Lab 4.ShardKV
Lab 4 - Sharded Key/Value Service
介绍
在本实验中,你将建立一个Key/Value存储系统,将Key “分片 “或分区到一组副本组中。分片是键/值对的一个子集;例如,所有以 “a “开头的键可能是一个分片,所有以 “b “开头的键可能是另一个分片,等等。分片的原因在于性能。每个副本组只处理几个分片的put和get,各组并行运行;因此,系统总吞吐量(单位时间内的put和get)与组的数量成正比增长。
你的Key/Value存储将有两个主要组件。首先是一系列副本组。每个副本组负责一部分分片。一个副本由几个使用 Raft 来复制该组分片的服务器组成。第二个组件是“分片控制器”。分片控制器决定哪个副本组应该服务于哪个分片;这个信息被称为配置。配置会随着时间的推移而变化。客户端询问分片控制器以找到与某个键相关的副本组,而副本组则会咨询控制器以了解应该服务哪些分片。整个系统只有一个分片控制器,通过使用 Raft 实现为一个容错的服务。
一个分片式存储系统必须能够在副本组之间转移分片。一个原因是某些组可能会比其他组的负载更高,因此需要移动分片以平衡负载。另一个原因是副本组可能加入和离开系统:新的副本组可能会被添加以增加容量,或者现有的副本组可能会被下线进行修复或淘汰。
这个实验的主要挑战将是处理重新配置 —— 即分配给副本组的分片发生变化。在单个副本组内,所有组成员必须就何时发生重新配置与客户端 Put/Append/Get 请求达成一致。例如,一个 Put 请求可能与导致副本组不再负责保存 Put 涉及的键的分片的重新配置几乎同时到达。组内的所有副本必须就 Put 请求是在重新配置之前还是之后发生达成一致。如果在之前,Put 请求应该生效,并且分片的新所有者将看到其效果;如果在之后,Put 请求将不会生效,客户端必须在新的所有者处重试。推荐的方法是让每个副本组使用 Raft 记录不仅 Put、Append 和 Get 操作的顺序,还有重新配置的顺序。您需要确保每个分片在任何时候最多只有一个副本组为其服务。
重新配置还需要副本组之间的交互。例如,在配置 10 中,组 G1 可能负责分片 S1。在配置 11 中,组 G2 可能负责分片 S1。在从配置 10 到配置 11 的重新配置期间,G1 和 G2 必须使用 RPC 将分片 S1 的内容(键/值对)从 G1 移动到 G2。
注意:
- 客户端和服务器之间的交互只能使用 RPC。例如,不允许服务器的不同实例共享 Go 变量或文件。
- 本实验室使用 “配置 “来指代将碎片分配到副本组。这与 Raft 群集成员变更不同。您不必实施 Raft 群集成员资格变更。
- Lab 4 分片服务器、Lab 4 分片控制器和 Lab 3 kvraft 都必须使用相同的 Raft 实现。
本实验的总体架构(一个配置服务和一系列副本组)与 Flat Datacenter Storage、BigTable、Spanner、FAWN、Apache HBase、Rosebud、Spinnaker 等系统的总体模式相同。不过,这些系统在很多细节上都与本实验室不同,通常也更加复杂和强大。例如,该实验不会在每个 Raft 组中演化对等集,其数据和查询模型非常简单,分片的切换速度很慢,而且不允许客户端并发访问。
我们会在 src/shardctrler 和 src/shardkv 中为您提供骨架代码和测试。
PartA:The Shard controller
首先,你要在 shardctrler/server.go 和 client.go 中实现分块控制器。完成后,你应该能通过 shardctrler 目录中的所有测试:
1 | go test |
1 | for i in {0..10}; do go test; done |
shardctrler 管理着一系列编号的配置。每个配置描述了一组副本组以及分片到副本组的分配情况。每当这个分配需要改变时,分配控制器就会创建一个新的配置,其中包含了新的分片分配情况。Key/Value客户端和服务器在想要获取当前(或过去)的配置信息时会联系 shardctrler。
