子节点必须指回相同的父节点。
- 如果叶节点指向右兄弟,则右兄弟必须指回该叶节点作为左兄弟。
- 第一个和最后一个叶子必须分别指向 null 的左兄弟和右兄弟。
- 记录 ID 必须与它们实际所在的页面匹配。
- 在具有非叶子子节点的节点中,键必须大于左子节点中的任何键,并且小于右子节点中的任何键。
- 在具有叶子子节点的节点中,键必须大于或等于左子节点中的任何键,并且小于或等于右子节点中的任何键。
- 一个节点要么具有全部是非叶子子节点,要么具有全部是叶子子节点。
- 非根节点不能少于半满。
我们在文件BTreeChecker.java中实现了对所有这些属性的机械检查。这种方法还用于在systemtest/BTreeFileDeleteTest.java中测试您的B+树实现。请随时添加对此函数的调用以帮助调试您的实现,就像我们在BTreeFileDeleteTest.java中所做的那样。
Delete
为了保持树的平衡并避免浪费不必要的空间,B+树中的删除操作可能导致页面重新分配元组(图3),或者最终合并(见图4)。您可能会发现复习教材中的第10.6节对此有帮助。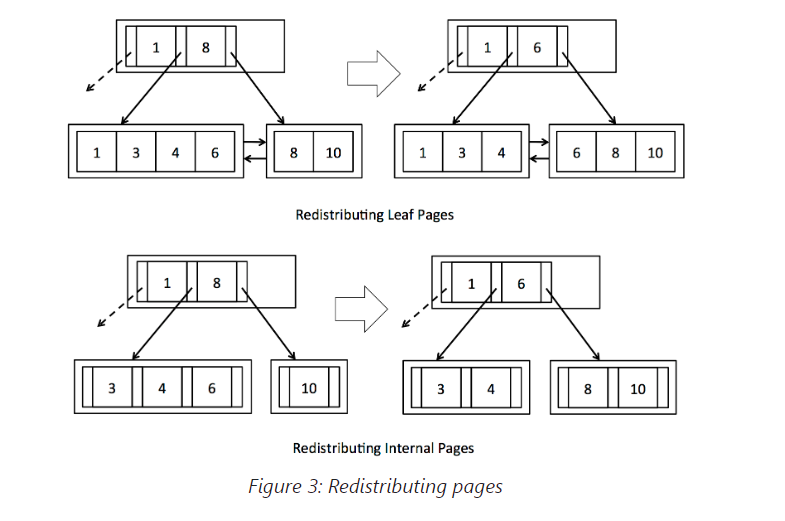
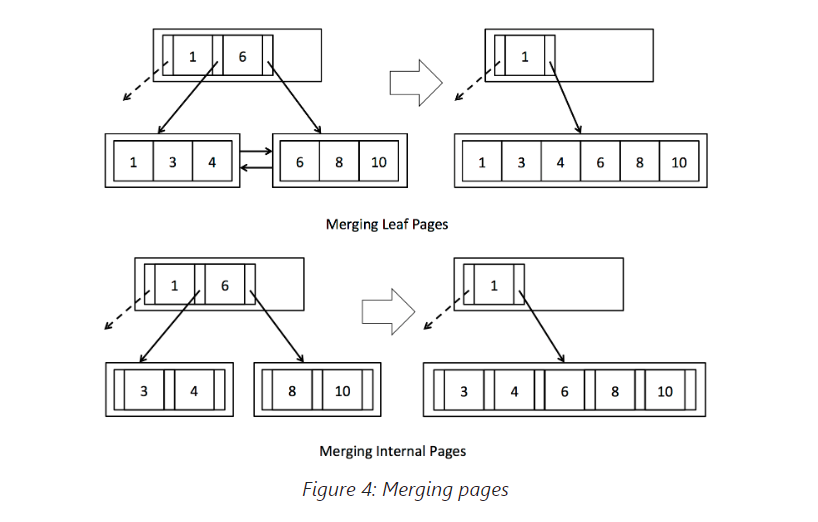
正如教科书所述,尝试从少于半满的叶子页面中删除元组应导致该页面要么从其兄弟那里窃取元组,要么与其兄弟合并。如果页面的某个兄弟有多余的元组,则应在两个页面之间均匀分配这些元组,并相应更新父节点的条目(参见图3)。然而,如果兄弟节点也处于最小占用状态,则这两个页面应合并,并从父节点中删除相应的条目(图4)。反过来,从父节点删除条目可能导致父节点变得少于半满。在这种情况下,父节点应从其兄弟那里窃取条目或与一个兄弟合并。这可能导致递归合并甚至是根节点的删除,如果从根节点删除最后一个条目。
在这个练习中,您将在BTreeFile.java中实现stealFromLeafPage()、stealFromLeftInternalPage()、stealFromRightInternalPage()、mergeLeafPages()和mergeInternalPages()。在前三个函数中,如果兄弟节点有多余的元组/条目,您将实现代码以均匀重新分配元组/条目。记得更新父节点中相应的键字段(仔细查看图3中的操作方式,键实际上通过父节点“旋转”)。在stealFromLeftInternalPage()/stealFromRightInternalPage()中,您还需要更新已移动的子节点的父指针。您应该能够重用updateParentPointers()函数来实现此目的。
在mergeLeafPages()和mergeInternalPages()中,您将实现代码以合并页面,实际上是执行splitLeafPage()和splitInternalPage()的反操作。您会发现deleteParentEntry()函数对于处理所有不同的递归情况非常有用。确保在删除页面时调用setEmptyPage(),以使它们可用于重新使用。与之前的练习一样,我们建议使用BTreeFile.getPage()来封装获取页面的过程,并保持脏页列表的最新状态。