你的实现必须支持shardctrler/common.go中描述的RPC接口,其中包括Join、Leave、Move和Query RPC。这些 RPC 的目的是允许管理员(和测试)控制 shardctrler:添加新的副本组、删除副本组,以及在副本组之间移动碎片。
JoinRPC 被管理员用来添加新的副本组。其参数是从唯一、非零副本组标识符(GIDs)到服务器名称列表的映射集。shardctrler应该通过创建一个新的配置来包含新的副本组来做出反应。新的配置应该尽可能均匀地将分片分配给完整的副本组集,并且应该尽可能少地移动分片以达到该目标。如果 GID 不是当前配置的一部分(即 GID 允许加入后离开再次加入),则 shardctrler 应该允许 GID 的重复使用。LeaveRPC 的参数是先前加入的副本组的 GIDs 列表。shardctrler应该创建一个不包含这些组的新配置,并且将这些组的分片分配给剩余的副本组。新的配置应该尽可能均匀地将分片分配给副本组,并且应该尽可能少地移动分片以达到该目标。MoveRPC 的参数是一个分片编号和一个 GID。shardctrler 应该创建一个新的配置,在该配置中将分片分配给该组。Move 的目的是允许我们测试你的软件。在 Move 之后进行 Join 或 Leave 操作可能会撤销 Move 操作,因为 Join 和 Leave 会重新平衡。QueryRPC 的参数是一个配置编号。shardctrler 将回复具有该编号的配置。如果编号为 -1 或大于已知的最大配置编号,则shardctrler应该回复最新的配置。Query(-1)的结果应该反映 shardctrler 在收到 Query(-1) RPC 之前完成处理的每个 Join、Leave 或 Move RPC。
第一个配置应该编号为零。它不包含任何组,所有分片都应分配给 GID 为0的组(无效的 GID)。下一个配置(响应于 Join RPC 创建的)应编号为 1,等等。通常情况下,分片的数量会远远多于组的数量(即每个组会服务多个分片),以便可以在相当精细的粒度上进行负载平衡调整。
你的任务是在 shardctrler/ 目录下的 client.go 和 server.go 中实现上面指定的接口。你的 shardctrler 必须是容错的,使用 Lab 2/3 中的 Raft 库。当你通过了 shardctrler/ 目录中的所有测试后,你就完成了这项任务。
提示:
- 请先从你的 kvraft 服务器的简化版本开始。
- 你应该对分块控制器的 RPC 实现客户端请求的重复检测。
shardctrler测试并不测试这一点,但shardkv测试稍后会在不可靠的网络上使用你的shardctrler;如果你的shardctrler没有过滤掉重复的RPC,你可能很难通过shardkv测试。 - 执行分片重新平衡的状态机中的代码需要是确定性的。在 Go 语言中,map 的迭代顺序是不确定的。
- Go 中的 map 是引用类型。如果你将一个 map 类型的变量赋值给另一个变量,那么两个变量都指向同一个 map。因此,如果你想要基于先前的配置创建一个新的 Config,你需要创建一个新的 map 对象(使用 make()),并逐个复制键和值。
- Go 语言中的竞态检测器(go test -race)可以帮助你找出潜在的 bug。
几个概念:
- replica group:副本组
- shards:分片,只是一个说法,没有实体对象
分片和副本组的关系:一般来说根据Key来划分为不同的分片,参考MapReduce中的做法,可以是Hash(Key)%Nshards来划分,这样不同的Key-Value会被分配到不同的分片上,尽可能存储均匀。
一般副本组负责管理若干个分片,而且每个副本组负责的分片数量均匀(由分片控制器维护)。当收到请求时,Client会根据Key来计算它实际所处的分片号,然后查询Config,向负责该分片的副本组中所有的节点发送RPC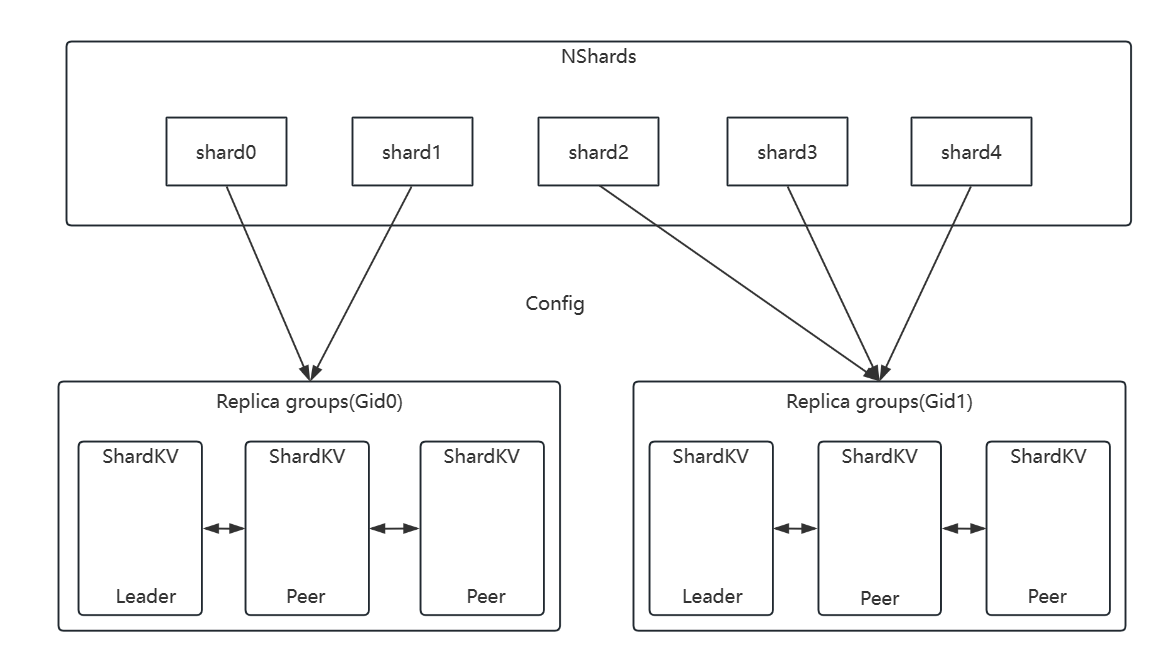
shardctrler维护了当前以及历史的配置Config列表