Exercise 3: Redistributing pages
在BTreeFile.java中实现stealFromLeafPage()、stealFromLeftInternalPage()和stealFromRightInternalPage()。
完成此练习后,您应该能够通过BTreeFileDeleteTest.java中的一些单元测试(例如testStealFromLeftLeafPage和testStealFromRightLeafPage)。
系统测试可能需要几秒钟才能完成,因为它们创建了一个大型的B+树,以便充分测试系统。
Exercise 4: Merging pages
在BTreeFile.java中实现mergeLeafPages()和mergeInternalPages()。
现在,您应该能够通过BTreeFileDeleteTest.java中的所有单元测试以及systemtest/BTreeFileDeleteTest.java中的系统测试。
Transactions
你可能还记得,B+树通过使用next-key locking可以防止幻影元组在两次连续的范围扫描之间出现。由于SimpleDB使用基于页面级别的严格两阶段锁定,如果B+树的实现正确,对抗幻影元组的保护就会相对容易实现。因此,在这一点上,你应该能够通过BTreeNextKeyLockingTest。
此外,如果你在B+树代码中正确实现了锁定,你还应该能够通过test/simpledb/BTreeDeadlockTest.java中的测试。
如果一切都正确实现了,你应该能够通过BTreeTest系统测试。我们预计很多人会觉得BTreeTest很困难,因此这不是必需的,但如果有人能够成功运行它,我们将给予额外的学分。请注意,此测试可能需要最多一分钟才能完成。
实现
先明白BTree这几个类的关系。
Debug
在运行systemtest/BTreeFileDeleteTest.java中的系统测试时,发现BufferPool中的一个Bug,修正如下:
1 | // 在删除页面的时候,需要先刷新页面到磁盘,然后在LRU中移除 |
修改之前(错误版)
1 | public synchronized void remove(K key){ |
BTreeTest无法通过,将findLeafPage中做如下修改后:
1 | BTreeInternalPage internalPage = (BTreeInternalPage) getPage(tid, dirtypages, pid, Permissions.READ_ONLY); |
这样偶尔可以通过,猜测是并发插入和删除的时候,脏页丢失了修改。
BTreeTest会启动大量线程同时向B+树中执行插入或删除操作,很可能某个线程执行操作的时候对页面进行了修改,使它变为了脏页。但此时另一个线程也同时在该页进行了修改,导致了更新丢失。
用等待图