Config结构:
- num:int 索引号,对应Config切片中的索引。可以通过
config[num]获得指定位置的配置Config - shards:[Nshards]int,分片号->Gid的映射。表示某个分片是由Gid的Grounps那个组负责的。
- groups:map[int] []string,Gid到Servers的映射,记录了Replica group中各个节点是哪些。这样在shardkv发送对于某个分片的请求时,就知道要往哪些负责这个分片节点发送RPC了。
.png)
Client
由于需要保证请求的幂等性,服务端可以通过ClientId和CommandId来唯一标识一次请求。那么就需要在客户端发送请求的时候带上这两个字段。、
ClientId:客户端标识,可以用项目中自带的nrand()函数实现。CommandId:请求标识,来唯一的标识某个客户端发送的请求。可以每次递增。
1 | func MakeClerk(servers []*labrpc.ClientEnd) *Clerk { |
1 | func (ck *Clerk) Move(shard int, gid int) { |
其他的Query,Join,Leave都类似
Server
Server端需要做的就是针对不同的请求来操作分片配置。
Join
1 | func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) { |
Leave
1 | func (sc *ShardCtrler) Leave(args *LeaveArgs, reply *LeaveReply) { |
Move
1 | func (sc *ShardCtrler) Move(args *MoveArgs, reply *MoveReply) { |
Query
1 | func (sc *ShardCtrler) Query(args *QueryArgs, reply *QueryReply) { |
Load Balance
使得每个group管理的shard数量尽可能的接近。
1 | func balance(groups *map[int][]string,shards *[NShards]int) [NShards]int{ |
PartB:Sharded Key/Value Server
现在,你将构建一个分片容错的键/值存储系统–shardkv。你将修改 shardkv/client.go、shardkv/common.go 和 shardkv/server.go。
每个 shardkv 服务器作为副本组的一部分运行。每个副本组为某些键空间分片提供 Get、Put 和 Append 操作。在 client.go 中使用 key2shard() 函数来找出一个键属于哪个分片。多个副本组协同工作以服务完整的分片集合。shardctrler 服务的单个实例负责将分片分配给副本组;当这个分配发生变化时,副本组必须彼此交接分片,同时确保客户端不会看到不一致的响应。
您的存储系统必须为使用其客户端接口的应用程序提供线性化接口。也就是说,在 shardkv/client.go 中的 Clerk.Get()、Clerk.Put() 和 Clerk.Append() 方法完成的应用程序调用必须以相同顺序影响到所有副本。Clerk.Get() 应该能够看到由最近的 Put/Append 写入的相同键的值。即使 Gets 和 Puts 几乎同时到达配置更改,这个要求也必须成立。
您的存储系统必须为使用其客户端接口的应用程序提供线性化接口。也就是说,在 shardkv/client.go 中的 Clerk.Get()、Clerk.Put() 和Clerk.Append() 方法完成的应用程序调用必须以相同顺序影响到所有副本。Clerk.Get() 应该能够看到由最近的 Put/Append 写入的相同键的值。即使 Gets 和 Puts 几乎同时和配置更改一起到达,这个要求也必须成立。
每个分片只需要在该分片的 Raft 副本组中的大多数服务器是活动的、能够相互通信,并且能够与 shardctrler 服务器的大多数通信时才能取得进展。即使某些副本组中的少数服务器已经停止、暂时不可用或速度较慢,您的实现也必须运行(处理请求并在需要时重新配置)。
shardkv服务器只是一个单独副本组的成员。给定副本组中的服务器集合将永远不会改变。
我们提供了 client.go 代码,它会将每个 RPC 发送到负责处理该 RPC 键的副本组。如果副本组表示不负责该键,则客户端代码将进行重试;在这种情况下,客户端代码会向 shard 控制器请求最新的配置,然后再次尝试。您需要修改 client.go 以支持处理重复客户端 RPC,类似 kvraft 实验中的处理方式。
完成后,你的代码应能通过除挑战测试外的所有 shardkv 测试:
1 | $ cd ~/6.824/src/shardkv |
请注意:服务器不应调用分片控制器的 Join() 处理程序。测试器会在适当的时候调用 Join()。
任务一:
您的第一个任务是通过最初的 shardkv 测试。在这个测试中,只有一个分片的分配,因此您的代码应该与第三次实验(Lab 3)中的服务器代码非常相似。最大的修改将是让您的服务器检测配置变化,并开始接受那些与它现在拥有的分片匹配的键的请求。
现在您的解决方案已经适用于静态分片情况,现在是时候解决配置更改的问题了。您需要让服务器监视配置更改,一旦检测到变化,就开始分片迁移过程。如果一个副本组失去了一个分片,它必须立即停止为该分片中的键提供服务,并开始将该分片的数据迁移到接管所有权的副本组。如果一个副本组获得了一个分片,它需要等待前一所有者将旧分片数据发送过来,然后才能接受该分片的请求。
在配置更改期间实施分片迁移非常关键。确保副本组中的所有服务器在执行操作序列时同时进行迁移,这样它们就可以一致地接受或拒绝并发客户端的请求。在处理后续测试之前,着重通过第二个测试(”join then leave”)非常重要。只有通过 TestDelete 之前(不包括 TestDelete)的所有测试,您才能完成这项任务。
注意:
- 你的服务器需要定期轮询分片服务器以了解新的配置。测试希望你的代码大约每 100 毫秒轮询一次;频率高一些没问题,但频率低一些可能会导致问题。
- 在配置更改期间,服务器需要相互发送RPC以在分片迁移过程中传输分片。shardctrler 的 Config 结构包含服务器名称,但您需要一个 labrpc.ClientEnd 来发送 RPC。您应该使用传递给 StartServer() 的 make_end() 函数,将服务器名称转换为 ClientEnd。shardkv/client.go 包含执行此操作的代码。
提示:
- 在
server.go中添加代码,以便定期从分片控制器那里获取最新配置,并添加代码,以便在接收组不负责客户端key的分片时拒绝客户端请求。你应该可以通过第一个测试。 - 服务器在处理客户端RPC时,如果收到的key不是服务器负责的(即键的分片未分配给服务器的组),应该用
ErrWrongGroup错误来响应。确保在并发重新配置的情况下,您的Get、Put和Append处理程序能够正确做出这个决定。 - 按顺序逐个处理重新配置。
- 如果测试失败,请检查是否有 gob 错误(例如 “gob: type not registered for interface …”)。尽管对于 Go 来说,gob 错误不被视为致命错误,但在本实验中它们是致命的。
- 您需要为跨分片移动的客户端请求提供至多一次语义(重复检测)。
- 想一想 shardkv 客户端和服务器应该如何处理
ErrWrongGroup。如果客户端收到ErrWrongGroup,是否应该更改序列号?如果服务器在执行Get/Put请求时返回ErrWrongGroup,是否应该更新客户端状态? - 在服务器已经移动到新配置之后,它可以继续存储它不再拥有的分片(尽管在实际系统中这可能不是理想的)。这可能有助于简化服务器的实现。
- 当组 G1 在配置更改期间需要从 G2 获取分片时,G2 在处理日志条目时何时将分片发送给 G1 是否重要?
- 您可以在 RPC 请求或回复中发送整个 map,这可能有助于使分片传输的代码简单化。
- 如果您的某个 RPC 处理程序在回复中包含了服务器状态的某个 map(例如键/值 map),可能会出现由于竞争而导致的 bug。RPC 系统需要读取 map 来将其发送给调用者,但它并没有持有该 map 的锁。然而,服务器可能在 RPC 系统读取 map 时继续修改同一个 map。解决方案是让 RPC 处理程序在回复中包含 map 的副本。
- 如果您将 map 或 slice 放入 Raft 日志条目中,并且您的键/值服务器随后在 applyCh 上看到该条目并将 map/slice 的引用保存在键/值服务器的状态中,那么可能会出现竞争。请复制 map/slice,并将副本存储在键/值服务器的状态中。竞争发生在键/值服务器修改 map/slice 时以及 Raft 在持久化其日志时读取 map/slice 之间。
- 在配置更改期间,两个组之间可能需要在彼此之间双向移动分片。如果出现死锁,请考虑这个可能是一个源头。
额外挑战
如果要建立这样一个用于生产的系统,这两个功能是必不可少的。
状态的垃圾收集
当副本组失去对一个分片的所有权时,该副本组应该从其数据库中删除与该分片相关的键,因为它不再为该分片提供服务。然而,这对于迁移会带来一些问题。假设有两个组,G1和G2,并且有一个新的配置C,将分片S从G1移动到G2。如果G1在切换到C时从其数据库中清除了分片S中的所有键,那么当G2尝试切换到C时,它该如何获取分片S的数据呢?
导致每个副本组保留旧分片的时间不要超过绝对必要的时间。即使像上面的副本组G1中的所有服务器都崩溃然后重新启动,您的解决方案也必须能够正常工作。只要通过了TestChallenge1Delete测试,您就已经完成了这项任务。
配置更改期间的客户请求
处理配置更改的最简单方法是在转换完成之前禁止所有客户端操作。虽然在概念上简单,但这种方法在生产级系统中并不可行;每当机器进入或退出时,它会导致所有客户端的长时间暂停。最好的做法是继续为未受正在进行的配置更改影响的分片提供服务。
修改您的解决方案,使对未受影响的分块中的键的客户端操作在配置更改期间继续执行。通过 TestChallenge2Unaffected 时,您就完成了这项挑战。
虽然上述优化很好,但我们仍然可以做得更好。假设某个副本组 G3 在转换到 C 时需要来自 G1 的分片 S1,以及来自 G2 的分片 S2。我们真正希望的是,一旦 G3 接收到必要的状态,即使它仍在等待其他分片,也能立即开始为该分片提供服务。例如,如果 G1 宕机,那么一旦 G3 从 G2 接收到了来自 S2 的适当数据,它应该立即开始为 S2 处理请求,尽管转换到 C 尚未完成。
修改您的解决方案,使复制组在能够为分片提供服务时立即开始服务,即使配置仍在进行中。通过 TestChallenge2Partial 时,您就完成了这项挑战。
实现思路
1.需要实现定期轮询分片服务器获取最新config。由Leader进行,然后通过提交日志更新到其他节点。
使用一个后台goroutine实现,每隔50ms查询一次。
2.添加函数实现判断当前的key是否是自己负责的。
3.添加服务器之间进行map交换的代码
这里可能需要进行注册gob
4.map或slice一定要使用深拷贝。
5.快照等其他实现,只需要保留服务器的一些额外状态即可。
6.添加检测config是否改变的代码。比对configNum即可。
基本实现
可以完全按照LAB3的代码,并且实现定期轮询分片服务器更新Config和拒绝不属于当前gid的分片请求即可通过第一个测试。
分片结构
由于TestChallenge2Unaffected和TestChallenge2Partial任务,我们需要对分片进行单独的管理。也就是说某个Group负责的分片与分片之间互不影响。可能其负责的分片1正在从其他组拉取数据,分片2正常,那么它必须能够响应对应分片2的所有请求。
1 | type ShardData struct { |
分片状态机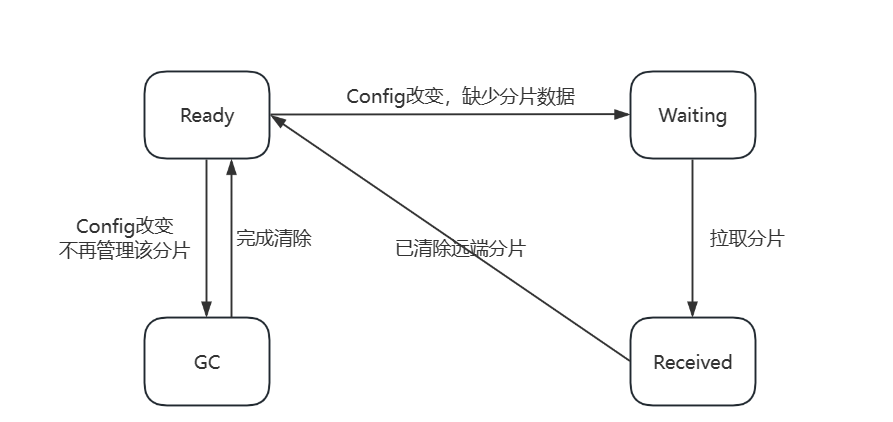
Ready->Waiting:加载新分片配置后,当前group发现自己分配到了新的分片,意味着需要向原来管理该分片的group拉取分片数据。Ready->GC:加载新分片配置后,当前group发现自己不再负责该分片,等待其他group来拉取数据后,进行回收该分片数据。Waiting->Received:向原来管理该分片的group获取到了分片数据,等待向原来group发送GC请求,告诉它已经获取到了数据,可以GC了。Received->Ready:GC请求返回成功,原来group已经成功回收了GC,恢复Ready状态。GC->Ready:不再负责该分片的group,接收到了发来的GC请求,表示对方已获取到分片数据,你可以进行分片回收了,分片回收后,恢复到Ready状态(并情况分片数据)。
配置检测
服务器需要定时拉取最新配置,并更新自己的分片配置信息。同样可以使用后台线程进行监控。
所有服务器的配置只允许逐次更新,不可以跨级更新。比如从config.num=1更新到config.num=3,跳过某些配置。原因是如果在config.num=1时,group管理着该分片,但是在config.num=2时,该分片被其他group管理,假设分片数据在该配置下发送了修改。那么当config.num=3,该分片又恢复到原先的config.num=1时的group管理。如果直接从config.num=1更新到config.num=3,该group无法检测到变化,则就不会从config.num=2的group处拉取分片数据,那么就丢失了config.num=2时该分片的变化。
当所有分片状态都是Ready时,才可以更新配置。否则如果有分片状态如下:
Waiting:意味着该分片还未拉取数据,此时更新配置,会丢失修改。GC:分片数据还未清理,更新配置会产生额外分片垃圾。Received:还未向原来group发送GC请求,那么原先的group无法进行GC,同上。
分片移动
务必清楚
- 某个gid中的分片移动必须先提交日志,等待集群的raft达成一致后,以raft日志的形式去更新,这样才能保证同一集群的状态一致。
- 分片移动的操作由Leader进行还是Follower进行?统一由Leader
- 分片获取的操作是Push还是Pull?都可以,但我认为Pull效率高,仅在必要时拉取自己需要的部分
Leader在更获取最新配置时,需要检测分片管理关系是否发生了变化
Case1:newConfig.Shard[index] == gid && oldConfig.Shard[index] != gid:
那么说明需要从targetGid = oldConfig.Shard[index]处获取shard为index的分片
实现1:group1如何从其他group2中拉取分片信息。这个group之间的RPC如何定义?为了方便起见,直接把整个分片信息传过去就好了,也就是整个map。即KVStateMachine中的KVData,注意深拷贝。
- 定义一个ShardMigration RPC的args和reply
- 定义一个ShardMigrationHandler:来返回其他group需要的分片信息
- 定义一个ShardMigration:从其他Server拉取需要的分片信息
实现2:上述分片移动的过程,是否要阻塞原来的进程。这边感觉是要的,只有拿到最新的分片后,才能继续提供服务。也就是让Leader负责去拿分片,然后通过日志,提交给集群中的其他节点。这样所有节点的分片信息才能保持一致。
更新配置过程:
- 后台线程定期拉取最新配置
- 如果拉取配置的Num比当前的大,说明需要更新了
- 需要拉取分片
- 发送RPC拉取分片
- 提交分片数据到raft
- 更新config
- 不需要拉取分片,提交config到raft即可。
- 需要拉取分片
实现3:定义两种command,用来提交给raft。一个是更新config。一个是更新分片KV数据
实现4:思考先更新Config还是等待Shard移动完毕后,再更新Config
先更新Config,再检查是否需要拉取分片数据,
重新定义状态机结构,这样就不必把整个分片数据都传过去。只传递对应Shard的ShardData。
1 | map[int] ShardData // shard -> ShardData |
checkConfig后台线程:每50ms拉取最新配置
1 | // 1.如果当前配置已经是最新,直接返回 |
updateShardData后台线程:定期刷新分片数据,这个感觉的用nodify机制
1 | // 不断检查ShardData的状态 |
applier后台线程:处理Raft应用到状态机命令
1 | // 收到快照或其他消息,这边先不讨论 |
分片回收
Debug
无法通过
TestConcurrent以及TestUnreliable的所有子测试。似乎put操作有缺失
分片拉取的时候没有判断是否是leader,只有leader才能发送分片数据给其他节点。大部分是没有进行幂等性设计,导致重复执行了某个非幂等操作。空指针异常/无效地址
某个节点进行了Append操作,但是后来又收到了分片数据,覆盖了整个Append操作。导致修改丢失了。
接收分片的时候没有进行幂等性设计,导致如果第一次接收后,分片已经Ready了,此时进行了Append操作,然后又收到了一次接受分片的信息,那么这个Append操作就被覆盖了。configNum一定要逐次加1,这个思考一下为什么。TestConcurrent3无法推进
原因如out日志,27119行-27227行左右。各组之间不断相互Ask Shard Data导致互相等待。原因是不能仅通过kv.rf.Start(Command)进行修改,而是等确保Command一定被执行后再返回ok,因为kv.rf.Start(Command)不是一定执行成功的。可能此时Leader掉线了或不是Leader。如果要保证指令执行成功需要通过ApplyCh监听到该指令被应用于状态机才行。
这个问题还是没解决
更新分片状态的时机
1 | func (kv *ShardKV) ShardGCHandler(args *ShardMigrationArgs, reply * ShardMigrationReply){ |
Bug代码如上,考虑到如果GC_SHARD操作没有执行成功,此时RPC返回OK,那么发送请求的Server已经认为目标Server成功删除了分片(实际未成功),此时发送请求的Server修改分片状态。但目标Server的状态还是GC,导致它无法更新Config
参考
8.MIT 6.824 LAB 4B(分布式shard database) - 简书 (jianshu.com)
MIT-6.824-lab4B-2022(万字思路讲解-代码构建)_6.824 lab-CSDN博客
MIT6.824-2021/docs/lab4.md at master · OneSizeFitsQuorum/MIT6.824-2021 (github.com)